
Maison >Périphériques technologiques >IA >Nouveau travail de Bengio et al. : L'attention peut être considérée comme RNN Le nouveau modèle est comparable à Transformer, mais économise beaucoup de mémoire.
Nouveau travail de Bengio et al. : L'attention peut être considérée comme RNN Le nouveau modèle est comparable à Transformer, mais économise beaucoup de mémoire.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-09 16:50:32688parcourir

Adresse du papier : https://arxiv.org/pdf/2405.13956 Titre du papier : Attention en tant que RNN
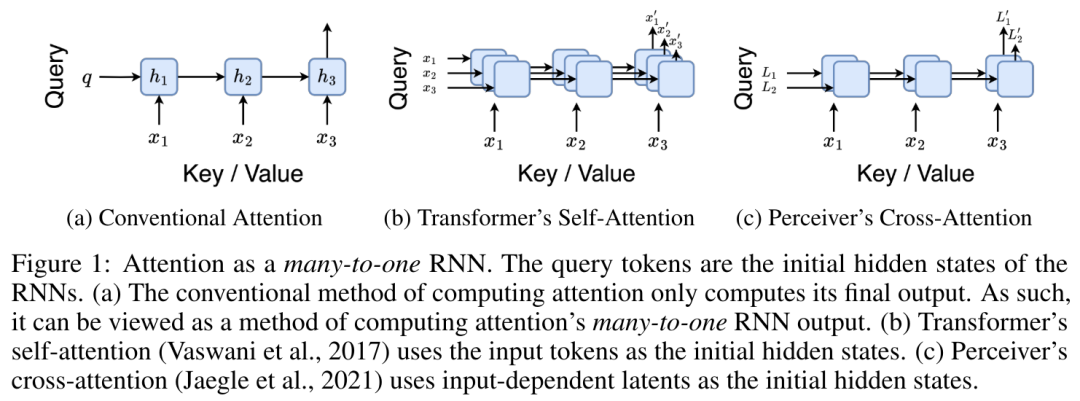
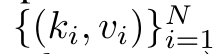 Il correspond à une seule sortie o_N = Attention (q, k_1:N, v_1:N). Étant donné s_i = dot (q, k_i), la sortie o_N peut être exprimée comme suit :
Il correspond à une seule sortie o_N = Attention (q, k_1:N, v_1:N). Étant donné s_i = dot (q, k_i), la sortie o_N peut être exprimée comme suit : 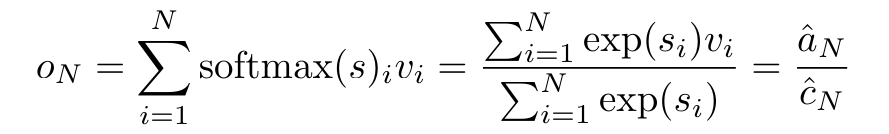
 et le dénominateur est
et le dénominateur est 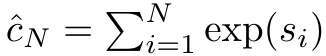 . En considérant l'attention comme un RNN,
. En considérant l'attention comme un RNN, 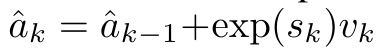 et
et  peuvent être calculés de manière itérative par sommation glissante lorsque k = 1,...,.... En pratique, cependant, cette implémentation est instable et souffre de problèmes numériques dus à une représentation de précision limitée et à des exposants potentiellement très petits ou très grands (c'est-à-dire exp(s)). Afin d'atténuer ce problème, l'auteur utilise le terme maximum cumulé
peuvent être calculés de manière itérative par sommation glissante lorsque k = 1,...,.... En pratique, cependant, cette implémentation est instable et souffre de problèmes numériques dus à une représentation de précision limitée et à des exposants potentiellement très petits ou très grands (c'est-à-dire exp(s)). Afin d'atténuer ce problème, l'auteur utilise le terme maximum cumulé 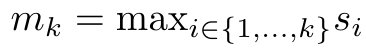 pour réécrire la formule de récursion afin de calculer
pour réécrire la formule de récursion afin de calculer 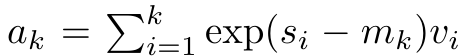 et
et 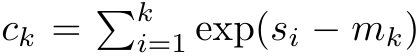 . Il est à noter que le résultat final est le même
. Il est à noter que le résultat final est le même 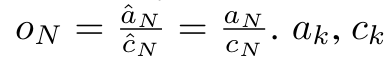 , le calcul de la boucle de m_k est le suivant :
, le calcul de la boucle de m_k est le suivant : 

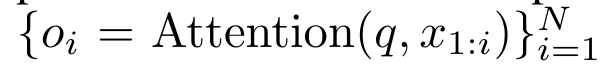 . À cette fin, les auteurs utilisent l'algorithme d'analyse parallèle des préfixes (voir Algorithme 1), une méthode de calcul parallèle qui calcule N préfixes à partir de N points de données consécutifs via l'opérateur de corrélation ⊕.Cet algorithme peut calculer efficacement
. À cette fin, les auteurs utilisent l'algorithme d'analyse parallèle des préfixes (voir Algorithme 1), une méthode de calcul parallèle qui calcule N préfixes à partir de N points de données consécutifs via l'opérateur de corrélation ⊕.Cet algorithme peut calculer efficacement 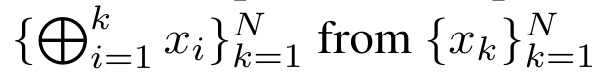

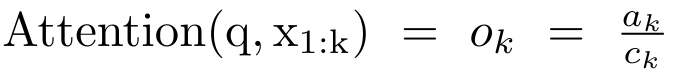 , où
, où 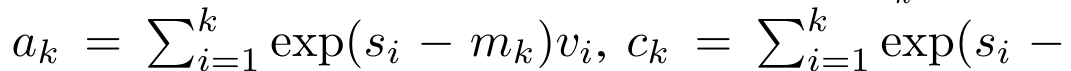
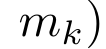 ,
, 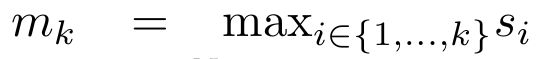 Afin de calculer
Afin de calculer 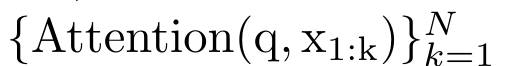 efficacement,
efficacement, 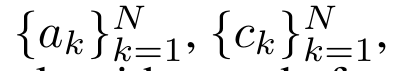 et
et  peuvent être calculés via un algorithme d'analyse parallèle, puis combinés avec a_k et c_k pour calculer
peuvent être calculés via un algorithme d'analyse parallèle, puis combinés avec a_k et c_k pour calculer  . ⊕ ,
. ⊕ ,. L'algorithme applique récursivement l'opérateur ⊕ et fonctionne comme suit :
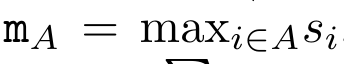 , où
, où 
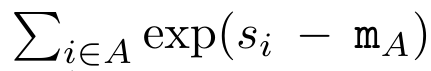 ,
, 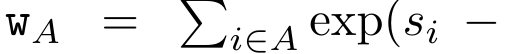
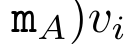 .
. 
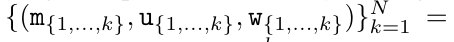
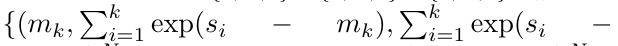
 . Aussi connu sous le nom de
. Aussi connu sous le nom de 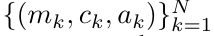 . En combinant les deux dernières valeurs du tuple de sortie,
. En combinant les deux dernières valeurs du tuple de sortie, 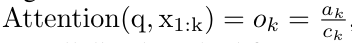 est récupéré, ce qui donne lieu à une méthode parallèle efficace de calcul de l'attention sous la forme d'un RNN plusieurs-à-plusieurs (Figure 3).
est récupéré, ce qui donne lieu à une méthode parallèle efficace de calcul de l'attention sous la forme d'un RNN plusieurs-à-plusieurs (Figure 3). 
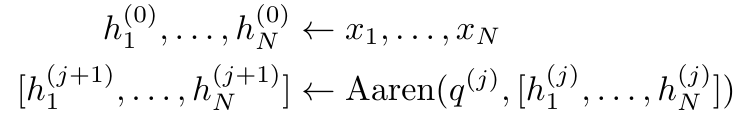
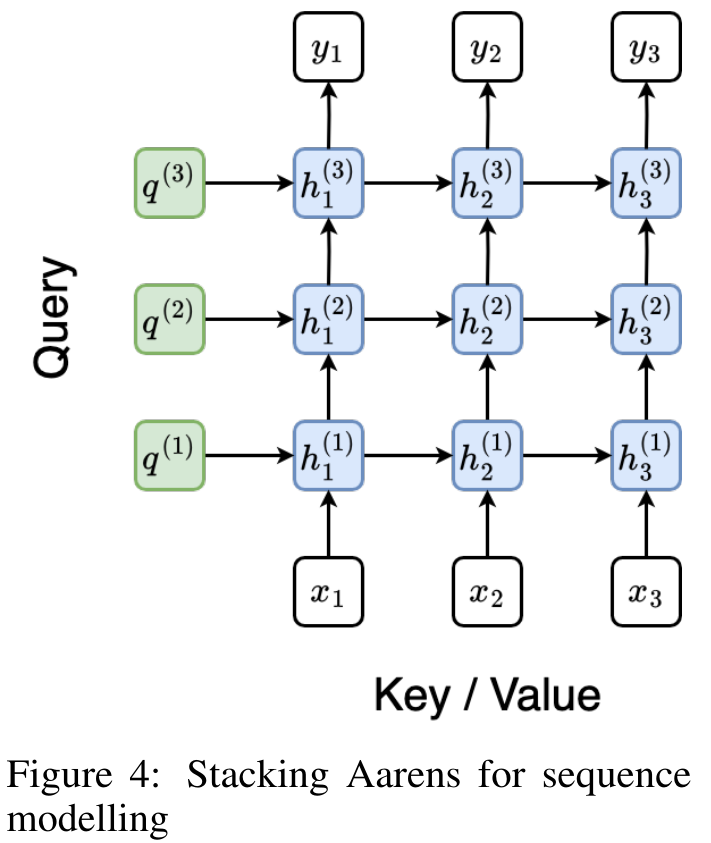

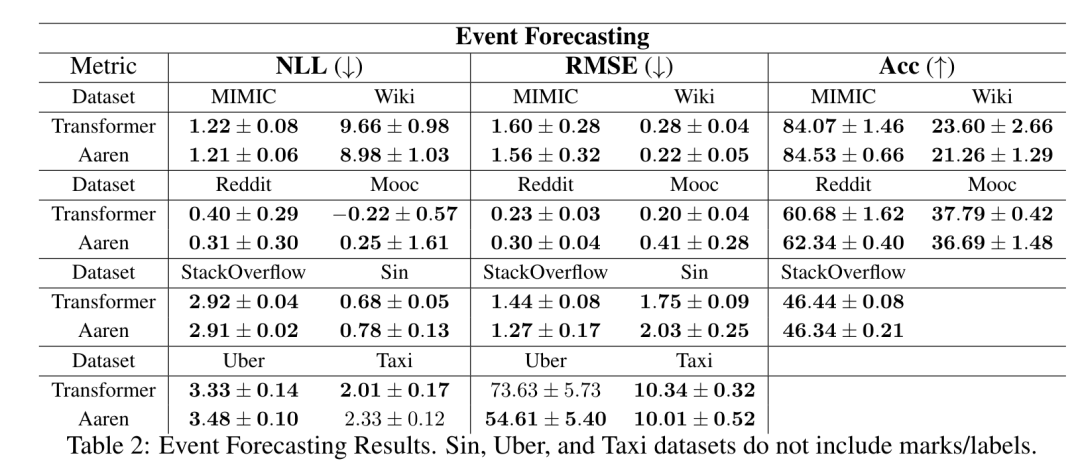
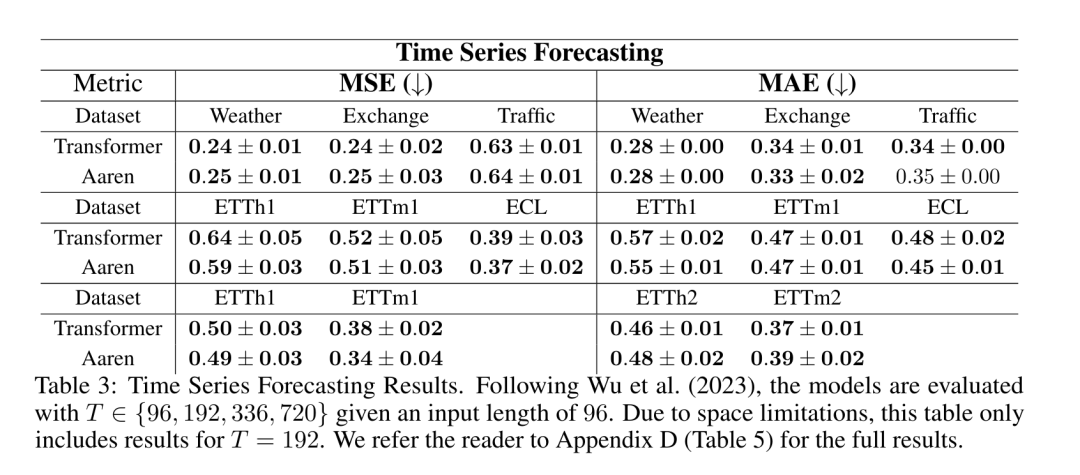
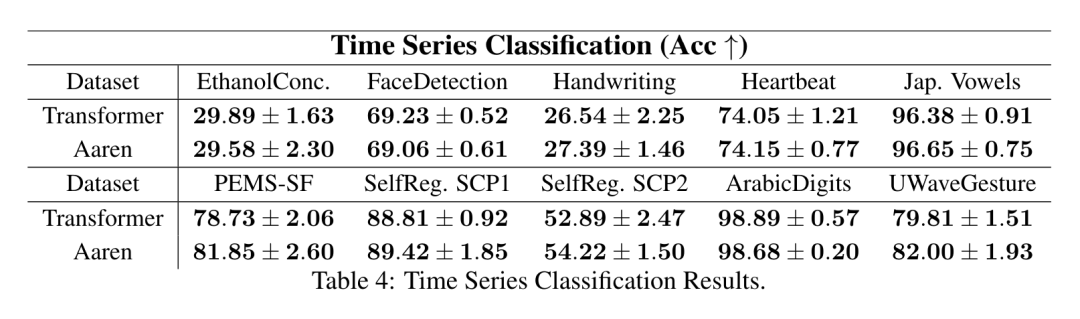
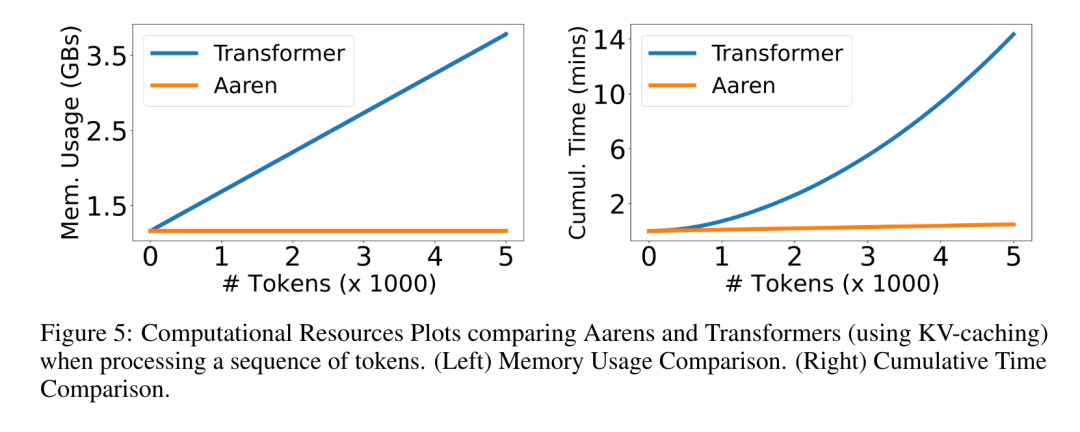
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
Article précédent:Tenant de la gaze et saisissant des aiguilles, NVIDIA coopère avec de nombreuses universités pour développer des robots chirurgicauxArticle suivant:Tenant de la gaze et saisissant des aiguilles, NVIDIA coopère avec de nombreuses universités pour développer des robots chirurgicaux