
Maison >Périphériques technologiques >IA >CVPR\'24 Oral | Un regard sur la vie passée et présente du détecteur de nuages de points purs et clairsemés SAFDNet !
CVPR\'24 Oral | Un regard sur la vie passée et présente du détecteur de nuages de points purs et clairsemés SAFDNet !

- 王林original
- 2024-06-08 12:25:22710parcourir
Écrit à l'avant et compréhension personnelle de l'auteur
La détection d'objets de nuages de points 3D est cruciale pour la perception de la conduite autonome. Comment apprendre efficacement la représentation des caractéristiques à partir de données de nuages de points clairsemées est un défi clé dans le domaine de la détection d'objets de nuages de points 3D. . Dans cet article, nous présenterons le HEDNet publié par l'équipe dans NeurIPS 2023 et SAFDNet dans CVPR 2024. HEDNet se concentre sur la résolution du problème selon lequel les réseaux neuronaux convolutifs clairsemés existants sont difficiles à capturer les dépendances entre les fonctionnalités longue distance, tandis que SAFDNet est construit basé sur HEDNet. Détecteur de nuages de points clairsemés purs. Dans la détection d'objets de nuages de points, les méthodes traditionnelles s'appuient souvent sur des extracteurs de caractéristiques conçus à la main, qui ont une efficacité limitée lors du traitement de données de nuages de points clairsemées. Ces dernières années, les méthodes basées sur le deep learning ont fait des progrès significatifs dans ce domaine. HEDNet utilise des réseaux neuronaux convolutifs pour extraire des fonctionnalités à partir de données de nuages de points clairsemées et résout les problèmes clés liés aux données de nuages de points clairsemés grâce à une structure de réseau spécifique, telle que la capture des dépendances entre les entités longue distance. Cette méthode est dans l'article de NeurIPS 2023
Vie précédente - HEDNet
Contexte de recherche
Les méthodes grand public convertissent généralement les nuages de points non structurés en éléments réguliers et utilisent des réseaux neuronaux convolutifs clairsemés ou des transformateurs pour extraire les fonctionnalités. La plupart des réseaux neuronaux convolutifs clairsemés existants sont principalement construits en empilant des modules résiduels de sous-collecteur (SSR). Chaque module SSR contient deux convolutions de sous-collecteurs utilisant de petits noyaux de convolution (Submanifold Sparse, SS). Cependant, la convolution de sous-variétés nécessite que la rareté des cartes d'entités d'entrée et de sortie reste constante, ce qui empêche le modèle de capturer les dépendances entre les entités distantes. Une solution possible consiste à remplacer la convolution de sous-collecteur dans le module SSR par une convolution régulière clairsemée (RS). Cependant, à mesure que la profondeur du réseau augmente, cela entraîne une diminution de la rareté des cartes de caractéristiques, ce qui entraîne une augmentation substantielle du coût de calcul. Certaines recherches tentent d'utiliser des réseaux neuronaux convolutifs clairsemés ou des transformateurs basés sur de grands noyaux de convolution pour capturer les dépendances entre les caractéristiques longue distance, mais ces méthodes n'apportent pas d'amélioration de la précision ou nécessitent des coûts de calcul plus élevés. En résumé, il nous manque encore une méthode capable de capturer efficacement les dépendances entre fonctionnalités distantes.
Introduction à la méthode
Module SSR et module RSR
Afin d'améliorer l'efficacité du modèle, la plupart des détecteurs d'objets de nuages de points 3D existants utilisent une convolution clairsemée pour extraire des caractéristiques. La convolution clairsemée comprend principalement la convolution RS et la convolution SS. La convolution RS propagera les caractéristiques clairsemées aux zones adjacentes pendant le processus de calcul, réduisant ainsi la rareté de la carte des caractéristiques. En revanche, la convolution SS maintient inchangée la rareté des cartes de caractéristiques d'entrée et de sortie. En raison du coût de calcul de la convolution RS en réduisant la rareté des cartes de caractéristiques, la convolution RS n'est généralement utilisée que pour le sous-échantillonnage des cartes de caractéristiques dans les méthodes existantes. D'un autre côté, la plupart des méthodes basées sur les éléments construisent des réseaux neuronaux convolutifs clairsemés en empilant des modules SSR pour extraire les caractéristiques des nuages de points. Chaque module SSR contient deux convolutions SS et une connexion sautée qui fusionne les fonctionnalités d'entrée et de sortie.
La figure 1(a) montre la structure d'un seul module SSR. La caractéristique valide dans la figure fait référence à la caractéristique non nulle, tandis que la valeur de la caractéristique vide est nulle, ce qui signifie que la position ne contient pas à l'origine de nuage de points. Nous définissons la parsité d'une carte de caractéristiques comme le rapport entre la surface occupée par les entités vides et la superficie totale de la carte de caractéristiques. Dans le module SSR, la carte des fonctionnalités d'entrée est convertie par deux convolutions SS pour obtenir la carte des fonctionnalités de sortie. Dans le même temps, les informations de la carte des fonctionnalités d'entrée sont directement intégrées dans la carte des fonctionnalités de sortie via une connexion sautée (Skip conn.) . La convolution SS traite uniquement les fonctionnalités valides pour garantir que la carte des fonctionnalités de sortie du module SSR a la même parcimonie que la carte des fonctionnalités d'entrée. Cependant, une telle conception entrave l’interaction des informations entre des fonctionnalités déconnectées. Par exemple, les points caractéristiques marqués par des astérisques dans la carte des caractéristiques supérieure ne peuvent pas recevoir d'informations des trois points caractéristiques marqués par des triangles rouges en dehors du cadre en pointillés rouges dans la carte des caractéristiques inférieure, ce qui limite la capacité du modèle à modéliser les dépendances entre les entités longue distance. . Capacité.
 Figure 1 Comparaison structurelle des modules SSR, RSR et SED
Figure 1 Comparaison structurelle des modules SSR, RSR et SED
Au vu des problèmes ci-dessus, une solution possible consiste à remplacer la convolution SS dans le module SSR par une convolution RS pour capturer la dépendance entre les fonctionnalités longue distance. Nous appelons ce module modifié le module Regular Sparse Residual (RSR), et sa structure est illustrée à la figure 1 (b). Dans la figure, la fonctionnalité développée est une fonctionnalité vide située à proximité des fonctionnalités valides. La convolution RS traite à la fois les caractéristiques efficaces et les caractéristiques à diffuser, et son centre de noyau de convolution traverse ces zones de caractéristiques. Cette conception entraîne une plus faible parcimonie dans l'image des caractéristiques de sortie. La convolution RS empilée réduira plus rapidement la rareté de la carte des caractéristiques, ce qui entraînera une réduction significative de l'efficacité du modèle. C'est également la raison pour laquelle les méthodes existantes utilisent généralement la convolution RS pour le sous-échantillonnage des fonctionnalités. Ici, il est plus approprié pour nous de traduire des fonctionnalités étendues en fonctionnalités à diffuser.
Module SED et module DED
L'objectif de conception du module SED est de surmonter les limitations du module SSR. Le module SED raccourcit la distance spatiale entre les entités distantes grâce au sous-échantillonnage des fonctionnalités, et restaure en même temps les informations détaillées perdues grâce à la fusion de fonctionnalités multi-échelles. La figure 1 (c) montre un exemple de module SED avec deux échelles de fonctionnalités. Ce module utilise d'abord une convolution RS 3x3 avec une foulée de 3 pour le sous-échantillonnage des fonctionnalités (Down). Après le sous-échantillonnage des fonctionnalités, les fonctionnalités effectives déconnectées de la carte de fonctionnalités inférieure sont intégrées dans la carte de fonctionnalités du milieu et les fonctionnalités effectives adjacentes. Ensuite, l'interaction entre les fonctionnalités effectives est obtenue en utilisant un module SSR pour extraire les fonctionnalités sur la carte de fonctionnalités intermédiaire. Enfin, les cartes de fonctionnalités intermédiaires sont suréchantillonnées (UP) pour correspondre à la résolution des cartes de fonctionnalités d'entrée. Il convient de noter qu'ici, seuls les exemples d'entités sont suréchantillonnés dans les régions correspondant aux entités valides dans la carte des entités en entrée. Par conséquent, le module SED peut maintenir la rareté des cartes de fonctionnalités. L'objectif de conception du module SED est de surmonter les limitations du module SSR. Le module SED raccourcit la distance spatiale entre les entités distantes grâce au sous-échantillonnage des fonctionnalités, et restaure en même temps les informations détaillées perdues grâce à la fusion de fonctionnalités multi-échelles. La figure 1 (c) montre un exemple de module SED avec deux échelles de fonctionnalités. Ce module utilise d'abord une convolution RS 3x3 avec une foulée de 3 pour le sous-échantillonnage des fonctionnalités (Down). Après le sous-échantillonnage des fonctionnalités, les fonctionnalités effectives déconnectées de la carte de fonctionnalités inférieure sont intégrées dans la carte de fonctionnalités du milieu et les fonctionnalités effectives adjacentes. Ensuite, l'interaction entre les fonctionnalités effectives est obtenue en utilisant un module SSR pour extraire les fonctionnalités sur la carte de fonctionnalités intermédiaire. Enfin, les cartes de fonctionnalités intermédiaires sont suréchantillonnées (UP) pour correspondre à la résolution des cartes de fonctionnalités d'entrée. Il convient de noter qu'ici, seuls les exemples d'entités sont suréchantillonnés dans les régions correspondant aux entités valides dans la carte des entités en entrée. Par conséquent, le module SED peut maintenir la rareté des cartes de fonctionnalités. L'objectif de conception du module SED est de surmonter les limitations du module SSR. Le module SED montre une implémentation spécifique du module SED avec trois échelles caractéristiques. Le nombre entre parenthèses représente le rapport entre la résolution de la carte de fonctionnalités correspondante et la résolution de la carte de fonctionnalités d'entrée. Le module SED adopte une structure de codec asymétrique, qui utilise l'encodeur pour extraire des fonctionnalités multi-échelles et fusionne progressivement les fonctionnalités multi-échelles extraites via le décodeur. Le module SED utilise la convolution RS comme couche de sous-échantillonnage de fonctionnalités et la déconvolution clairsemée comme couche de suréchantillonnage de fonctionnalités. En utilisant la structure codeur-décodeur, le module SED facilite l'interaction des informations entre les entités déconnectées dans l'espace, permettant ainsi au modèle de capturer les dépendances entre les entités distantes.
Figure 2 Structures des modules SED et DED D'un autre côté, les détecteurs de nuages de points 3D traditionnels actuels s'appuient principalement sur les caractéristiques du centre de l'objet pour la prédiction, mais dans la carte des caractéristiques extraite par le réseau convolutionnel clairsemé, la zone du centre de l'objet peut exister Des trous, surtout dans les gros objets. Pour résoudre ce problème, nous proposons le module DED, dont la structure est représentée sur la figure 2(b). Le module DED a la même structure que le module SED, il remplace le module SSR dans le module SED par un module Dense Residual (DR), et remplace la convolution RS utilisée pour le sous-échantillonnage des fonctionnalités avec DR par un module foulée de 2 et remplace le module clairsemé. déconvolution pour le suréchantillonnage de fonctionnalités avec déconvolution dense. Ces conceptions permettent au module DED de diffuser efficacement des caractéristiques clairsemées vers la zone centrale de l'objet.
D'un autre côté, les détecteurs de nuages de points 3D traditionnels actuels s'appuient principalement sur les caractéristiques du centre de l'objet pour la prédiction, mais dans la carte des caractéristiques extraite par le réseau convolutionnel clairsemé, la zone du centre de l'objet peut exister Des trous, surtout dans les gros objets. Pour résoudre ce problème, nous proposons le module DED, dont la structure est représentée sur la figure 2(b). Le module DED a la même structure que le module SED, il remplace le module SSR dans le module SED par un module Dense Residual (DR), et remplace la convolution RS utilisée pour le sous-échantillonnage des fonctionnalités avec DR par un module foulée de 2 et remplace le module clairsemé. déconvolution pour le suréchantillonnage de fonctionnalités avec déconvolution dense. Ces conceptions permettent au module DED de diffuser efficacement des caractéristiques clairsemées vers la zone centrale de l'objet.
Basé sur le module SED et le module DED, nous proposons le réseau de codecs hiérarchiques HEDNet. Comme le montre la figure 3, HEDNet extrait les caractéristiques clairsemées de haut niveau via un réseau fédérateur clairsemé 3D, puis diffuse les caractéristiques clairsemées vers la zone centrale de l'objet via un réseau fédérateur dense 2D, et enfin envoie les caractéristiques produites par le 2D. réseau fédérateur dense à la tête de détection pour la prédiction des tâches. Pour faciliter la présentation, la carte des caractéristiques et la couche de sous-échantillonnage des caractéristiques ultérieure sont omises dans la figure. Macroscopiquement, HEDNet adopte une structure de réseau hiérarchique similaire à SECOND, et la résolution de ses cartes de fonctionnalités diminue progressivement ; au microscope, les composants principaux de HEDNet, le module SED et le module DED, adoptent tous deux une structure de codec. C'est de là que vient le nom HEDNet.
Figure 3 Cadre global HEDNet
Pourquoi pensons-nous à utiliser la structure des codecs ? En fait, HEDNet s'est inspiré de notre travail précédent CEDNet : A Cascade Encoder-Decoder Network for Dense Prediction (appelé CFNet avant que le nom ne soit modifié). Si vous êtes intéressé, vous pouvez lire notre article.
Résultats expérimentauxNous avons comparé les performances globales de HEDNet avec les méthodes de pointe précédentes, et les résultats sont présentés dans la figure 4. Comparé à LargeKernel3D basé sur le grand noyau de convolution CNN et DSVT-Voxel basé sur Transformer, HEDNet obtient de meilleurs résultats en termes de précision de détection et de vitesse d'inférence du modèle. Il convient de mentionner que par rapport à la méthode de pointe DSVT précédente, HEDNet atteint une précision de détection plus élevée et augmente la vitesse d'inférence du modèle de 50 %. Des résultats plus détaillés peuvent être trouvés dans notre article.
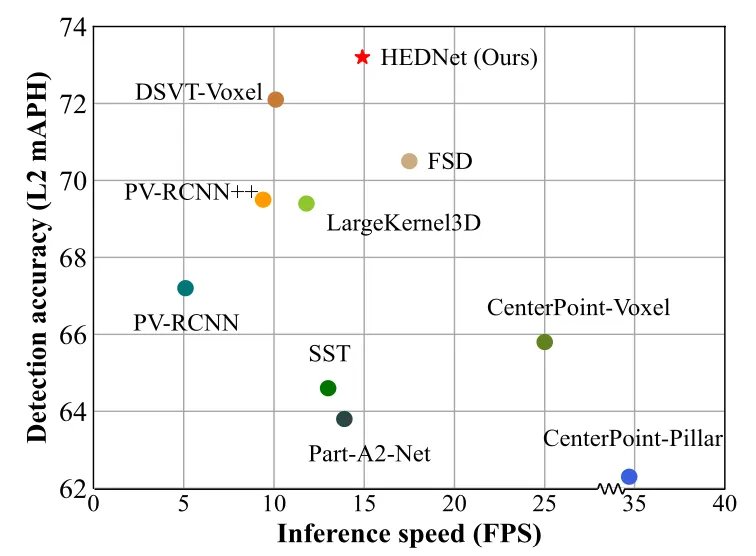
Figure 4 Comparaison complète des performances sur l'ensemble de données Waymo Open
Cette vie - SAFDNet
Contexte de recherche
Les méthodes basées sur les voxels convertissent généralement les caractéristiques de voxels clairsemées en cartes de caractéristiques denses, puis transmettent des neurones convolutifs denses les réseaux extraient des fonctionnalités à des fins de prédiction. Nous appelons ce type de détecteur un détecteur hybride, et sa structure est illustrée à la figure 5(a). Ce type de méthode fonctionne bien dans les scénarios de détection à petite portée (<75 mètres), mais à mesure que la portée de détection s'étend, le coût de calcul lié à l'utilisation de cartes de caractéristiques denses augmente considérablement, limitant leur utilisation à grande portée (> 200 mètres). Scénarios de détection. Une solution possible consiste à construire un détecteur clairsemé pur en supprimant les cartes de caractéristiques denses dans les détecteurs hybrides existants, mais cela entraînera une dégradation significative des performances de détection du modèle, car la plupart des détecteurs hybrides reposent actuellement sur des centres d'objets. utilisé pour la prédiction. Lorsque vous utilisez des détecteurs clairsemés purs pour extraire des caractéristiques, la zone centrale des gros objets est généralement vide. C'est le problème de caractéristique du centre d'objet manquant. Par conséquent, l’apprentissage des représentations d’objets appropriées est crucial pour construire des détecteurs purement clairsemés.

Figure 5 Comparaison structurelle du détecteur hybride, FSDv1 et SAFDNet
Afin de résoudre le problème des caractéristiques manquantes du centre de l'objet, FSDv1 (Figure 5(b)) divise d'abord le nuage de points d'origine en points de premier plan et points d'arrière-plan , puis via Le mécanisme de vote du point central regroupe les points de premier plan et extrait les caractéristiques d'instance de chaque cluster pour une prédiction initiale, qui est ensuite affinée via le responsable de correction de groupe. Afin de réduire le biais inductif introduit par l'extraction manuelle des caractéristiques de l'instance, FSDv2 utilise un module de voxélisation virtuelle pour remplacer l'opération de clustering d'instance dans FSDv1. La série de méthodes FSD est assez différente des frameworks de détection largement utilisés tels que CenterPoint et introduit un grand nombre d'hyperparamètres, ce qui rend difficile le déploiement de ces méthodes dans des scénarios réels. Différent de la série de méthodes FSD, VoxelNeXt prédit directement en fonction des caractéristiques du voxel les plus proches du centre de l'objet, mais sacrifie la précision de la détection.
Alors, à quoi ressemble le détecteur de nuages de points purs et clairsemés que nous voulons ? Premièrement, la structure doit être simple, afin qu'elle puisse être directement déployée dans des applications pratiques. Une idée intuitive est d'apporter des modifications minimes pour construire un détecteur clairsemé pur basé sur l'architecture de détecteur hybride actuellement largement utilisée telle que CenterPoint. de performance Il doit au moins correspondre aux principaux détecteurs hybrides actuels et être applicable à différentes gammes de scénarios de détection.
Introduction à la méthode
À partir des deux exigences ci-dessus, nous avons construit un détecteur d'objets à nuage de points 3D pur et clairsemé SAFDNet basé sur HEDNet, dont la structure macro est illustrée à la figure 5 (c). SAFDNet utilise d'abord un extracteur de caractéristiques de voxel clairsemé pour extraire les caractéristiques de nuage de points clairsemées, puis utilise une stratégie de diffusion adaptative de caractéristiques (AFD) et un réseau neuronal convolutionnel clairsemé 2D pour diffuser les caractéristiques clairsemées vers la zone centrale de l'objet pour résoudre le problème. problème du centre de l'objet. Problème de fonctionnalités manquantes, et enfin prédiction basée sur des fonctionnalités de voxel clairsemées. SAFDNet peut effectuer des calculs efficaces en utilisant uniquement des fonctionnalités éparses, et la plupart de sa conception structurelle et de ses hyperparamètres sont cohérents avec les détecteurs hybrides de base, ce qui facilite l'adaptation aux scénarios d'application réels pour remplacer les détecteurs hybrides existants. La structure spécifique de SAFDNet est présentée ci-dessous.
Cadre global de SAFDNet
La figure 6 montre le cadre global de SAFDNet. Semblable aux détecteurs hybrides existants, SAFDNet se compose principalement de trois parties : un réseau fédérateur clairsemé 3D, un réseau fédérateur clairsemé 2D et une tête de détection clairsemée. Le réseau fédérateur clairsemé 3D est utilisé pour extraire des caractéristiques de voxel clairsemées 3D et convertir ces caractéristiques en caractéristiques BEV clairsemées 2D. Le réseau fédérateur clairsemé 3D utilise le module 3D-EDB pour promouvoir l'interaction d'informations entre les entités longue distance (le module 3D-EDB est le module SED construit sur la base d'une convolution clairsemée 3D, et le module 2D-EDB ci-dessous est similaire). Le réseau fédérateur clairsemé 2D reçoit en entrée les caractéristiques BEV clairsemées émises par le réseau fédérateur clairsemé 3D. Il classe d'abord chaque voxel pour déterminer si le centre géométrique de chaque voxel se situe dans le cadre de délimitation d'objet d'une catégorie spécifique ou s'il appartient à la catégorie spécifique. zone d'arrière-plan. Ensuite, les caractéristiques clairsemées sont diffusées vers la zone centrale de l'objet via l'opération AFD et le module 2D-EDB. Cette partie est le composant principal de SAFDNet. La tête de détection clairsemée effectue des prédictions basées sur les caractéristiques BEV clairsemées produites par le réseau fédérateur clairsemé 2D. SAFDNet adopte la conception de la tête de détection proposée par CenterPoint et nous y avons apporté quelques ajustements pour l'adapter aux fonctionnalités clairsemées. Veuillez consulter le document pour plus de détails.
 Figure 6 Cadre global de SAFDNet
Figure 6 Cadre global de SAFDNet
Diffusion adaptative de caractéristiques (AFD)
Étant donné que le nuage de points généré par lidar est principalement distribué sur la surface de l'objet, l'utilisation d'un détecteur clairsemé pur pour extraire des caractéristiques à des fins de prédiction sera confrontée au problème des caractéristiques manquantes du centre de l'objet. Le détecteur peut-il donc extraire des caractéristiques plus proches ou situées au centre de l'objet tout en conservant autant que possible la rareté des caractéristiques ? Une idée intuitive consiste à répartir les caractéristiques clairsemées dans les voxels voisins. La figure 6 (a) montre un exemple de carte de caractéristiques clairsemées. Le point rouge sur la figure représente le centre de l'objet. Les carrés orange foncé sont des voxels non vides dont les centres géométriques se situent dans le cadre de délimitation. de l'objet. Les carrés bleu foncé sont des voxels non vides dont le centre géométrique se situe en dehors du cadre de délimitation de l'objet, et les carrés blancs sont des voxels vides. Chaque voxel non vide correspond à une caractéristique non vide. La figure 7 (b) est obtenue en diffusant uniformément les caractéristiques non vides de la figure 7 (a) au voisinage de KxK (K est égal à 5). Les voxels non vides diffusés sont affichés en orange clair ou en bleu clair.
 Figure 7 Diagramme schématique de la diffusion uniforme des caractéristiques et de la diffusion adaptative des caractéristiques
Figure 7 Diagramme schématique de la diffusion uniforme des caractéristiques et de la diffusion adaptative des caractéristiques
En analysant la carte des caractéristiques clairsemées produite par le réseau fédérateur clairsemé 3D, nous observons que : (a) moins de 10 % des voxels se trouvent dans la boîte englobante de l'objet ; (b) Les petits objets ont généralement des caractéristiques non nulles à proximité ou sur leur voxel central. Cette observation suggère que la répartition de toutes les caractéristiques non nulles dans le même domaine de taille peut s'avérer inutile, en particulier pour les voxels situés dans des cadres de délimitation de petits objets et dans des régions d'arrière-plan. Par conséquent, nous proposons une stratégie de diffusion de caractéristiques adaptative qui ajuste dynamiquement la plage de diffusion en fonction de l’emplacement des caractéristiques de voxel. Comme le montre la figure 7 (c), cette stratégie rapproche les caractéristiques de voxel dans le cadre de délimitation des grands objets du centre de l'objet en attribuant une plage de diffusion plus large à ces caractéristiques, tout en attribuant en même temps des caractéristiques de voxel dans le cadre de délimitation de les petits objets et dans la zone d'arrière-plan, les entités Voxel se voient attribuer une plage de diffusion plus petite afin de maintenir autant que possible la rareté des caractéristiques. Afin de mettre en œuvre cette stratégie, la classification des voxels (classification Voxel) est nécessaire pour déterminer si le centre géométrique de tout voxel non vide se trouve dans le cadre de délimitation d'une catégorie spécifique d'objets ou appartient à la zone d'arrière-plan. Veuillez vous référer à l'article pour plus de détails sur la classification des voxels. En utilisant une stratégie adaptative de diffusion de caractéristiques, le détecteur est capable de maintenir autant que possible la rareté des caractéristiques, bénéficiant ainsi d'un calcul efficace des caractéristiques clairsemées.
Principaux résultats expérimentaux
Nous avons comparé les performances globales de SAFDNet avec les meilleures méthodes précédentes, et les résultats sont présentés dans la figure 8. Sur l'ensemble de données Waymo Open avec une plage de détection plus petite, SAFDNet a atteint une précision de détection comparable à celle du meilleur détecteur clairsemé pur FSDv2 et de notre détecteur hybride proposé HEDNet, mais la vitesse d'inférence de SAFDNet est 2 fois supérieure à celle de FSDv2 et HEDNet 1,2 fois. Sur l'ensemble de données Argoverse2 avec une large plage de détection, par rapport au détecteur clairsemé pur FSDv2, SAFDNet a amélioré l'indicateur mAP de 2,1 %, et la vitesse d'inférence a atteint 1,3 fois celle de FSDv2 par rapport au détecteur hybride HEDNet, SAFDNet a amélioré l'indicateur ; mAP a augmenté de 2,6 % et la vitesse d'inférence a atteint 2,1 fois celle de HEDNet. De plus, lorsque la plage de détection est large, la consommation mémoire du détecteur hybride HEDNet est bien supérieure à celle du détecteur clairsemé pur. En résumé, SAFDNet convient à différentes gammes de scénarios de détection et offre d'excellentes performances.

Figure 8 Principaux résultats expérimentaux
Travaux futurs
SAFDNet est une solution pour un détecteur de nuages de points clairsemés purs, a-t-il donc des problèmes ? En fait, SAFDNet n'est qu'un produit intermédiaire de notre idée d'un détecteur clairsemé pur. L'auteur estime qu'il est trop violent et pas assez concis et élégant. Attendez-vous à notre travail de suivi !
Les codes de HEDNet et SAFDNet sont open source et tout le monde est invité à les utiliser. Voici le lien : https://github.com/zhanggang001/HEDNet
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Three.js implémente le partage d'instances de carte 3D
- Comment implémenter un mur de photos 3D avec javascript (avec code)
- Puis-je utiliser des lunettes 3D pour regarder des films sur mon téléphone portable ?
- Aider la nouvelle génération de l'ère de la perception de l'IA : Biaobei Technology innove dans la technologie de segmentation des nuages de points 3D
- QTNet : Nouvelle solution de fusion temporelle pour nuages de points, images et détecteurs multimodaux (NeurIPS 2023)