
Maison >Périphériques technologiques >IA >LLM | Yuan 2.0-M32 : modèle de mélange expert avec routage d'attention
LLM | Yuan 2.0-M32 : modèle de mélange expert avec routage d'attention

- PHPzoriginal
- 2024-06-07 09:06:30675parcourir
 Photos
Photos
1. Conclusion écrite devant
Yuan+2.0-M32 est une infrastructure, similaire à Yuan-2.0+2B, utilisant une architecture hybride experte contenant 32 experts. 2 de ces experts sont actifs. Une architecture hybride experte contenant 32 experts est proposée et adoptée pour sélectionner les experts plus efficacement. Par rapport au modèle utilisant le réseau de routage classique, le taux de précision est amélioré de 3,8 %. Yuan+2.0-M32 est formé à partir de zéro, en utilisant 2 000 milliards de jetons, et sa consommation de formation n'est que de 9,25 % de celle d'un modèle d'ensemble dense de même taille de paramètre. Afin de mieux sélectionner les experts, le routeur d'attention est introduit, qui a la capacité de détecter rapidement et ainsi de permettre une meilleure sélection des experts.
Yuan 2.0-M32 a démontré des capacités compétitives dans le codage, les mathématiques et plusieurs domaines professionnels, en utilisant seulement 3,7 milliards de paramètres actifs sur 40 milliards de paramètres totaux et en calculant en avant 7,4 GFlops par jeton. Ces deux indicateurs ne sont que 1/. 19 de Lama3-70B. Yuan 2.0-M32 a surpassé Llama3-70B dans les tests MATH et ARC-Challenge, avec des taux de précision atteignant respectivement 55,89 % et 95,8 %. Le modèle et le code source de Yuan 2.0-M32 sont sur GitHub : https://github.com/IEIT-Yuan/Yuan2.0-M32.
2. Brève introduction du document
2.1 Contexte du document
Dans le cas d'un montant fixe de calcul pour chaque jeton, un modèle utilisant une structure de mélange d'experts (MoE) peut être facile à construire en augmentant le nombre d'experts. Plus grande échelle que les modèles à ensemble dense, ce qui entraîne des performances de précision plus élevées. En fait, lors de la formation de modèles avec des ressources informatiques limitées, le MoE est considéré comme une excellente option pour réduire les coûts associés au modèle, à la taille de l'ensemble de données et à la puissance de calcul limitée.
Le concept de MoE (Mixture of Experts) remonte à 1991. La perte totale est une combinaison des pertes pondérées de chaque expert ayant la capacité de porter des jugements indépendants. Le concept de MoE clairsemé a été initialement proposé par Shazeer et al (2017) dans les modèles de traduction. Grâce à cette stratégie de routage, seuls quelques experts sont activés lorsqu'ils soulèvent des questions, plutôt que tous les experts soient appelés en même temps. Cette rareté permet au modèle d'évoluer jusqu'à 1 000 fois entre les couches LSTM empilées avec une perte minimale d'efficacité de calcul. Le routage de déclenchement Top-K à bruit réglable introduit un bruit réglable dans la fonction softmax du réseau et maintient la valeur K pour équilibrer l'utilisation experte. Ces dernières années, avec l’expansion continue de l’échelle des modèles, les stratégies de routage ont reçu davantage d’attention pour allouer efficacement les ressources informatiques.
Le réseau de routage expert est au cœur de la structure du MoE. Cette structure sélectionne les experts candidats pour participer au calcul en calculant la probabilité d'attribution de jetons à chaque expert. Actuellement, dans les structures MoE les plus populaires, l'algorithme de routage classique est couramment utilisé, qui effectue le produit scalaire entre le jeton et le vecteur de caractéristiques de chaque expert et sélectionne l'expert avec le produit scalaire le plus grand comme gagnant. Dans ce choix, les vecteurs de caractéristiques des experts sont indépendants et la corrélation entre experts est ignorée. Cependant, la structure du ministère de l’Éducation sélectionne généralement plus d’un expert à la fois, et il peut y avoir des corrélations entre les caractéristiques des différents experts. Par conséquent, dans ce cas, les vecteurs de caractéristiques sélectionnés peuvent présenter des chevauchements et des conflits pour les produits scalaires entre chaque expert impliqué dans le calcul, ce qui affecte à son tour la précision des résultats. Cependant, la structure du MoE sélectionne généralement plus d'un expert à la fois, et il peut y avoir des corrélations entre les caractéristiques de différents experts. Par conséquent, dans ce cas, les vecteurs de caractéristiques sélectionnés par l'algorithme de routage classique peuvent se chevaucher et entrer en conflit, affectant le calcul. précision. Pour résoudre ce problème, les structures du MoE adoptent souvent des vecteurs de caractéristiques d’experts indépendants, ce qui signifie que chaque expert est traité comme complètement indépendant, tandis que la corrélation entre experts est ignorée. Cependant, cette approche peut poser certains problèmes. Par conséquent, lors de la sélection des experts, la structure du ministère de l’Éducation sélectionne généralement plusieurs experts, et il peut y avoir des corrélations entre les caractéristiques des différents experts. Dans ce cas, les vecteurs de caractéristiques sélectionnés peuvent présenter des chevauchements et des conflits pour les produits scalaires entre chaque expert impliqué dans le calcul, ce qui affecte à son tour la précision des résultats. Par conséquent, la structure du MoE nécessite un algorithme de routage plus précis pour sélectionner les meilleurs experts, et la sélection doit être prise en compte. Structure du modèle 2B, Yuan 2.0 introduit une attention locale basée sur le filtrage (LFA) pour prendre en compte la dépendance locale des jetons d'entrée, améliorant ainsi la précision du modèle. Dans Yuan 2.0-M32, le réseau dense à action directe (FFN) de chaque couche est remplacé par des composants MoE.
La figure 1 montre l'architecture de la couche MoE appliquée dans le modèle papier. En prenant comme exemple quatre FFN (il y a en réalité 32 experts), chaque couche du MoE se compose d'un FFN indépendant en tant qu'expert. Étant donné que le réseau de chemins experts attribue des jetons d'entrée aux experts concernés, le réseau de chemins classique établit un vecteur de caractéristiques pour chaque expert. Et calculez le produit scalaire entre le jeton d'entrée et chaque vecteur de caractéristiques expert pour obtenir la similarité entre le jeton et chaque expert. L’expert présentant la similarité la plus élevée sera utilisé pour calculer le résultat. L'expert présentant la plus forte similarité est sélectionné pour l'activation et participe aux calculs ultérieurs.
Image 1 Figure 1 : explication de Yuan 2.0-M32. L'image de gauche montre l'expansion de la couche MoE dans l'architecture Yuan 2.0. La couche MoE remplace la couche feedforward dans Yuan 2.0. La figure de droite montre la structure de la couche MoE. Dans le modèle du document, chaque jeton d'entrée sera attribué à 2 experts sur un total de 32, tandis que dans la figure, le document utilise 4 experts comme exemple. Le résultat du MoE est la somme pondérée des experts sélectionnés. N représente le nombre de couches. Les vecteurs de caractéristiques de chaque expert sont indépendants les uns des autres et la corrélation entre experts est ignorée lors du calcul de la probabilité. En fait, dans la plupart des modèles du MoE, deux experts ou plus sont généralement sélectionnés pour participer aux calculs ultérieurs, ce qui entraîne naturellement une forte corrélation entre les experts. La prise en compte des corrélations inter-experts contribue certainement à améliorer la précision.
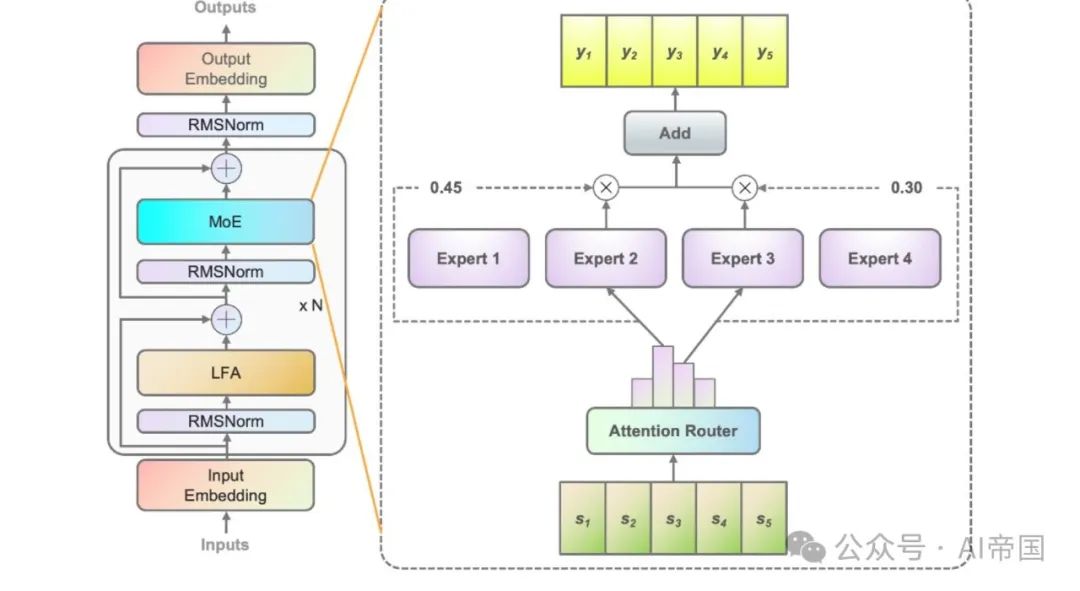 La figure 2(b) montre l'architecture du routeur d'attention proposé dans ce travail. Ce nouveau réseau de routage intègre la corrélation entre experts en adoptant le mécanisme d'attention. Une matrice de coefficients représentant la corrélation entre experts est construite et appliquée dans le calcul de la valeur de probabilité finale.
La figure 2(b) montre l'architecture du routeur d'attention proposé dans ce travail. Ce nouveau réseau de routage intègre la corrélation entre experts en adoptant le mécanisme d'attention. Une matrice de coefficients représentant la corrélation entre experts est construite et appliquée dans le calcul de la valeur de probabilité finale.
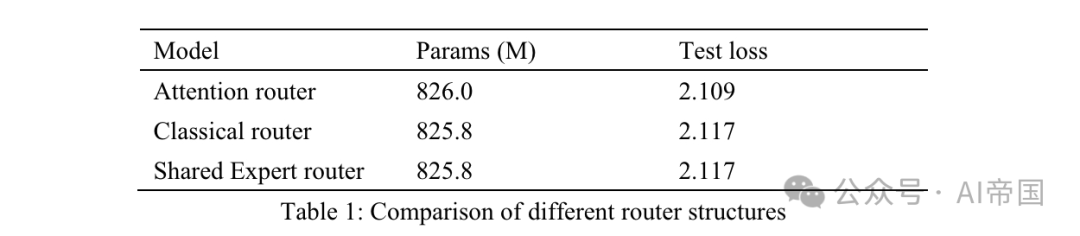
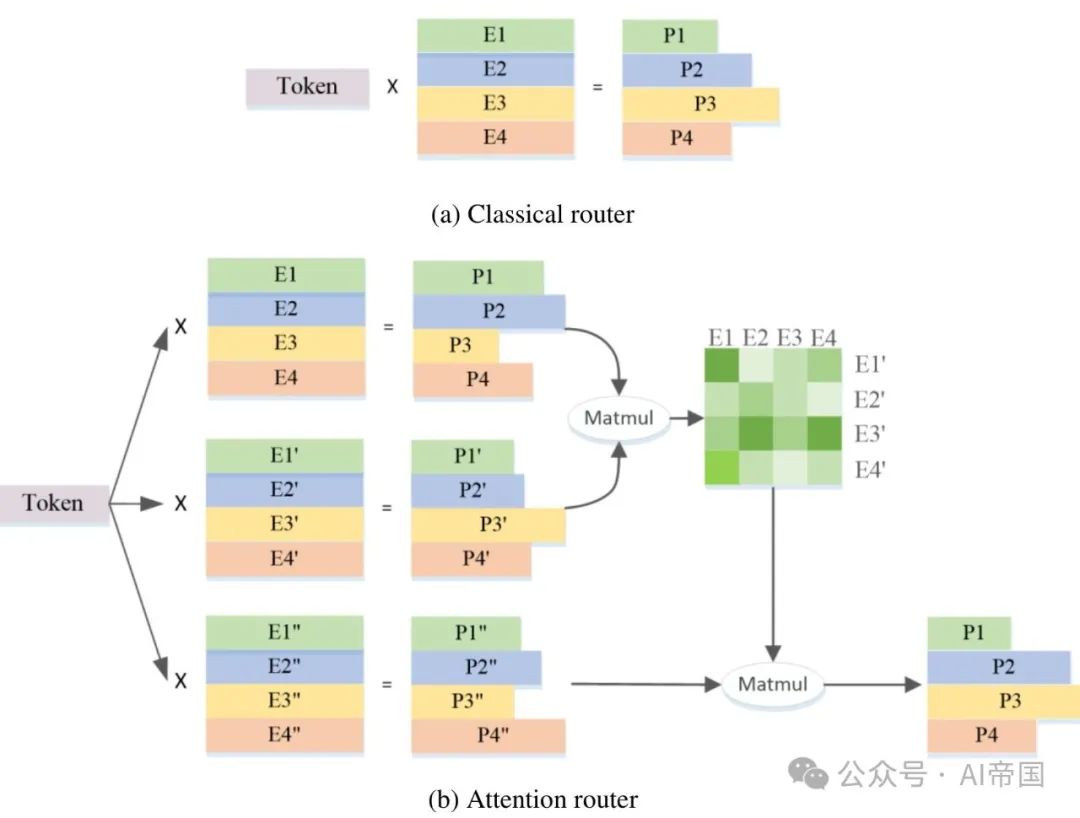 Tableau 1 : Comparaison des différentes structures de routage
Tableau 1 : Comparaison des différentes structures de routage
Le Tableau 1 répertorie les résultats de précision des différents routeurs. Le modèle du journal a testé le routeur d'attention sur 8 experts pouvant être formés. Le modèle de routeur classique dispose de 8 experts pouvant être formés pour garantir une échelle de paramètres similaire, et la structure de routage est la même que celle appliquée au Mixtral 8*7B, c'est-à-dire Softmax sur une couche linéaire. Le routeur expert partagé adopte la stratégie d’isolation experte partagée et l’architecture de routage classique. Il y a deux experts fixes capturant les connaissances générales et les deux premiers des 14 experts optionnels en tant qu'experts spécialisés.
La sortie du MoE est une combinaison d'experts fixes et d'experts sélectionnés par le routeur. Les trois modèles utilisent 30 Btokens pour la formation et 10 Btokens supplémentaires pour les tests. En considérant les résultats entre le routeur classique et le routeur expert partagé, l'article a constaté que ce dernier obtenait exactement la même perte de test avec une augmentation de 7,35 % du temps de formation. L’efficacité informatique des experts partagés est relativement faible et ne conduit pas à une meilleure précision de formation que la stratégie MOE classique. Par conséquent, dans le modèle du document, le document adopte une stratégie de routage classique sans aucun expert partagé. Par rapport au réseau routé classique, le test de perte d'attention du routeur a augmenté de 3,8 %.
 L'article teste l'évolutivité du modèle en augmentant le nombre d'experts et en fixant la taille des paramètres de chaque expert. L'augmentation du nombre d'experts en formation ne modifie que la capacité du modèle, pas les paramètres réellement activés du modèle. Tous les modèles sont entraînés avec 50 milliards de jetons et testés avec 10 milliards de jetons supplémentaires. Le document fixe les experts activés à 2 et les hyperparamètres de formation des trois modèles sont les mêmes. L'effet de mise à l'échelle expert est mesuré par la perte de test après la formation de 50 milliards de jetons (tableau 2). Par rapport au modèle avec 8 experts pouvant être formés, le modèle avec 16 experts a montré une réduction des pertes de 2 %, tandis que le modèle avec 32 experts a montré une réduction des pertes de 3,6 %. Compte tenu de son exactitude, le document a sélectionné 32 experts pour Yuan 2.0-M32.
L'article teste l'évolutivité du modèle en augmentant le nombre d'experts et en fixant la taille des paramètres de chaque expert. L'augmentation du nombre d'experts en formation ne modifie que la capacité du modèle, pas les paramètres réellement activés du modèle. Tous les modèles sont entraînés avec 50 milliards de jetons et testés avec 10 milliards de jetons supplémentaires. Le document fixe les experts activés à 2 et les hyperparamètres de formation des trois modèles sont les mêmes. L'effet de mise à l'échelle expert est mesuré par la perte de test après la formation de 50 milliards de jetons (tableau 2). Par rapport au modèle avec 8 experts pouvant être formés, le modèle avec 16 experts a montré une réduction des pertes de 2 %, tandis que le modèle avec 32 experts a montré une réduction des pertes de 3,6 %. Compte tenu de son exactitude, le document a sélectionné 32 experts pour Yuan 2.0-M32.
Tableau 2 : Résultats expérimentaux étendus
2.2.2 Formation du modèle
Yuan 2.0-M32 est formé grâce à une combinaison de parallélisme de données et de parallélisme de pipeline, mais n'utilise pas de parallélisme tenseur ni de parallélisme optimiseur. La figure 3 montre la courbe de perte et la perte finale d'entraînement est de 1,22.
 D Au cours du processus de réglage fin, le document a étendu la longueur de la séquence à 16 384. Suite aux travaux de CodeLLama (Roziere et al., 2023), l'article réinitialise la valeur de fréquence fondamentale de l'intégration de position pivotée (RoPE) pour éviter l'atténuation du score d'attention à mesure que la longueur de la séquence augmente. Plutôt que de simplement augmenter la valeur de base de 1 000 à une valeur très élevée (par exemple 1 000 000), l'article utilise la connaissance NTK (bloc97, 2023) pour calculer la nouvelle valeur de base.
D Au cours du processus de réglage fin, le document a étendu la longueur de la séquence à 16 384. Suite aux travaux de CodeLLama (Roziere et al., 2023), l'article réinitialise la valeur de fréquence fondamentale de l'intégration de position pivotée (RoPE) pour éviter l'atténuation du score d'attention à mesure que la longueur de la séquence augmente. Plutôt que de simplement augmenter la valeur de base de 1 000 à une valeur très élevée (par exemple 1 000 000), l'article utilise la connaissance NTK (bloc97, 2023) pour calculer la nouvelle valeur de base.
L'article compare également les performances du modèle Yuan 2.0-M32 pré-entraîné avec de nouvelles bases dans le style perceptuel NTK et avec d'autres bases dans les tâches de récupération d'aiguilles avec des longueurs de séquence allant jusqu'à 16K. L'article révèle que la nouvelle valeur de base de 40 890 pour le style de perception NTK est plus performante. Par conséquent, 40890 est appliqué lors du réglage fin.
2.2.4 Ensemble de données de pré-entraînement
Yuan 2.0-M32 est pré-entraîné à partir de zéro à l'aide d'un ensemble de données bilingue contenant 2000 milliards de jetons. Les données brutes pré-entraînées contiennent plus de 3 400 milliards de jetons et le poids de chaque catégorie est ajusté en fonction de la qualité et de la quantité des données.
Le corpus complet de pré-formation se compose de :
44 sous-ensembles de données couvrant les données explorées sur le Web, Wikipédia, les articles académiques, les livres, le code, les mathématiques et les formules, ainsi que l'expertise spécifique au domaine. Certains d'entre eux sont des ensembles de données open source et les autres ont été créés par Yuan 2.0.
Certaines données courantes des robots d'exploration Web, des livres chinois, des conversations et des données d'actualités chinoises sont héritées de Yuan 1.0 (Wu et al., 2021). La plupart des données de pré-formation dans Yuan 2.0 ont également été réutilisées.
Les détails sur la construction et les sources de chaque ensemble de données sont les suivants :
Web (25,2 %) : les données des robots d'exploration de sites Web ont été obtenues à partir d'ensembles de données open source et de robots d'exploration publics traités à partir des données des travaux précédents du document (Yuan 1.0). collectés. Pour plus de détails sur le Massive Data Filtering System (MDFS) permettant d'extraire du contenu de haute qualité à partir d'un contexte Web, veuillez vous référer à Yuan 1.0.
Encyclopédies (1,2%), articles (0,84%), livres (6,49%) et traductions (1,1%) : les données sont héritées des ensembles de données Yuan 1.0 et Yuan 2.0.
Code (47,5%) : L'ensemble de données de code est considérablement étendu par rapport à Yuan 2.0. L'article utilise le code de Stack v2 (Lozhkov et al., 2024). Les commentaires dans Stack v2 sont traduits en chinois. Les données de synthèse de code ont été générées via une approche similaire à Yuan 2.0.
Maths (6,36%) : Toutes les données mathématiques de Yuan 2.0 ont été réutilisées. Ces données proviennent principalement d'ensembles de données open source, notamment proof-pile vl (Azerbayev, 2022) et v2 (Paster et al., 2023), AMPS (Hendrycks et al., 2021), MathPile (Wang, Xia et Liu, 2023). ) et StackMathQA (Zhang, 2024). Création d'un ensemble de données synthétiques pour les calculs numériques à l'aide de Python afin de faciliter quatre opérations arithmétiques.
Domaine spécifique (1,93%) : Il s'agit d'un ensemble de données contenant différentes connaissances de base.
2.2.5 Ensemble de données de réglage fin
L'ensemble de données de réglage fin est étendu en fonction de l'ensemble de données appliqué dans Yuan 2.0.
Ensemble de données d'instructions de code. Toutes les données de programmation avec des instructions en chinois et certaines avec des commentaires en anglais sont générées par de grands modèles de langage (LLM). Environ 30 % des données d’instructions de code sont en anglais et le reste est en chinois. Les données synthétiques imitent le code Python avec des annotations chinoises dans des stratégies de génération rapide et de nettoyage des données.
Code Python avec commentaires en anglais collectés à partir de Magicoder-Evol-Instruct-110K et CodeFeedback-Filtered-Instruction. Extrayez les données d'instruction avec des balises de langage (telles que "python") de l'ensemble de données.
Le code dans d'autres langages tels que C/C++/Go/Java/SQL/Shell, avec des commentaires en anglais, provient d'ensembles de données open source et est traité de la même manière que le code Python. La stratégie de nettoyage est similaire à la méthode de Yuan 2.0. Un bac à sable est conçu pour extraire les lignes compilables et exécutables du code généré et conserver les lignes qui réussissent au moins un test unitaire.
Ensemble de données d'instructions mathématiques. Les ensembles de données d'instructions mathématiques sont tous hérités de l'ensemble de données de réglage fin de Yuan 2.0. Afin d'améliorer la capacité du modèle à résoudre des problèmes mathématiques grâce à des méthodes de programmation, l'article a construit des données mathématiques suscitées par les pensées (PoT). PoT convertit les problèmes mathématiques en tâches de génération de code qui effectuent des calculs en Python.
Ensemble de données sur les instructions de sécurité. En plus de l'ensemble de données de discussion Yuan 2.0, le document crée également un ensemble de données d'alignement de sécurité bilingue basé sur un ensemble de données d'alignement de sécurité open source. L'article extrait uniquement les questions des ensembles de données publiques, augmente la diversité des questions et utilise de grands modèles linguistiques pour régénérer les réponses en chinois et en anglais.
2.2.6 Tokenizer
Pour Yuan 2.0-M32, les tokenizers anglais et chinois sont hérités du tokenizer appliqué dans Yuan 2.0.
2.3 L'effet de l'article
L'article évalue la capacité de génération de code de Yuan 2.0-M32 sur HumanEval, la capacité de résolution de problèmes mathématiques sur GSM8K et MATH, ainsi que les connaissances scientifiques et la capacité de raisonnement sur ARC. et évalué sur MMLU en tant que référence complète.
2.3.1 Génération de code
Les capacités de génération de code sont évaluées à l'aide du benchmark HumanEval. Les méthodes d'évaluation et les conseils sont similaires à ceux mentionnés dans Meta 2.0.
 Tableau 3 : Comparaison entre Yuan 2.0-M32 et d'autres modèles sur le pass HumanEval @1
Tableau 3 : Comparaison entre Yuan 2.0-M32 et d'autres modèles sur le pass HumanEval @1
Le modèle devrait terminer la fonction après. Les fonctions générées seront évaluées via des tests unitaires. Le tableau 3 montre les résultats du Yuan 2.0-M32 en matière d'apprentissage zéro-shot et les compare avec d'autres modèles. Les résultats de Yuan 2.0-M32 sont juste derrière DeepseekV2 et Llama3-70B, et dépassent de loin les autres modèles, même si ses paramètres actifs et sa consommation de calcul sont bien inférieurs à ceux des autres modèles.
Par rapport à DeepseekV2, le modèle du papier utilise moins d'un quart des paramètres actifs et nécessite moins d'un cinquième des calculs par jeton, tout en atteignant son niveau de précision de plus de 90 %. Par rapport à Llama3-70B, l'écart entre les paramètres du modèle et la quantité de calcul est encore plus grand, mais le papier peut encore atteindre 91 % de son niveau. Yuan 2.0-M32 a démontré de solides capacités de programmation, en réussissant trois questions sur quatre. Yuan 2.0-M32 excelle dans l'apprentissage de petits échantillons, augmentant la précision de HumanEval à 78,0 en 14 tentatives.
2.3.2 Mathématiques
Les capacités mathématiques de Yuan 2.0-M32 sont évaluées via les benchmarks GSM8K et MATH. Les invites et les stratégies de test pour GSM8K sont similaires à celles appliquées à Yuan 2.0, la seule différence étant que le document utilise 8 tentatives (Tableau 4).
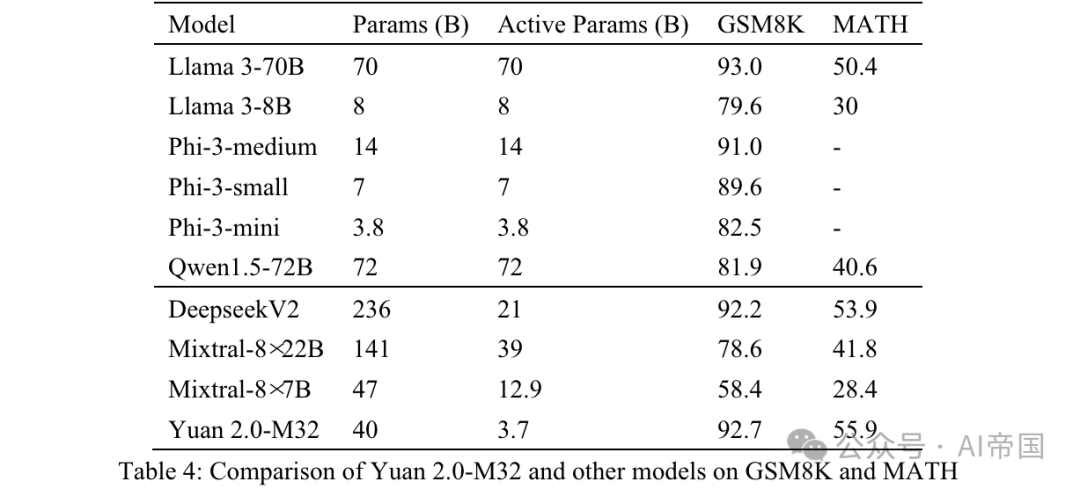 Tableau 4 : Comparaison du Yuan 2.0-M32 avec d'autres modèles sur GSM8K et MATH
Tableau 4 : Comparaison du Yuan 2.0-M32 avec d'autres modèles sur GSM8K et MATH
MATH est un ensemble de données contenant 12 500 questions et réponses stimulantes de concours de mathématiques. Chaque question de cet ensemble de données comporte une solution complète, étape par étape, guidant le modèle pour générer la dérivation de réponses et des explications. La réponse à la question peut être une valeur numérique ou une expression mathématique (telle que y=2x+5, x-+2x-1, 2a+b, etc.). Yuan 2.0-M32 utilise la méthode Chain of Thinking (CoT) pour générer la réponse finale en 4 tentatives. Les réponses seront extraites de l’analyse et converties dans un format unifié.
Pour les résultats numériques, une sortie mathématiquement équivalente dans tous les formats est acceptée. Par exemple, les fractions 1/2, 12, 0,5, 0,50 sont toutes converties en 0,5 et traitées comme le même résultat. Pour les expressions mathématiques, le document supprime les symboles de tabulation et d'espace et unifie les expressions régulières pour le rythme ou les notes de musique. 55 '5' sont tous acceptés comme la même réponse. Le résultat final après traitement est comparé à la réponse standard et évalué à l'aide du score EM (Exact Match).
Comme le montrent les résultats présentés dans le tableau 4, Yuan 2.0-M32 a le score le plus élevé sur le benchmark MATH. Par rapport à Mixtral-8x7B, les paramètres actifs de ce dernier sont 3,48 fois supérieurs à ceux de Yuan 2.0-M32, mais le score de Yuan est presque le double. Sur GSM8K, le score du Yuan 2.0-M32 est également très proche du Llama 3-70B et meilleur que les autres modèles.
2.3.3MMLU
La compréhension multitâche du langage à grande échelle (MMLU) couvre 57 disciplines telles que les STEM, les sciences humaines et sociales, allant des tâches linguistiques de base aux tâches avancées de raisonnement logique. Toutes les questions de MMLU sont des questions d'assurance qualité à choix multiples en anglais. Le modèle est censé générer les options correctes ou les analyses correspondantes.
L'organisation des données d'entrée de Yuan 2.0-M32 est présentée à l'annexe B. Le texte précédent est envoyé au modèle et toutes les réponses liées à la bonne réponse ou à l'étiquette d'option sont considérées comme correctes.
La précision finale est mesurée par MC1 (Tableau 5). Les résultats sur MMLU démontrent les capacités du modèle papier dans différents domaines. Yuan 2.0-M32 dépasse Mixtral-8x7B, Phi-3-mini et Llama 3-8B en termes de performances.
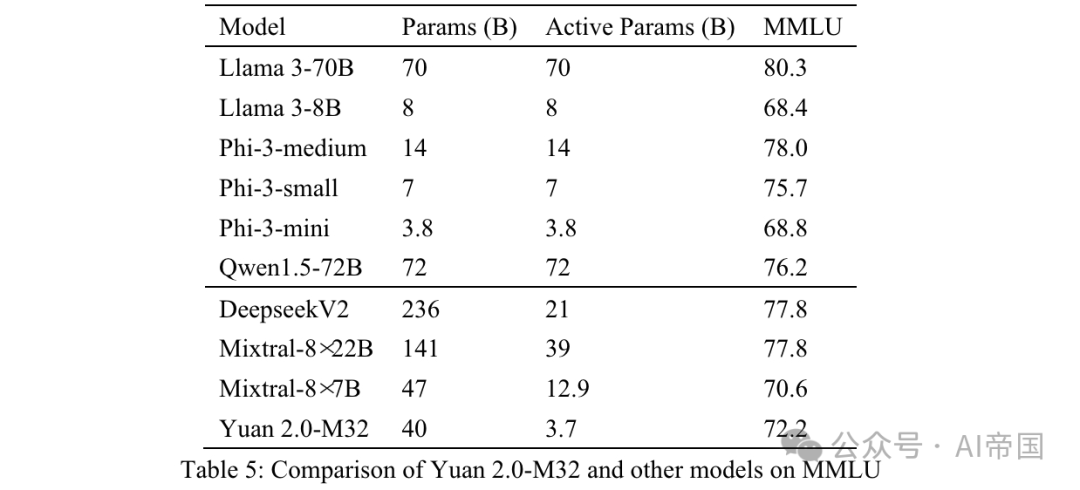 Tableau 5 : Comparaison de Yuan 2.0-M32 avec d'autres modèles sur MMLU
Tableau 5 : Comparaison de Yuan 2.0-M32 avec d'autres modèles sur MMLU
2.3.4 ARC
Le benchmark AI2 Inference Challenge (ARC) est un ensemble de données d'assurance qualité à sélection multiple contenant des données de 3 Questions du test de sciences pour les 9e et 9e années. Il est divisé en deux parties, Facile et Défi, cette dernière contenant des parties plus complexes qui nécessitent un raisonnement plus approfondi. L'article teste le modèle de l'article dans la section des défis.
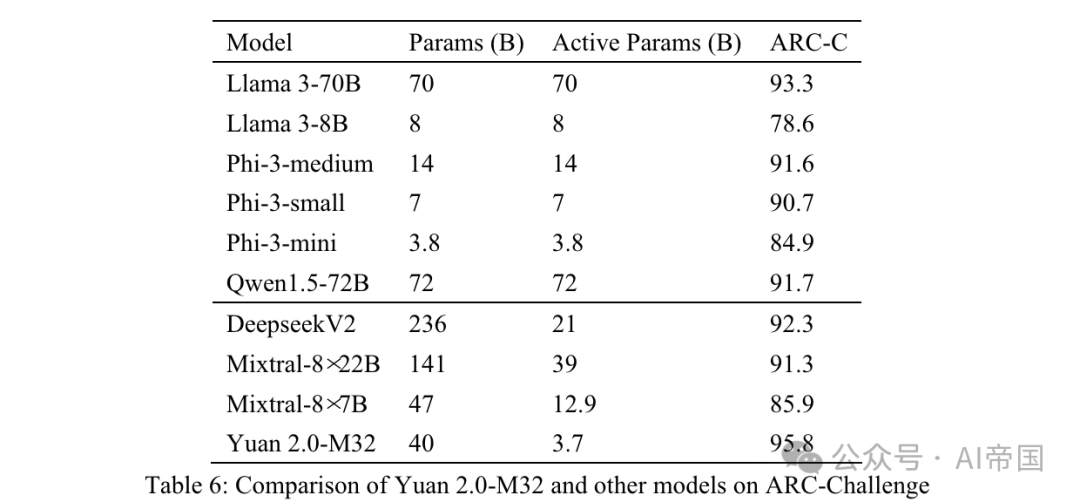 Tableau 6 : Comparaison du Yuan 2.0-M32 et d'autres modèles sur ARC-Challenge
Tableau 6 : Comparaison du Yuan 2.0-M32 et d'autres modèles sur ARC-Challenge
Les questions et options sont directement connectées et séparées par . Le texte précédent est envoyé au modèle, qui est censé générer une étiquette ou une réponse correspondante. Les réponses générées sont comparées aux réponses réelles et les résultats sont calculés à l'aide de la cible MC1.
Le tableau 6 montre les résultats pour ARC-C montrant que Yuan 2.0-M32 excelle dans la résolution de problèmes scientifiques complexes - il surpasse Llama3-70B sur cette référence.
 Photos
Photos
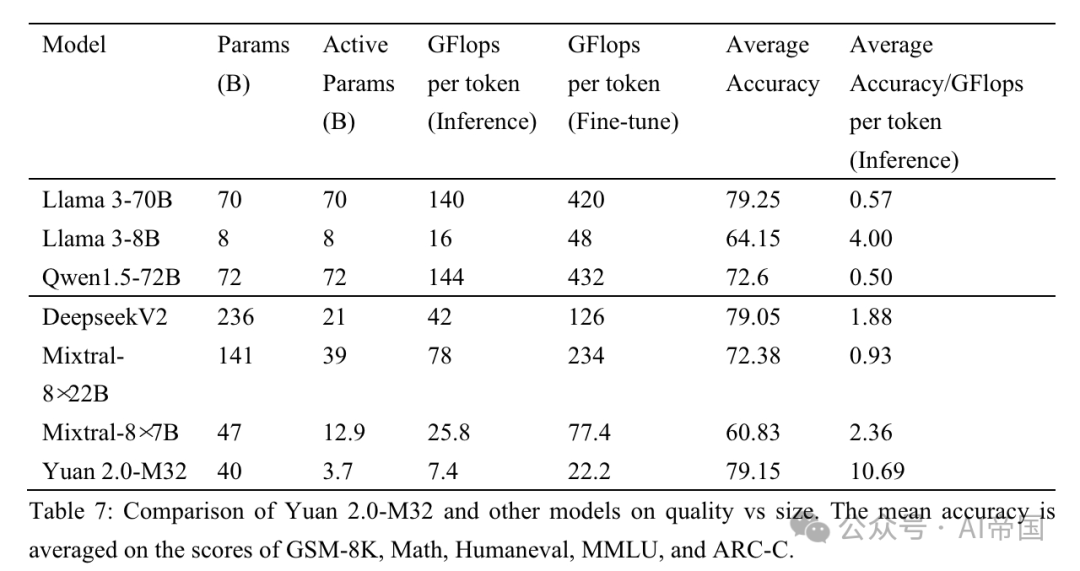
Tableau 7 : Comparaison de la qualité et de la taille entre le Yuan 2.0-M32 et d'autres modèles. La précision moyenne est calculée sur la base des scores GSM-8K, Math, Humaneval, MMLU et ARC-C
L'article compare les performances du papier avec trois modèles MoE (famille Mixtral, Deepseek) et six modèles denses (Qwen (Bai et al., 2023), famille Llama et famille Phi-3 (Abdin et al., 2024). )) pour évaluer les performances du Yuan 2.0-M32 dans différents domaines. Le tableau 7 montre la comparaison entre la précision et l'effort de calcul entre Yuan 2.0-M32 et d'autres modèles. Yuan 2.0-M32 est affiné en utilisant seulement 3,7 milliards de paramètres actifs et 22,2 GFlops par jeton, ce qui est le plus économique pour obtenir des résultats comparables, voire supérieurs, aux autres modèles répertoriés dans le tableau. Le tableau 7 fait allusion à l'excellente efficacité de calcul et aux performances du modèle papier pendant le processus d'inférence. Le Yuan 2.0-M32 a une précision moyenne de 79,15, comparable à celle du Llama3-70B. La valeur moyenne de précision/GFlops par jeton est de 10,69, soit 18,9 fois celle de Llama3-70B.
Titre de l'article : Yuan 2.0-M32 : Mélange d'experts avec un routeur d'attention
Lien de l'article : https://www.php.cn/link/cc7d159d6ff3ea6f39b9419877dfc81f
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser les objets mathématiques en JavaScript
- Comment importer une bibliothèque mathématique en python ?
- Implémentation de l'algorithme client-serveur Diffie-Hellman en Java
- Inférence LLM sur plusieurs GPU à l'aide de la bibliothèque Accelerate
- Tout mettre en œuvre pour boucler la boucle ! DriveMLM : combinez parfaitement le LLM avec la planification du comportement de conduite autonome !