La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Richard Sutton a fait cette évaluation dans "The Bitter Lesson" : "La meilleure conclusion que l'on puisse tirer de 70 ans de recherche sur l'intelligence artificielle est la La leçon importante est que les méthodes générales qui exploitent le calcul sont en fin de compte les plus efficaces, et que les avantages sont énormes. "Le jeu autonome est l'une de ces méthodes qui utilise à la fois la recherche et l'apprentissage pour exploiter et faire évoluer pleinement le calcul. Au début de cette année, l'équipe du professeur Gu Quanquan de l'Université de Californie à Los Angeles (UCLA) a proposé un Self-Play Fine-Tuning, SPIN)
, qui n'utilise pas de données de réglage supplémentaires. et repose uniquement sur le jeu autonome. Le jeu peut grandement améliorer les capacités de LLM.
Récemment, l'équipe du professeur Gu Quanquan et celle du professeur Yiming Yang de l'Université Carnegie Mellon (CMU) ont collaboré pour développer une méthode appelée "Self-Play Preference Optimization (SPPO)
" Technologie d'alignement, cette nouvelle méthode vise à optimiser le comportement de grands modèles de langage à travers un cadre de jeu personnel pour mieux correspondre aux préférences humaines. Combattez-vous de gauche à droite et montrez à nouveau vos pouvoirs magiques !
 Titre de l'article : Optimisation des préférences d'auto-lecture pour l'alignement du modèle linguistique
Titre de l'article : Optimisation des préférences d'auto-lecture pour l'alignement du modèle linguistique
- Lien de l'article : https://arxiv.org/pdf/2405.00675.pdf
-
Technologie Contexte et défis
Les grands modèles de langage (LLM) deviennent une force motrice importante dans le domaine de l'intelligence artificielle, performants dans diverses tâches grâce à leurs excellentes capacités de génération de texte et de compréhension. Bien que les capacités de LLM soient impressionnantes, rendre le comportement de sortie de ces modèles plus cohérent avec les besoins des applications pratiques nécessite souvent un réglage précis via un processus d'alignement. La clé de ce processus est d'ajuster le modèle pour mieux refléter les préférences humaines et les normes comportementales. Les méthodes courantes incluent l'apprentissage par renforcement basé sur la rétroaction humaine (RLHF) ou l'optimisation directe des préférences (Direct Preference Optimization, DPO). L'apprentissage par renforcement basé sur le feedback humain (RLHF) repose sur le maintien explicite d'un modèle de récompense pour ajuster et affiner les grands modèles de langage. En d’autres termes, par exemple, InstructGPT entraîne d’abord une fonction de récompense qui obéit au modèle Bradley-Terry sur la base de données de préférences humaines, puis utilise des algorithmes d’apprentissage par renforcement tels que l’optimisation des politiques proximales (PPO) pour optimiser les grands modèles de langage. L’année dernière, des chercheurs ont proposé l’optimisation des préférences directes (DPO). Contrairement au RLHF, qui maintient un modèle de récompense explicite, l'algorithme DPO obéit implicitement au modèle Bradley-Terry, mais peut être directement utilisé pour l'optimisation de grands modèles de langage. Les travaux existants ont tenté d'affiner davantage les grands modèles en utilisant DPO sur plusieurs itérations (Figure 1). ‐ Partition numérique . Bien que ces modèles fournissent des approximations raisonnables des préférences humaines, ils ne parviennent pas à saisir pleinement la complexité du comportement humain.
Ces modèles supposent souvent que la relation de préférence entre différents choix est monotone et transitive, tandis que les preuves empiriques montrent souvent l'incohérence et la non-linéarité de la prise de décision humaine. Par exemple, l'étude de Tversky a observé que la prise de décision humaine peut être affectée. par Divers facteurs l’influencent et montrent des incohérences.
Base théorique et méthode du SPPO
两 Figure 2. Deux modèles linguistiques d'imagination sont souvent utilisés. Dans ces contextes, l'auteur propose un nouveau cadre de jeu personnel SPPO, qui a non seulement des garanties prouvables pour résoudre des jeux à somme constante à deux joueurs, mais aussi affiner efficacement de grands modèles de langage qui échelles à grande échelle.
Plus précisément, l'article définit strictement le problème RLHF comme un jeu à somme normale à deux joueurs (Figure 2). Le but de ce travail est d'identifier les stratégies d'équilibre de Nash qui, en moyenne, fournissent toujours une réponse plus privilégiée que toute autre stratégie.
Afin d'identifier approximativement la stratégie d'équilibre de Nash, l'auteur adopte l'algorithme adaptatif en ligne classique avec des poids multiplicatifs comme algorithme-cadre de haut niveau pour résoudre le jeu à deux joueurs.
Dans chaque étape de ce cadre, l'algorithme peut approximer les mises à jour de poids multiplicatives via un mécanisme d'auto-jeu, où à chaque tour, le grand modèle de langage s'ajuste avec précision par rapport au tour précédent, généré par le modèle Synthétiser. annotations de modèles de données et de préférences pour l’optimisation.
Plus précisément, le grand modèle de langage générera plusieurs réponses pour chaque invite à chaque tour ; sur la base de l'annotation du modèle de préférence, l'algorithme peut estimer le taux de victoire de chaque réponse, l'algorithme peut ainsi affiner davantage ; le modèle de langage large. Les paramètres font que les réponses avec un taux de réussite élevé ont une probabilité plus élevée d'apparaître (Figure 3).
Conception expérimentale et résultatsDans l'expérience, l'équipe de recherche a adopté un Mistral-7B comme modèle de base et a utilisé 60 000 invites de l'UltraFe Ensemble de données edback pour la formation non supervisée. Ils ont constaté que grâce à l'auto-jeu, le modèle peut améliorer considérablement ses performances sur plusieurs plates-formes d'évaluation, telles que AlpacaEval 2.0 et MT-Bench. Ces plateformes sont largement utilisées pour évaluer la qualité et la pertinence du texte généré par un modèle. Grâce à la méthode SPPO, le modèle est non seulement amélioré en termes de fluidité et de précision
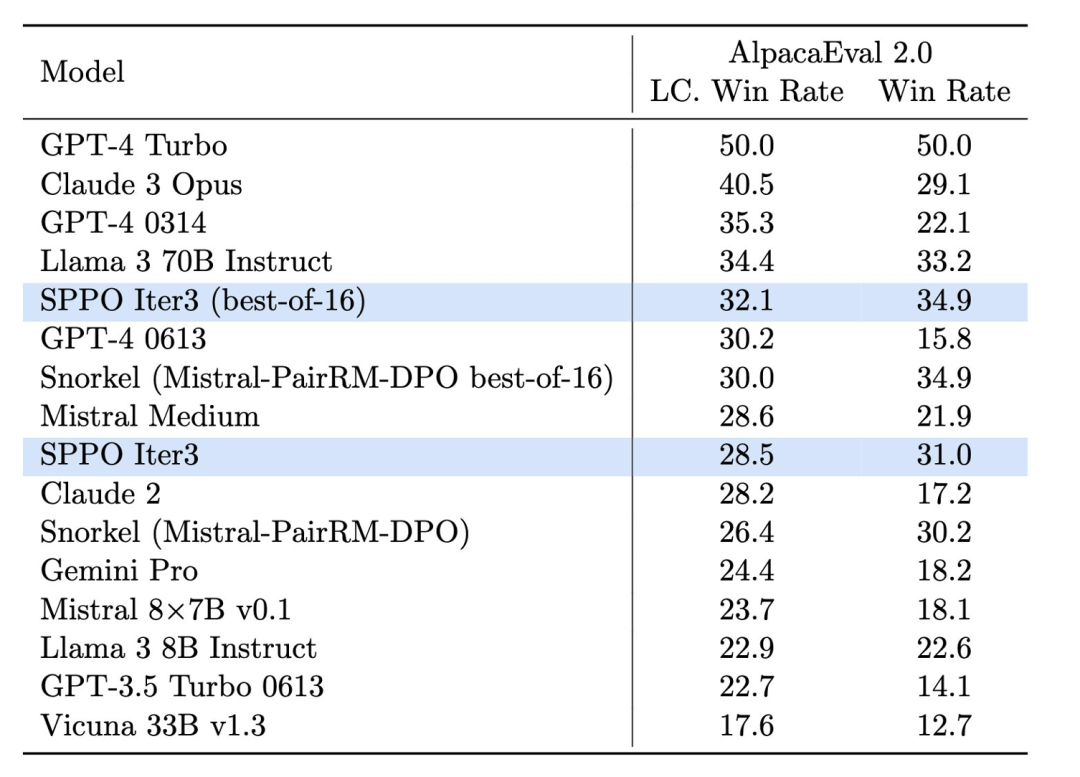
du texte généré, mais plus important encore : "Il fonctionne mieux en se conformant aux valeurs et préférences humaines." O Figure 4. L'effet du modèle sppo sur Alpacaeval 2.0 est significativement amélioré et il est supérieur à celui d'autres méthodes de référence telles que le DPO itératif.
Dans le test d'AlpacaEval 2.0 (Figure 4), le modèle optimisé par SPPO a amélioré le taux de réussite du contrôle de longueur de 17,11 % du modèle de base à 28,53 %, montrant une amélioration significative de sa compréhension des préférences humaines. . Le modèle optimisé par trois tours de SPPO est nettement meilleur que l'itération à plusieurs tours de DPO, IPO et modèle de langage auto-récompensé (Self-Rewarding LM) sur AlpacaEval2.0.
De plus, les performances du modèle sur MT-Bench ont également dépassé les modèles traditionnels optimisés grâce aux commentaires humains. Cela démontre l'efficacité de SPPO pour adapter automatiquement le comportement du modèle à des tâches complexes.
Conclusion et perspectives d'avenir
L'optimisation des préférences auto-exécutables (SPPO) fournit une nouvelle voie d'optimisation pour les grands modèles de langage, qui améliore non seulement la qualité de génération du modèle, mais plus important encore, la qualité du modèle. Alignement avec les préférences humaines.
Avec le développement et l'optimisation continus de la technologie, SPPO et ses technologies dérivées devraient jouer un rôle plus important dans le développement durable et l'application sociale de l'intelligence artificielle, ouvrant la voie à la construction de systèmes d'IA plus intelligents et responsables. . Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 Titre de l'article : Optimisation des préférences d'auto-lecture pour l'alignement du modèle linguistique
Titre de l'article : Optimisation des préférences d'auto-lecture pour l'alignement du modèle linguistique