


Python crawler method to obtain data
Python crawlers can send HTTP requests through the request library, parse HTML with the parsing library, extract data with regular expressions, or use a data scraping framework to obtain data. More knowledge about Python crawlers. Read the article below this topic for details. PHP Chinese website welcomes everyone to come and learn.
 169
169 12
12
Python crawler method to obtain data

Python crawler method to obtain data
Python crawlers can send HTTP requests through the request library, parse HTML with the parsing library, extract data with regular expressions, or use a data scraping framework to obtain data. Detailed introduction: 1. The request library sends HTTP requests, such as Requests, urllib, etc.; 2. The parsing library parses HTML, such as BeautifulSoup, lxml, etc.; 3. Regular expressions extract data. Regular expressions are used to describe string patterns. Tools can extract data that meets requirements by matching patterns, etc.
Nov 13, 2023 am 10:44 AM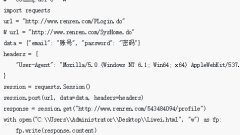
Basic use of requests library
1. The difference between response.content and response.text: response.content is an encoded byte type ("str" data type), and response.text is a unicode type. The use of these two methods depends on the situation. Note: unicode -> str is the encoding process (encode()); str -> unicode is the decoding process (decode()). An example is as follows: # --codin...
Jun 11, 2018 pm 10:55 PM
How to use the Python web crawler requests library
1. What is a web crawler? Simply put, it is to build a program to download, parse and organize data from the Internet in an automated way. Just like when we browse the web, we will copy and paste the content we are interested in into our notebooks for easy reading and browsing next time - the web crawler helps us automatically complete these content. Of course, if we encounter some websites that cannot be copied and pasted - —Web crawlers can show their power even more. Why do we need web crawlers? When we need to do some data analysis-and many times this data is stored in web pages, and it takes time to download it manually.
May 15, 2023 am 10:34 AM
An article will guide you through the urllib library in Python (operating URLs)
Using Python language can help everyone learn Python better. The function provided by urllib is to use programs to perform various HTTP requests. If you want to simulate a browser to complete a specific function, you need to disguise the request as a browser. The method of camouflage is to first monitor the requests sent by the browser, and then camouflage them based on the browser's request header. The User-Agent header is used to identify the browser.
Jul 25, 2023 pm 02:08 PM
What should I do if I want to use the urllib2 package in python3.6?
The urllib2 toolkit in Pyhton2 was split into two packages: urllib.request and urllib.error in Python3. As a result, the package cannot be found and there is no way to install it. So install these two packages and use the method when importing.
Jul 01, 2019 pm 02:18 PM
How to use urllib.urlopen() function to send GET request in Python 2.x
Python is a popular programming language widely used in areas such as web development, data analysis, and automation tasks. In the Python2.x version, you can easily send GET requests and obtain response data using the urlopen() function of the urllib library. This article will introduce in detail how to use the urlopen() function to send GET requests in Python2.x, and provide corresponding code examples. Before sending a GET request using the urlopen() function, we first need to
Jul 29, 2023 am 08:48 AM
Detailed explanation of Python's urllib crawler, request module and parse module
urllib is a toolkit in Python used to process URLs. This article uses this toolkit to explain crawler development. After all, crawler application development is very important in Web Internet data collection. Article directory urllibrequest module accesses the URLRequest class other classes parse module parses URL escapes URLrobots.txt file
Mar 21, 2021 pm 03:15 PM
How to use python beautifulsoup4 module
1. Basic knowledge supplement of BeautifulSoup4 BeautifulSoup4 is a python parsing library, mainly used to parse HTML and XML. In the crawler knowledge system, more HTML will be parsed. The installation command of the library is as follows: pipinstallbeautifulsoup4BeautifulSoup needs to rely on a third party when parsing data. Parsers, commonly used parsers and advantages are as follows: python standard library html.parser: python built-in standard library, strong fault tolerance; lxml parser: fast, strong fault tolerance; html5lib: the most fault tolerant, parsing method and browsing The device is consistent. Next use a paragraph
May 11, 2023 pm 10:31 PM
Understand the Python crawler parser BeautifulSoup4 in one article
This article brings you relevant knowledge about Python, mainly sorting out issues related to the crawler parser BeautifulSoup4. Beautiful Soup is a Python library that can extract data from HTML or XML files. It can pass your favorite conversion Let's take a look at how to implement the customary document navigation, search, and modification of documents. I hope it will be helpful to everyone.
Jul 12, 2022 pm 04:56 PM
How to use Python crawler to crawl web page data using BeautifulSoup and Requests
1. Introduction The implementation principle of web crawlers can be summarized into the following steps: Sending HTTP requests: Web crawlers obtain web page content by sending HTTP requests (usually GET requests) to the target website. In Python, HTTP requests can be sent using the requests library. Parse HTML: After receiving the response from the target website, the crawler needs to parse the HTML content to extract useful information. HTML is a markup language used to describe the structure of web pages. It consists of a series of nested tags. The crawler can locate and extract the required data based on these tags and attributes. In Python, you can use libraries such as BeautifulSoup and lxml to parse HTML. Data extraction: After parsing the HTML,
Apr 29, 2023 pm 12:52 PM
Python regular expression - check if input is float
Floating point numbers play a vital role in a variety of programming tasks, from mathematical calculations to data analysis. However, when dealing with user input or data from external sources, it becomes critical to verify that the input is a valid floating point number. Python provides powerful tools to address this challenge, one of which is regular expressions. In this article, we will explore how to use regular expressions in Python to check if an input is a floating point number. Regular expressions (often called regex) provide a concise and flexible way to define patterns and search for matches in text. By leveraging regular expressions, we can construct a pattern that exactly matches the floating point format and validate the input accordingly. In this article, we will explore how to use Pyt
Sep 15, 2023 pm 04:09 PM
What is a regular expression
Regular expression is a tool used to describe, match and manipulate strings. It is a pattern composed of a series of characters and special symbols. It is used to search, replace and extract strings that match specific patterns in text. Regular expressions are widely used in computer science and software development and can be used in text processing, data validation, pattern matching and other fields. The basic idea is to describe a type of string that conforms to certain rules by defining a pattern. This pattern consists of ordinary characters and special characters. Special characters are used to represent some specific characters or character sets.
Nov 10, 2023 am 10:23 AM
Hot Article

Hot Tools
Kits AI
Transform your voice with AI artist voices. Create and train your own AI voice model.
SOUNDRAW - AI Music Generator
Create music easily for videos, films, and more with SOUNDRAW's AI music generator.
Web ChatGPT.ai
Free Chrome extension with OpenAI chatbot for efficient browsing.
i10X: ChatGPT & 500+ AI Models & Tools — Full Access from just $8!
All top AI models and 500+ expert tools — in one place, from just $8/month!
AudioX
Anything to Audio - Create Stunning Music and Sound Effects in Minutes

