
Home >Backend Development >Python Tutorial >An article will guide you through the urllib library in Python (operating URLs)
An article will guide you through the urllib library in Python (operating URLs)
- Go语言进阶学习forward
- 2023-07-25 14:08:041047browse
1. Manipulating URLs
urllib provides a series of functions for manipulating URLs. Function. Classify related content.
2. Get()
urllib’s request The module can grab URL content very conveniently, that is, send a GET request to the specified page, and then return an HTTP response:
For example, Crawl the Douban URLhttps://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078 and return the response :##
from urllib import request
with request.urlopen('https://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078') as f:
data = f.read()
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
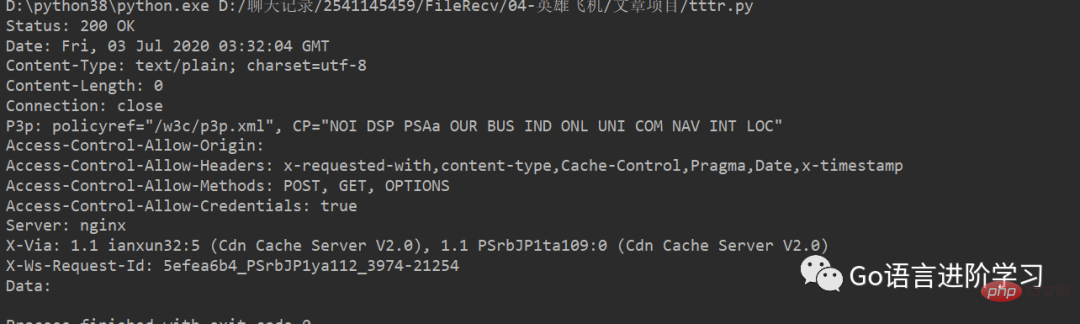
print('Data:', data.decode('utf-8'))You can see the headers and JSON data of the HTTP response:
If you want to simulate the browser sending a GET request, you need to use the Request object by going to RequestBy adding HTTP headers to the object, you can disguise the request as a browser. For example, simulate iPhone 6 to request the Douban homepage:
from urllib import request
req = request.Request('http://www.douban.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
with request.urlopen(req) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
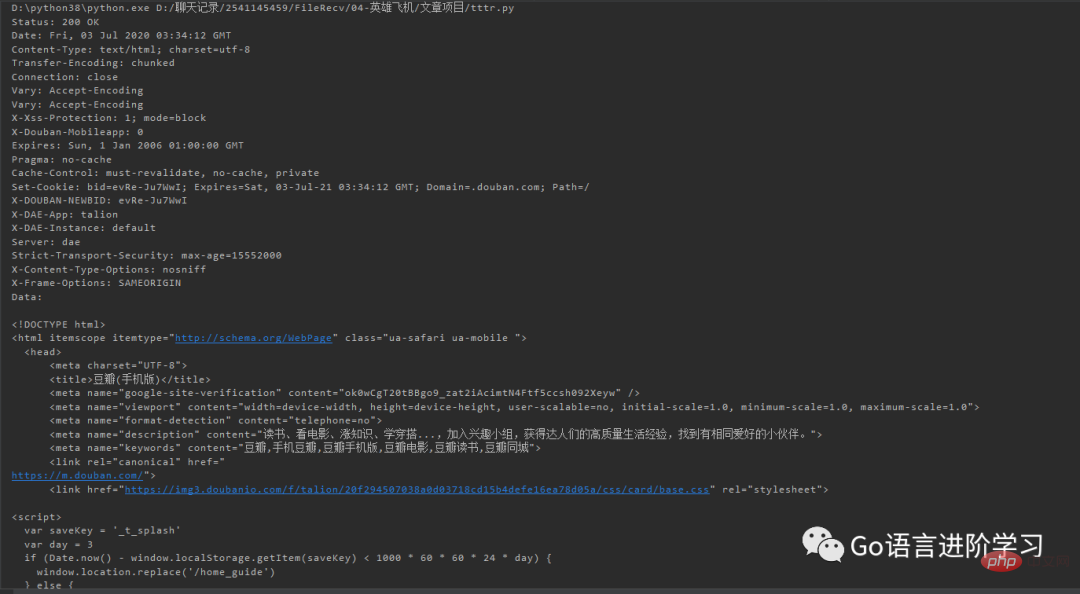
print('Data:', f.read().decode('utf-8')) In this way, Douban will return the mobile version of the web page suitable for iPhone:
##3. Post()
If you want to send a request via POST, you only need to pass in the parameters data in bytes.
模拟一个微博登录,先读取登录的邮箱和口令,然后按照weibo.cn的登录页的格式以username=xxx&password=xxx的编码传入:
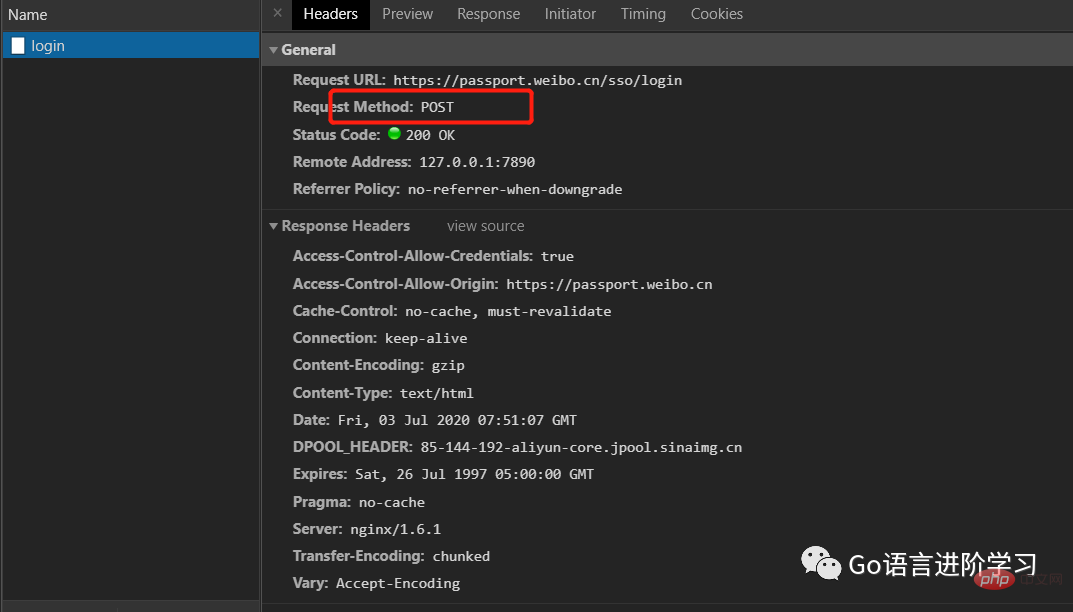
from urllib import request, parse
print('Login to weibo.cn...')
#电子邮件
email = input('Email: ')
#密码
passwd = input('Password: ')
#相关的参数
login_data = parse.urlencode([
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
#网址请求
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
#构造User-Agent
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))如果登录成功,获得的响应如下:
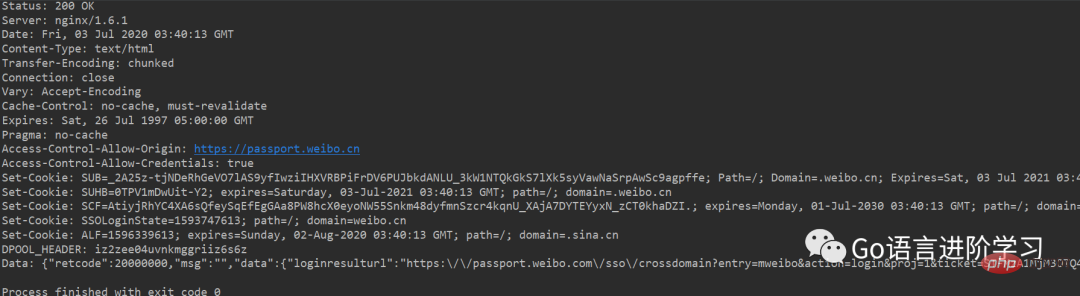
如果登录失败,获得的响应如下:
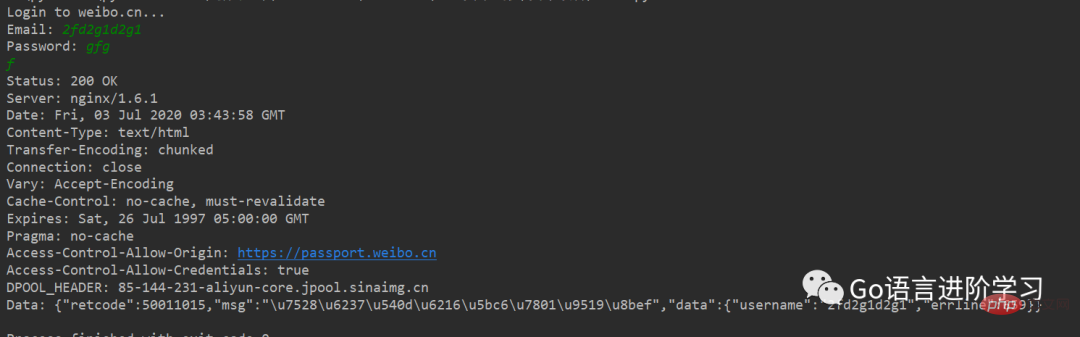
四、Handler
如果还需要更复杂的控制,比如通过一个Proxy去访问网站,需要利用ProxyHandler来处理,示例代码如下:
import urllib.request
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"https": "27.191.234.69:9999"})
nullproxy_handler = urllib.request.ProxyHandler({})
# 定义一个代理开关
proxySwitch = True
# 通过 urllib.request.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request("http://www.baidu.com/")
# 1. 如果这么写,只有使用opener.open()方法发送请求才使用自定义的代理,而urlopen()则不使用自定义代理。
response = opener.open(request)
# 2. 如果这么写,就是将opener应用到全局,之后所有的,不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urllib.request.urlopen(request)
# 获取服务器响应内容
html = response.read().decode("utf-8")
# 打印结果
print(html)如果代理成功返回网址的信息。
If the URL is wrong or the proxy address is wrong, return to the interface below.

#5. Summary
Using Python language can help everyone learn Python better. The function provided by urllib is to use programs to execute various HTTP requests. If you want to simulate a browser to complete a specific function, you need to disguise the request as a browser. The method of camouflage is to first monitor the requests sent by the browser, and then camouflage them based on the browser's request header. The User-Agent header is used to identify the browser.
The above is the detailed content of An article will guide you through the urllib library in Python (operating URLs). For more information, please follow other related articles on the PHP Chinese website!