
Home >Technology peripherals >AI >Llama 3 low-bit quantization performance drops significantly! Comprehensive assessment results are here | HKU & Beihang University & ETH
Llama 3 low-bit quantization performance drops significantly! Comprehensive assessment results are here | HKU & Beihang University & ETH

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-04-28 09:01:121134browse
The power of large models makes LLaMA3 reach new heights:
It has achieved impressive performance improvements on the 15T Token data that has undergone ultra-large-scale pre-training. It once again ignited discussions in the open source community because it far exceeded the recommendation of Chinchilla.
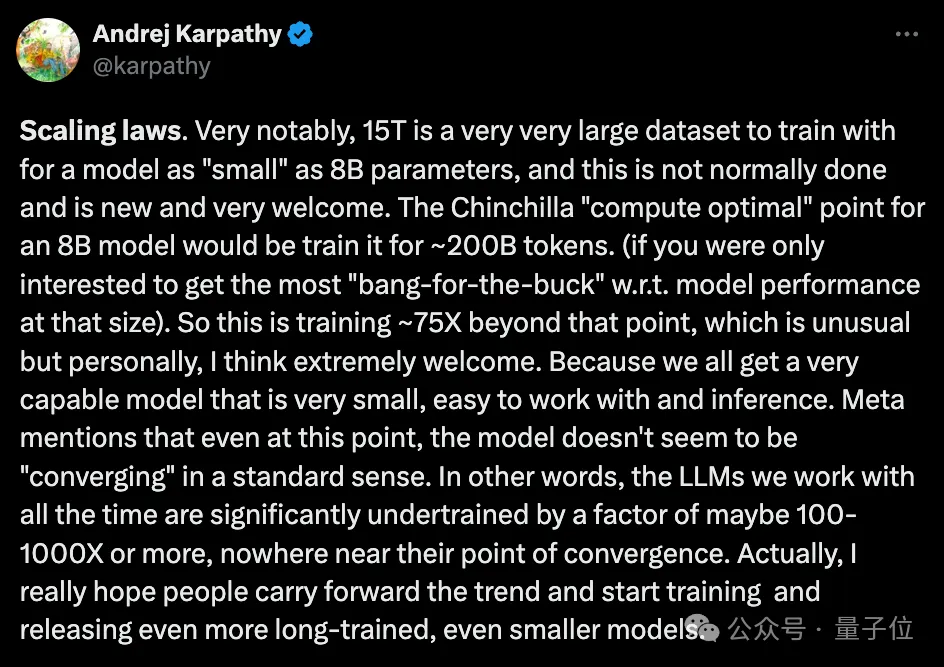
At the same time, at the practical application level, another hot topic has also surfaced:
In scenarios with limited resources, the quantitative performance of LLaMA3 has improved What will happen?
The University of Hong Kong, Beihang University, and Federal Institute of Technology Zurich jointly launched an empirical study that comprehensively revealed the low-bit quantization capabilities of LLaMA3.

The researchers evaluated the results of LLaMA3 with 1-8 bits and various evaluation datasets using 10 existing post-training quantized LoRA fine-tuning methods. They found:
Despite impressive performance, LLaMA3 still suffers from non-negligible degradation at low bit quantization, especially at ultra-low bit widths.

The project has been open sourced on GitHub, and the quantitative model has also been launched on HuggingFace.
Let’s look specifically at the empirical results.
Track 1: Post-training quantization
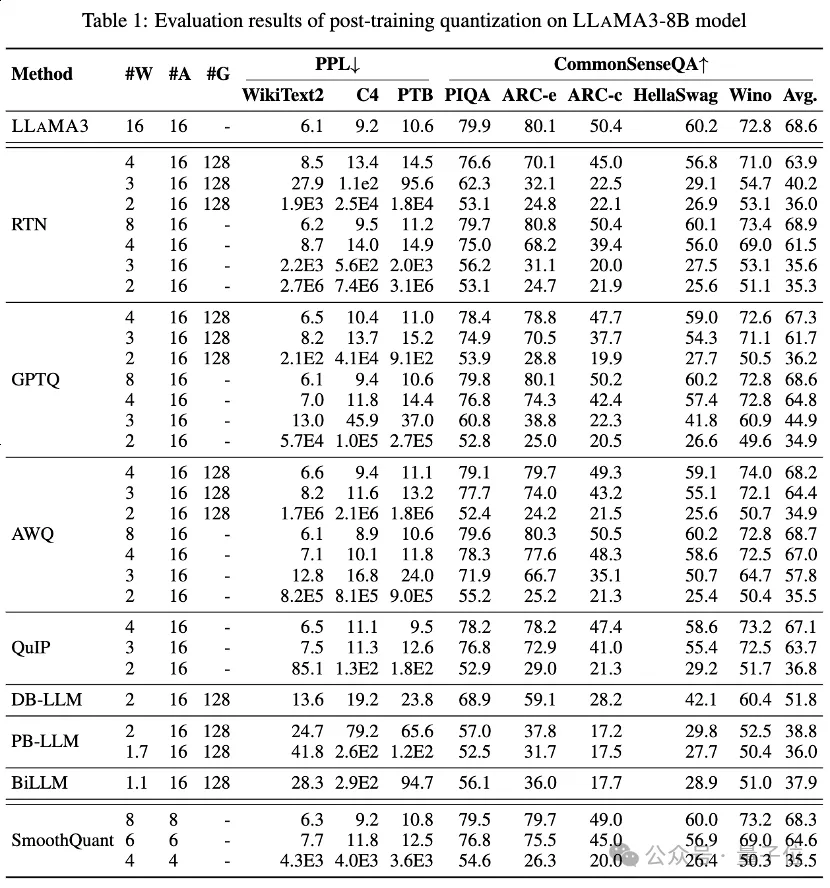
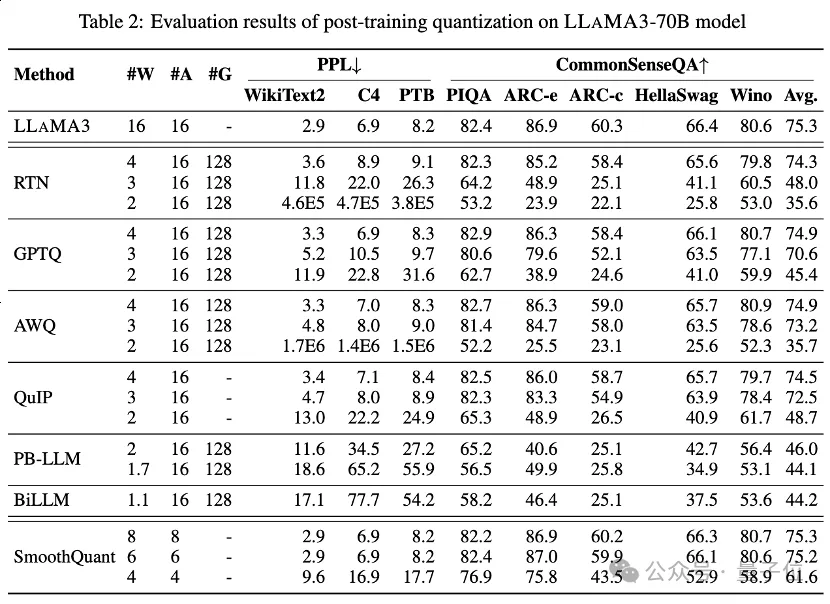
Table 1 and Table 2 provide the low-bit performance of LLaMA3-8B and LLaMA3-70B under 8 different PTQ methods, covering Wide bit width from 1 bit to 8 bits.
1. Low-bit privilege weight
Among them, Round-To-Nearest (RTN) is a basic rounding quantization method.
GPTQ is one of the most efficient and effective weight-only quantization methods currently available, which exploits error compensation in quantization. But at 2-3 bits, GPTQ causes severe accuracy collapse when quantizing LLaMA3.
AWQ uses an abnormal channel suppression method to reduce the difficulty of weight quantification, while QuIP ensures inconsistency between weights and Hessian by optimizing matrix calculations. They all maintain LLaMA3's capabilities at 3 bits and even push 2-bit quantization to promising levels.
2. Ultra-low bit width LLM weight compression
The recently emerged binary LLM quantization method achieves ultra-low bit width LLM weight compression.
PB-LLM adopts a mixed-precision quantization strategy to retain the full precision of a small part of important weights while quantizing most of the weights into 1 bit.
DB-LLM achieves efficient LLM compression through dual binarization weight division, and proposes a bias-aware distillation strategy to further enhance 2-bit LLM performance.
BiLLM further pushes the LLM quantization boundary down to 1.1 bits through residual approximation of significant weights and group quantization of non-significant weights. These LLM quantization methods specifically designed for ultra-low bit width can achieve higher precision quantization LLaMA3-8B, at ⩽2 bits far exceeding methods such as GPTQ, AWQ and QuIP at 2 bits (and even in some cases 3 bits).
3. Low-bit quantized activation
also performed LLaMA3 evaluation on quantized activation via SmoothQuant, which transfers the quantization difficulty from activations to weights to smooth activation outliers . Evaluation shows that SmoothQuant can preserve the accuracy of LLaMA3 at 8-bit and 6-bit weights and activations, but faces collapse at 4-bit.
Track 2: LoRA fine-tuned quantization
On the MMLU dataset, for LLaMA3-8B under LoRA-FT quantization, The most striking observation is that low-rank fine-tuning on the Alpaca dataset not only fails to compensate for the error introduced by quantization, but even makes the performance degradation more serious.
Specifically, the quantized LLaMA3 performance obtained by various LoRA-FT quantization methods at 4 bits is worse than the 4-bit corresponding version without LoRA-FT. This is in sharp contrast to similar phenomena on LLaMA1 and LLaMA2, where the 4-bit low-rank fine-tuned quantization version even easily outperforms the original FP16 counterpart on MMLU.
According to intuitive analysis, the main reason for this phenomenon is that the powerful performance of LLaMA3 benefits from its large-scale pre-training, which means that the performance loss after quantization of the original model cannot be passed on a small part of low-rank Fine-tuning is performed on the parameter data to compensate (this can be considered a subset of the original model).
Although the significant degradation caused by quantization cannot be compensated by fine-tuning, the 4-bit LoRA-FT quantized LLaMA3-8B significantly outperforms LLaMA1-7B and LLaMA2-7B under various quantization methods. For example, using the QLoRA method, the average accuracy of 4-bit LLaMA3-8B is 57.0 (FP16: 64.8), which exceeds the 38.4 of 4-bit LLaMA1-7B (FP16: 34.6) by 18.6, and exceeds the 43.9 of 4-bit LLaMA2-7B (FP16: 45.5 ) 13.1. This demonstrates the need for a new LoRA-FT quantization paradigm in the LLaMA3 era.
A similar phenomenon occurred in the CommonSenseQA benchmark. Model performance fine-tuned with QLoRA and IR-QLoRA also decreased compared to the 4-bit counterpart without LoRA-FT (e.g., 2.8% average decrease for QLoRA vs 2.4% average decrease for IR-QLoRA). This further demonstrates the advantage of using high-quality datasets in LLaMA3, and that the generic dataset Alpaca does not contribute to the model's performance in other tasks.
Conclusion
This paper comprehensively evaluates the performance of LLaMA3 in various low-bit quantization techniques, including post-training quantization and LoRA fine-tuned quantization.
This research finding shows that although LLaMA3 still exhibits superior performance after quantization, the performance drop associated with quantization is significant and can even lead to a larger drop in many cases.
This finding highlights the potential challenges that may be faced when deploying LLaMA3 in resource-constrained environments and highlights ample room for growth and improvement in the context of low-bit quantization. By solving the performance degradation caused by low-bit quantization, it is expected that subsequent quantization paradigms will enable LLMs to achieve stronger capabilities at lower computational costs, ultimately driving representative generative artificial intelligence to new heights.
Paper link: https://arxiv.org/abs/2404.14047.
Project link: https://github.com/Macaronlin/LLaMA3-Quantizationhttps://huggingface.co/LLMQ.
The above is the detailed content of Llama 3 low-bit quantization performance drops significantly! Comprehensive assessment results are here | HKU & Beihang University & ETH. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How to switch to Chinese on github
- What areas is artificial intelligence currently focusing on?
- What are the new features of artificial intelligence?
- How to check what the git password is
- Korean creators launch a large-scale boycott of AI comics, opposing infringement, misappropriation and illegal commercialization