
Home >Technology peripherals >AI >The 8B text multi-modal large model index is close to GPT4V. Byte, Huashan and Huake jointly proposed TextSquare
The 8B text multi-modal large model index is close to GPT4V. Byte, Huashan and Huake jointly proposed TextSquare

- PHPzforward
- 2024-04-25 18:16:011263browse

The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please submit an article or contact the reporting email. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Recently, multimodal large models (MLLM) have made significant progress in the field of text-centric VQA, especially multiple closed-source models, such as: GPT4V and Gemini , and even demonstrated performance beyond human capabilities in some aspects. However, the performance of open source models is still far behind closed source models. Recently, many groundbreaking studies, such as: MonKey, LLaVAR, TG-Doc, ShareGPT4V, etc., have begun to focus on the problem of insufficient instruction fine-tuning data. Although these efforts have achieved remarkable results, there are still some problems. Image description data and VQA data belong to different domains, and there are inconsistencies in the granularity and scope of image content presentation. Furthermore, the relatively small size of synthetic data prevents MLLM from realizing its full potential.

Paper title: TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Paper address: https ://arxiv.org/abs/2404.12803
To reduce this
VQA data generation
Square strategy approach It includes four steps: Self-Questioning, Self-Answering, Reasoning, and Self-Evaluation. Self-Questioning leverages MLLM's capabilities in text-image analysis and understanding to generate questions related to the text content in the image. Self-Answering provides answers to these questions using various prompting techniques such as: CoT and few-shot. Self-Reasoning uses the powerful reasoning capabilities of MLLMs to generate the reasoning process behind the model. Self-Evaluation improves data quality and reduces bias by evaluating questions for validity, relevance to image text content, and answer accuracy.
Based on the Square method, the researchers collected a diverse set of images containing a large amount of text from various public sources, including natural scenes, charts, forms, Square-10M was built using receipts, books, PPT, PDF, etc., and TextSquare-8B, an MLLM centered on text understanding, was trained based on this data set.
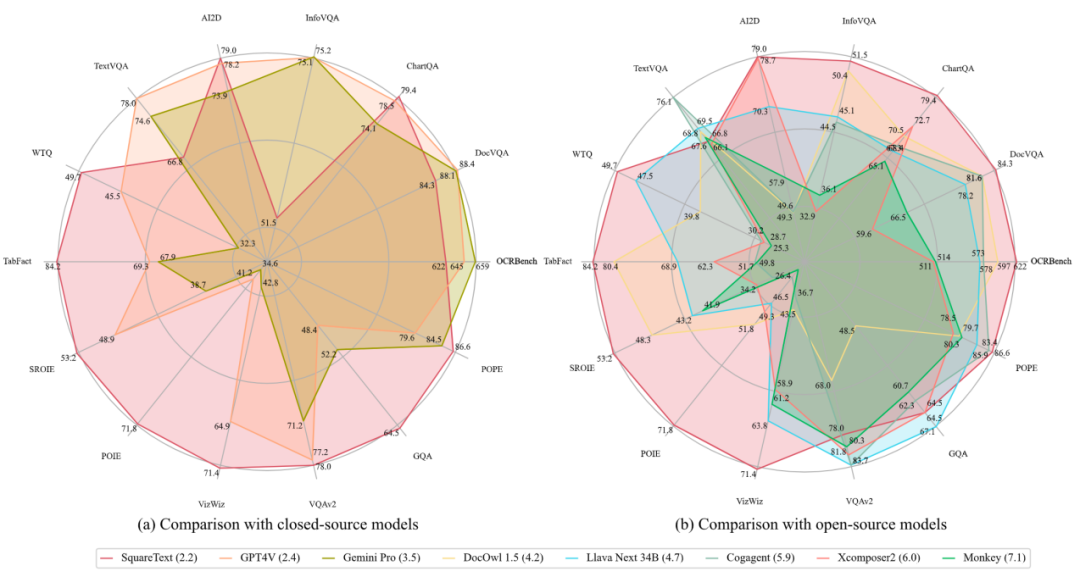
As shown in Figure 1, TextSquare-8B can achieve results comparable to or better than GPT4V and Gemini on multiple benchmarks, and significantly exceeds other open source models. TextSquare experiments verified the positive impact of inference data on the VQA task, demonstrating its ability to improve model performance while reducing hallucinations.
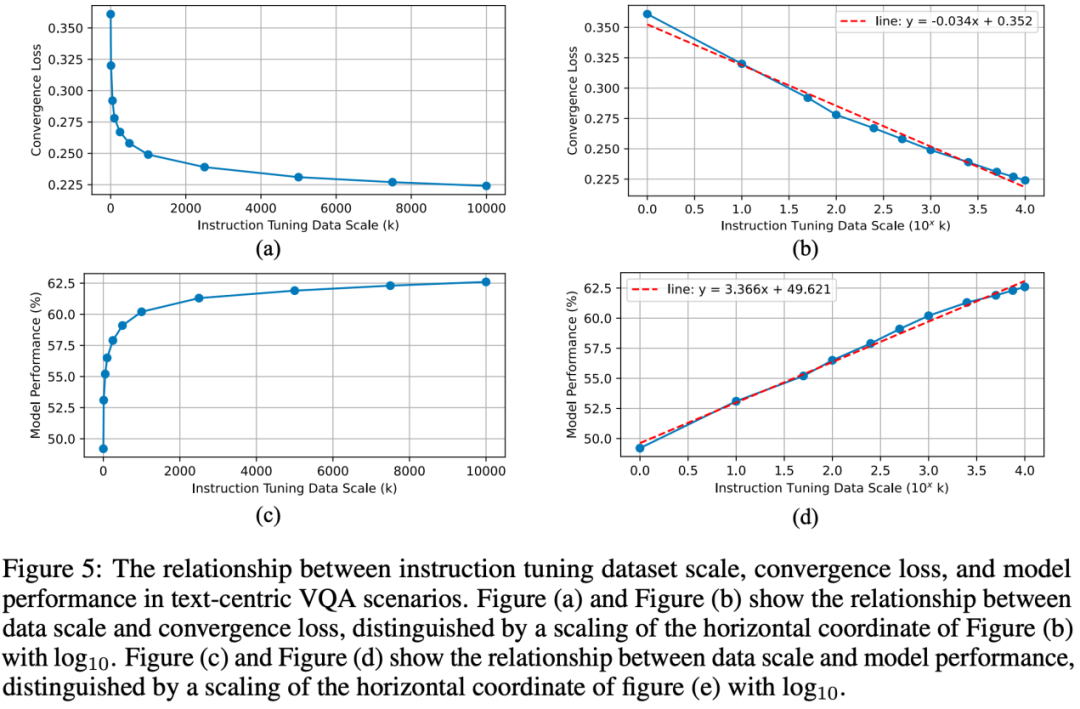
In addition, by utilizing large-scale data sets, the relationship between instruction adjustment data size, training convergence loss, and model performance is revealed. Although a small amount of instruction adjustment data can train MLLM well, as the instruction adjustment data continues to expand, the performance of the model can be further increased, and there is also a corresponding scaling law between the instruction fine-tuning data and the model.
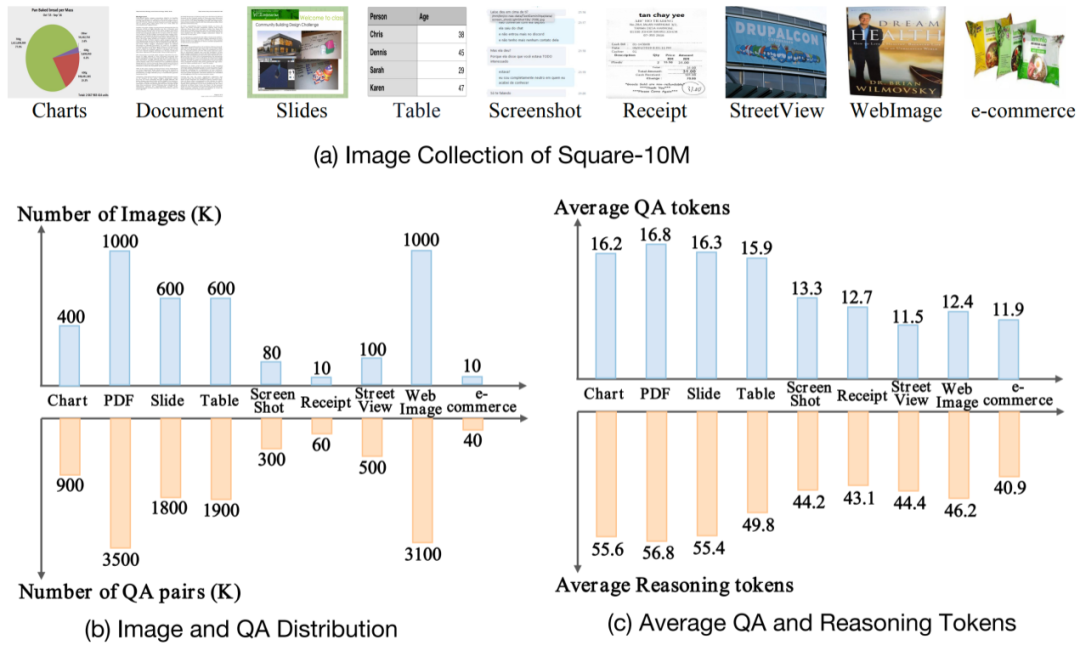
## 图 3 Square-10M image distribution and QA distribution and other details data collection
The main goal of the data collection strategy is to cover a wide range of real-world text-rich scenarios. To this end, the researchers collected 3.8 million text-rich images. These images exhibit different characteristics, for example, charts and tables focus on textual elements with dense statistical information; PPT, screenshots, and WebImages are designed for interaction between text and highlighted visual information; Documents/PDFs, receipts, and E-commerce contains images with detailed and dense text; street views are derived from natural scenes. The collected images form a mapping of textual elements in the real world and form the basis for studying text-centric VQA.
Data generation
Researchers use Gemini Pro's multi-modal understanding capabilities to select images from specific data sources and go through three stages of self-questioning, self-answering, and self-reasoning Generate VQA and inference context pairs.
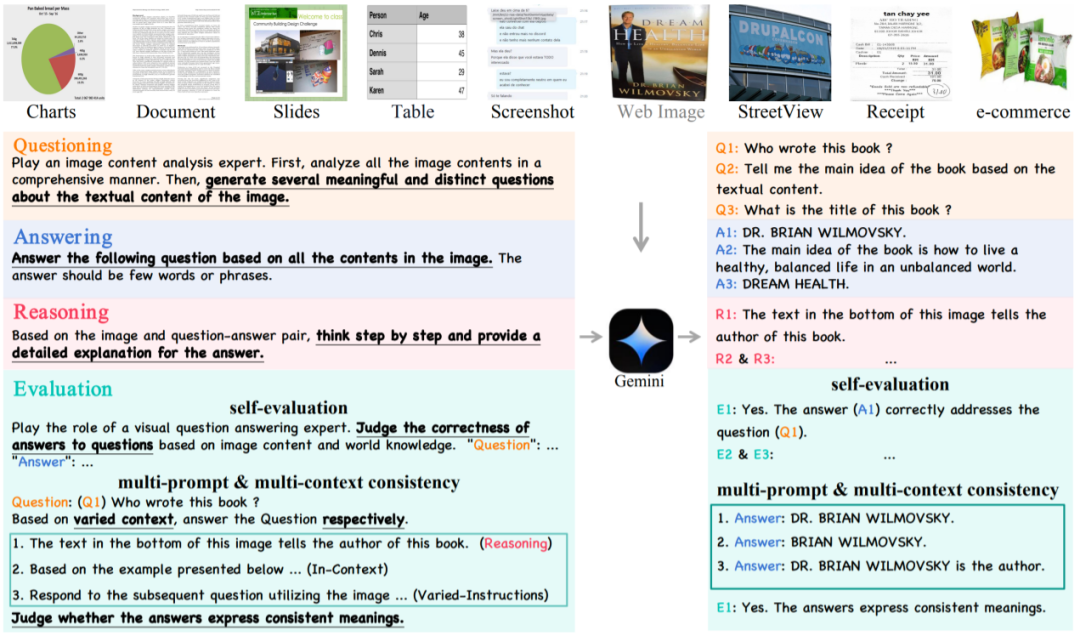
Self-Question: At this stage, some prompts will be given. Gemini Pro will conduct a comprehensive analysis of the image based on these prompts and generate some meaningful information based on the understanding. The problem. Considering that general MLLM's ability to understand text elements is usually weaker than that of visual models, we preprocess the extracted text into prompt through a specialized OCR model.
Self-Answering: Gemini Pro will use technologies such as chain of thought (CoT) and few-shot prompting to enrich contextual information when generating questions. Improve the reliability of generated answers.
Self-Reasoning: This stage will generate detailed reasons for the answer, forcing Gemini Pro to think more about the connection between the problem and the visual elements, thereby reducing illusions and improve accurate answers.
Data filtering
Although self-questioning, answering, and reasoning are valid, the generated image-text pairs may face illusory content, no Meaning questions and wrong answers. Therefore, we design filtering rules based on LLM's evaluation capabilities to select high-quality VQA pairs.
Self-Evaluation Tips Gemini Pro and other MLLMs determine whether the generated questions make sense and whether the answers are sufficient to correctly solve the problem.
Multi-Prompt Consistency In addition to directly evaluating the generated content, researchers also manually add prompts and context space in data generation. A correct and meaningful VQA pair should be semantically consistent when different prompts are provided.
Multi-Context Consistency The researcher further verified the VQA pair by preparing different context information before the question.
TextSquare-8B
TextSquare-8B draws on the model structure of InternLM-Xcomposer2, including the vision of CLIP ViT-L-14-336 Encoder, the image resolution is further increased to 700; a large language model LLM based on InternLM2-7B-ChatSFT; a bridge projector that aligns visual and text tokens.
TextSquare-8B’s training includes three stages of SFT:
The first stage fine-tunes the model with full parameters (Vision Encoder, Projector, LLM) at a resolution of 490.
In the second stage, the input resolution is increased to 700 and only the Vision Encoder is trained to adapt to the resolution change.
In the third stage, all parameters are further fine-tuned at a resolution of 700.
TextSquare confirms that based on the Square-10M dataset, a model with 8B parameters and normal-sized image resolution can achieve better than most MLLMs, even closed ones, on text-centric VQA. Effects of source models (GPT4V, Gemini Pro).
Experimental results
Figure 4(a) shows that TextSquare has simple arithmetic functions. Figure 4(b) shows the ability to understand text content and provide an approximate location in dense text. Figure 4(c) shows TextSquare’s ability to understand table structures.

MLLM Benchmark
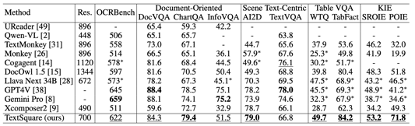
##Document-Oriented Benchmark has an average improvement of 3.5% on the VQA Benckmark (DocVQA, ChartQA, InfographicVQA) of the document scene, which is better than all open source models, and is slightly higher than GPT4V and Gemini Pro on the ChartQA data set. The resolution of this model is only 700, smaller than For most document-oriented MLLM, if the resolution is further improved, I believe the model performance will also be further improved, and Monkey has proven this.
Scene Text-centric Benchmark The SOTA effect has been achieved in the VQA Benchmark (TextVQA, AI2D) of natural scenes, but there is no major improvement compared with baseline Xcomposer2 , probably because Xcomposer2 has been fully optimized using high-quality in-domain data.
Table VQA Benchmark In the VQA Benchmark (WTQ, TabFact) of the table scenario, the results far exceed those of GPT4V and Gemini Pro, respectively exceeding other SOTA models by 3% .
Text-centric KIE Benchmark Extract the key information of the text center from the benchmark of the KIE task (SROIE, POIE), and convert the KIE task into a VQA task. In both data sets, The best performance was achieved, with an average improvement of 14.8%.
OCRBench Includes 29 OCR-related evaluation tasks such as text recognition, formula recognition, text-centered VQA, KIE, etc., achieving the best performance of the open source model, and Becoming the first model with a parameter volume of about 10B reaching 600 points.
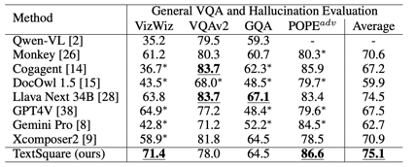
##General VQA and Hallucination Evaluation Benchmark In general VQA Benchmark (VizWiz VQAv2, GQA, TextSquare on POPE) has no significant degradation compared to Xconposer2 and still maintains the best performance. It shows significant performance on VisWiz and POPE, 3.6% higher than the best methods, which highlights the effectiveness of this method. sex, can reduce model hallucination.
Ablation experiment

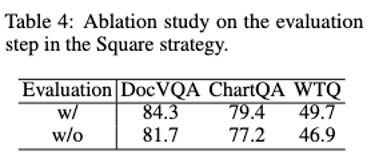
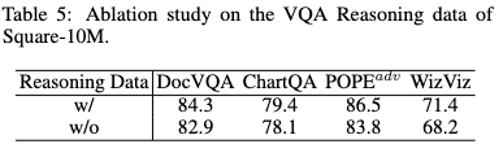
Data scale and convergence loss & model performance relationship
Summary
In this paper, the researchers proposed a Square strategy to build a high-quality text-centric instruction tuning data set (Square-10M). Using this dataset, TextSquare-8B achieves performance comparable to GPT4V on multiple benchmarks, and significantly outperforms recently released open source models on various benchmarks. In addition, the researchers derived the relationship between instruction adjustment data set size, convergence loss and model performance to pave the way for building larger data sets, confirming that the quantity and quality of data have an important impact on model performance. Crucial. Finally, the researchers pointed out that how to further improve the quantity and quality of data to narrow the gap between open source models and leading models is considered a highly promising research direction.The above is the detailed content of The 8B text multi-modal large model index is close to GPT4V. Byte, Huashan and Huake jointly proposed TextSquare. For more information, please follow other related articles on the PHP Chinese website!