
Home >Technology peripherals >AI >Transformer could be thinking ahead, but just doesn't do it
Transformer could be thinking ahead, but just doesn't do it

- PHPzforward
- 2024-04-22 17:22:07604browse
Will the language model plan for future tokens? This paper gives you the answer.
"Don't let Yann LeCun see it."
Yann LeCun said it was too late, he had already seen it. The question discussed in the "LeCun must-read" paper I will introduce today is: Is Transformer a thoughtful language model? When it performs inference at a certain location, does it anticipate subsequent locations?
The conclusion of this study is: Transformer has the ability to do this, but does not do so in practice.
We all know that humans think before they speak. Ten years of linguistic research shows that when humans use language, they mentally predict the upcoming language input, words or sentences.
Unlike humans, current language models allocate a fixed amount of calculation to each token when "speaking". So we can’t help but ask: Will language models think in advance like humans?
According to some recent research, it has been shown that the next token can be predicted by probing the hidden state of the language model. Interestingly, by using linear probes on the model's hidden states, the model's output on future tokens can be predicted to a certain extent, and future outputs can be modified predictably. Some recent research has shown that it is possible to predict the next token by probing the hidden states of a language model. Interestingly, by using linear probes on the model's hidden states, the model's output on future tokens can be predicted to a certain extent, and future outputs can be modified predictably.
These findings suggest that model activation at a given time step is at least partially predictive of future output.
However, we don't yet know why: is this just an accidental property of the data, or is it because the model deliberately prepares information for future time steps (but this affects the model's performance at the current location)?
In order to answer this question, three researchers from the University of Colorado Boulder and Cornell University recently published an article titled "Will Language Models Plan for Future Tokens?" 》Thesis.

Paper title: Do Language Models Plan for Future Tokens?
Paper address: https://arxiv.org/pdf/2404.00859.pdf
Research Overview
They observed that the gradient during training optimizes the weights both for the loss at the current token position and for tokens later in the sequence. They further asked: In what proportion will the current transformer weight allocate resources to the current token and future tokens?
They considered two possibilities: the pre-caching hypothesis and the breadcrumbs hypothesis.

The pre-caching hypothesis means that the transformer will calculate at time step t features that are irrelevant to the inference task of the current time step but may be useful for future time steps t τ , while breadcrumbs The assumption is that the features most relevant at time step t are already equivalent to the features that will be most useful at time step t τ .
To evaluate which hypothesis is correct, the team proposed a myopic training scheme that does not propagate the gradient of the loss at the current position to the hidden state at the previous position.
For the mathematical definition and theoretical description of the above assumptions and schemes, please refer to the original paper.
Experimental results
To understand whether it is possible for language models to directly implement precaching, they designed a synthetic scenario in which the task can only be accomplished through explicit precaching . They configured a task in which the model had to precompute information for the next token, otherwise it would not be able to accurately calculate the correct answer in a single pass.

# definition of the synthetic data set built by the team.
In this synthetic scene, the team found clear evidence that transformers can learn to pre-cache. Transformer-based sequence models do this when they must precompute information to minimize loss. They then explored whether natural language models (pretrained GPT-2 variants) would exhibit the breadcrumb hypothesis or the precaching hypothesis. Their experiments with myopic training schemes show that precaching occurs much less often in this setting, so the results are more biased towards the breadcrumb hypothesis.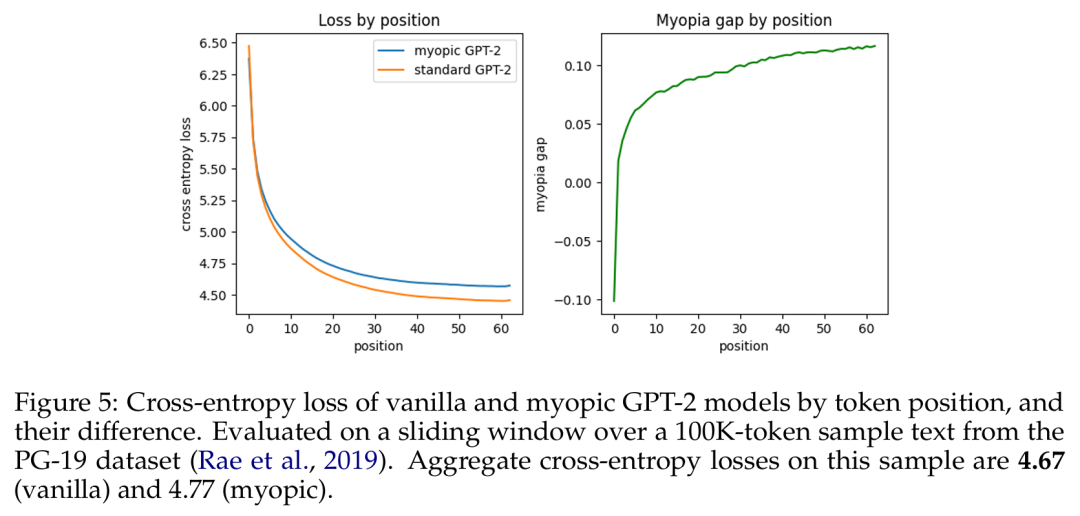
been been been made. The cross-entropy loss and differences between the original GPT-2 model based on token position and the short-sighted GPT-2 model.
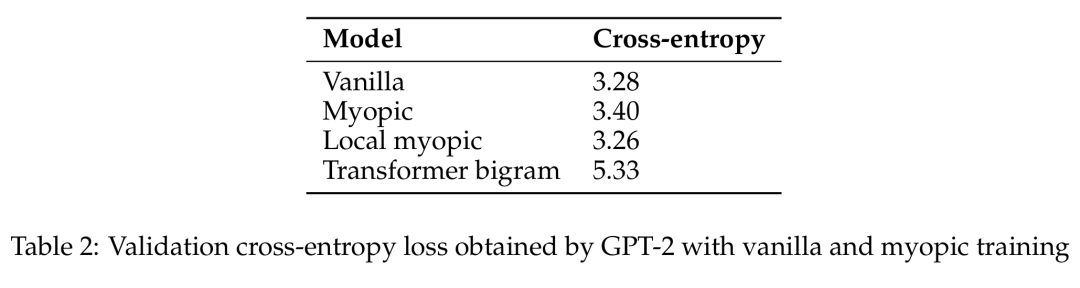
# .
So the team claims: On real language data, language models do not prepare future information to a significant extent. Instead, they are computing features that are useful for predicting the next token — which will also prove useful for future steps.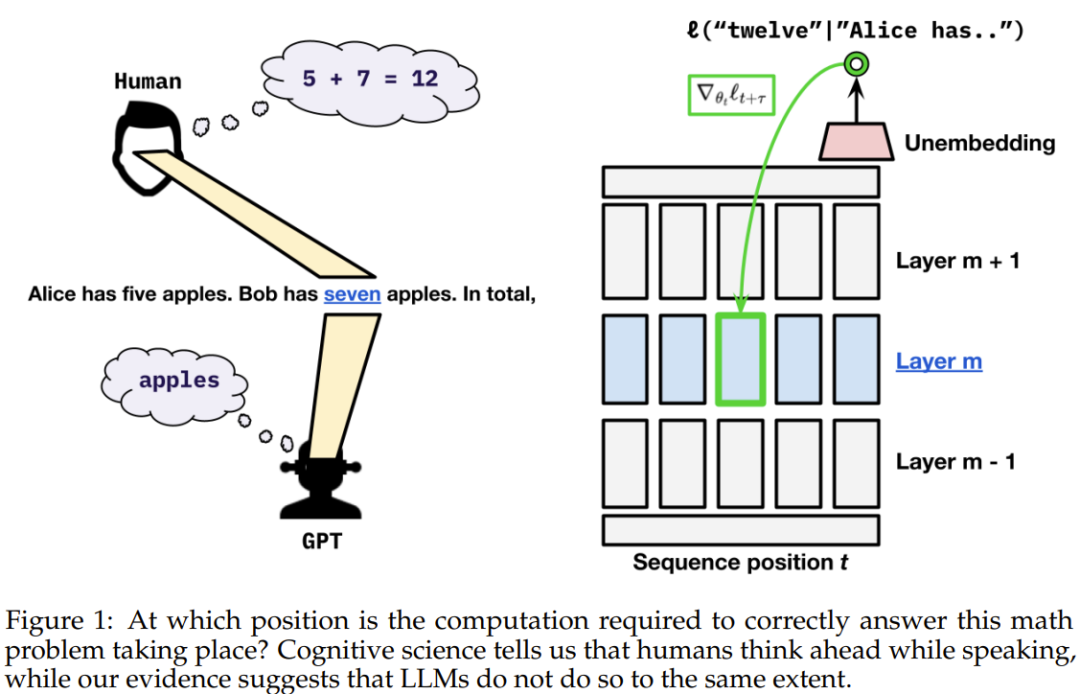

The above is the detailed content of Transformer could be thinking ahead, but just doesn't do it. For more information, please follow other related articles on the PHP Chinese website!