
Home >Backend Development >Python Tutorial >Detailed explanation of the theoretical basis of neural network and Python implementation method
Detailed explanation of the theoretical basis of neural network and Python implementation method

- 小云云Original
- 2017-12-18 10:44:082130browse
Artificial neural network is an algorithmic mathematical model that imitates the behavioral characteristics of animal neural networks and performs distributed parallel information processing. This kind of network relies on the complexity of the system to achieve the purpose of processing information by adjusting the interconnected relationships between a large number of internal nodes, and has the ability to self-learn and adapt. This article mainly introduces the theoretical basis of neural network and the detailed explanation of Python implementation. It has certain reference value. Friends in need can refer to it. I hope it can help everyone.
1. Multi-layer forward neural network
The multi-layer forward neural network consists of three parts: output layer, hidden layer, output layer Layer, each layer is composed of units;
The input layer is passed in from the instance feature vector of the training set, and passed to the next layer through the weight of the connection node. The output of the previous layer is the input of the next layer; The number of hidden layers is arbitrary, there is only one input layer, and there is only one output layer;
Excluding the input layer, the sum of the number of hidden layers and output layers is n, then the neural network It is called an n-layer neural network. The following figure shows a 2-layer neural network;
The weighted summation in one layer is transformed and output according to the nonlinear equation; in theory, if there are enough hidden layers and a large enough The training set can simulate any equation;
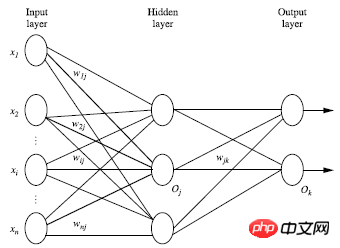
2. Design the neural network structure
Use Before the neural network, the number of layers of the neural network and the number of units in each layer must be determined;
In order to speed up the learning process, the feature vector usually needs to be standardized to between 0 and 1 before being passed to the input layer. ;
Discrete variables can be encoded into values that may be assigned to each input unit corresponding to an eigenvalue
For example: eigenvalue A may have three values (a0, a1, a2), Then you can use 3 input units to represent A
If A=a0, the unit value representing a0 is 1, and the rest are 0;
If A=a1, the unit value representing a1 is 1, The rest is 0;
If A=a2, the unit value representing a2 is 1, and the rest is 0;

Neural network not only solves the classification problem, It can also solve regression problems. For classification problems, if there are two categories, one output unit (0 and 1) can be used to represent the two categories respectively; if there are more than two categories, each category is represented by one output unit, so the number of units in the output layer is usually equal to one category. quantity.
There are no clear rules to design the optimal number of hidden layers. Experiments are generally improved based on experimental test errors and accuracy.
3. Cross-validation method
How to calculate the accuracy? The simplest method is to use a set of training sets and test sets. The training set is trained to obtain the model. The test set is input into the model to obtain the test results. The test results are compared with the real labels of the test set to obtain the accuracy.
A commonly used method in the field of machine learning is the cross-validation method. A set of data is not divided into 2 parts, but may be divided into 10 parts.
The 1st time: the 1st part is used as the test set, and the remaining 9 parts are used as the training set;
The 2nd time: the 2nd part is used as the test set set, and the remaining 9 sets are used as training sets;
...
After 10 times of training, 10 sets of accuracy are obtained, and the average accuracy of these 10 sets of data is obtained. Here 10 is a special case. In a general sense, the data is divided into k parts, and the algorithm is called K-foldcrossvalidation. That is, each time one of the k parts is selected as the test set, and the remaining k-1 parts are used as the training set. Repeat k times, and finally the average accuracy is obtained. , is a more scientific and accurate method.

4. BP algorithm
Process instances in the training set through iteration;
Compare the difference between the predicted value and the true value after passing through the neural network;
In the reverse direction (from the output layer=>hidden layer=>input layer) to minimize the error, update each connection The weight of
Initialize weights and biases: Randomly initialize between -1 and 1 (or other), each unit has a bias; for each training instance X, perform the following steps: 1. From the input Layer forward transmission:
Combined with the neural network schematic diagram for analysis:


Summarizing the two formulas, we can get:

Ij is the unit value of the current layer, and Oi is the unit of the previous layer. value, wij is the weight value connecting the two unit values between the two layers, and sitaj is the bias value of each layer. We need to perform nonlinear transformation on the output of each layer. The schematic diagram is as follows:

#The output of the current layer is Ij, and f is the nonlinear transformation function, also known as the activation function. , defined as follows:

That is, the output of each layer is:

In this way, the input value can be forwarded Get the output value of each layer.
2. Reverse propagation according to the error. For the output layer: where Tk is the real value and Ok is the predicted value

For the hidden layer:

Weight update: where l is the learning rate

Bias update:

The predicted error rate is lower than a certain threshold;
The preset number of cycles is reached;
tanh(x)=sinh(x)/cosh(x)
sinh(x)=(exp(x)-exp(-x))/2
cosh(x)=(exp( x)+exp(-x))/2
5. Python implementation of BP neural network
You need to import the numpy module firstimport numpy as npDefine the nonlinear transformation function, because you also need to use the function Derivative form, so define together
def tanh(x): return np.tanh(x) def tanh_deriv(x): return 1.0 - np.tanh(x)*np.tanh(x) def logistic(x): return 1/(1 + np.exp(-x)) def logistic_derivative(x): return logistic(x)*(1-logistic(x))To design the form of BP neural network (how many layers, how many units in each layer), object-oriented is used, mainly Which nonlinear function to choose, and initialize the weights. Layers is a list containing the number of units in each layer.
class NeuralNetwork:
def __init__(self, layers, activation='tanh'):
"""
:param layers: A list containing the number of units in each layer.
Should be at least two values
:param activation: The activation function to be used. Can be
"logistic" or "tanh"
"""
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
for i in range(1, len(layers) - 1):
self.weights.append((2*np.random.random((layers[i - 1] + 1, layers[i] + 1))-1)*0.25)
self.weights.append((2*np.random.random((layers[i] + 1, layers[i + 1]))-1)*0.25)
Implement algorithm
def fit(self, X, y, learning_rate=0.2, epochs=10000):
X = np.atleast_2d(X)
temp = np.ones([X.shape[0], X.shape[1]+1])
temp[:, 0:-1] = X
X = temp
y = np.array(y)
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]]
for l in range(len(self.weights)):
a.append(self.activation(np.dot(a[l], self.weights[l])))
error = y[i] - a[-1]
deltas = [error * self.activation_deriv(a[-1])]
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[-1].dot(self.weights[l].T)*self.activation_deriv(a[l]))
deltas.reverse()
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)
Implement prediction
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0]+1)
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a
We give a set of numbers for prediction. The program file we saved above is named BP
from BP import NeuralNetwork import numpy as np nn = NeuralNetwork([2,2,1], 'tanh') x = np.array([[0,0], [0,1], [1,0], [1,1]]) y = np.array([1,0,0,1]) nn.fit(x,y,0.1,10000) for i in [[0,0], [0,1], [1,0], [1,1]]: print(i, nn.predict(i))The results are as follows :
([0, 0], array([ 0.99738862])) ([0, 1], array([ 0.00091329])) ([1, 0], array([ 0.00086846])) ([1, 1], array([ 0.99751259]))Related recommendations:
Examples of numpy’s flexible definition of neural network structures in Python
Sharing a simple example of implementing a recursive neural network in Python
Detailed graphic and text explanation of implementing a simple neural network algorithm in JavaScript
The above is the detailed content of Detailed explanation of the theoretical basis of neural network and Python implementation method. For more information, please follow other related articles on the PHP Chinese website!