

 Technology peripheralsAIGoogle takes action to rectify the 'amnesia' of large models! The feedback attention mechanism helps you 'update' the context, and the era of unlimited memory for large models is coming.
Technology peripheralsAIGoogle takes action to rectify the 'amnesia' of large models! The feedback attention mechanism helps you 'update' the context, and the era of unlimited memory for large models is coming.
Editor | Yi Feng
produced | 51CTO technology stack (WeChat ID: blog51cto)
Google finally took action! We will no longer suffer from the "amnesia" of large models.
TransformerFAM was born, promising to make large models have unlimited memory!
Without further ado, let’s take a look at the “efficacy” of TransformerFAM:
 Picture
Picture
The large model is processing long context tasks Performance has been significantly improved!
In the above figure, tasks such as Isabelle and NarrativeQA require the model to understand and process a large amount of contextual information and give accurate answers or summaries to specific questions. In all tasks, the model configured with FAM outperforms all other BSWA configurations, and it can be seen that beyond a certain point, the increase in the number of BSWA memory segments cannot continue to improve its memory capabilities.
It seems that on the way to long texts and long conversations, the "unforgettable" of FAM, a big model, does have something to it.
Google researchers introduced FAM, a novel Transformer architecture - Feedback Attention Memory. It uses feedback loops to enable the network to pay attention to its own drift performance, promote the emergence of the Transformer's internal working memory, and enable it to handle infinitely long sequences.
To put it simply, this strategy is a bit like our strategy to artificially combat the "amnesia" of large models: enter the prompt again before each conversation with the large model. It's just that FAM's approach is more advanced. When the model processes a new data block, it will use the previously processed information (that is, FAM) as a dynamically updated context and integrate it into the current processing process again.
In this way, you can well deal with the problem of "forgetting things". Even better, despite the introduction of feedback mechanisms to maintain long-term working memory, FAM is designed to maintain compatibility with pre-trained models without requiring additional weights. So in theory, the powerful memory of the large model does not make it dull or consume more computing resources.
So, how was such a wonderful TransformerFAM discovered? What are the related technologies?
1. From the perspective of challenges, why can TransformerFAM help large models “remember more”?
The concept of Sliding Window Attention (SWA) is crucial to the design of TransformerFAM.
In the traditional Transformer model, the complexity of self-attention (Self-Attention) increases quadratically as the length of the sequence increases, which limits the model's ability to handle long sequences.
"In the movie Memento (2000), the main character suffers from anterograde amnesia, which means he cannot remember what happened in the past 10 minutes, but his long-term memory is intact , he had to tattoo important information on his body to remember them, similar to the current state of large language models (LLMs)," the paper reads.
 Screenshots from the movie "Memory", the pictures come from the Internet
Screenshots from the movie "Memory", the pictures come from the Internet
Sliding Window Attention (Sliding Window Attention), it is an improved attention Mechanism for processing long sequence data. It is inspired by the sliding window technique in computer science. When dealing with natural language processing (NLP) tasks, SWA allows the model to focus on only a fixed-size window of the input sequence at each time step, rather than the entire sequence. Therefore, the advantage of SWA is that it can significantly reduce the computational effort.
 Picture
Picture
However, SWA has limitations because its attention span is limited to the window size, which results in the model being unable to consider outside the window. Important information.
TransformerFAM achieves integrated attention, block-level updates, information compression, and global context storage by adding feedback activation to re-input context representation into each block of sliding window attention.
In TransformerFAM, improvements are achieved through feedback loops. Specifically, when processing the current sequence block, the model not only focuses on elements within the current window, but also reintroduces previously processed contextual information (i.e., previous "feedback activation") as additional input into the attention mechanism. In this way, even if the model's attention window slides over the sequence, it is able to maintain memory and understanding of previous information.
So, after these improvements, TransformerFAM gives LLMs the potential to handle infinite length sequences!
2. 作業記憶の大規模モデルを使用して、AGI への移行を継続します
TransformerFAM は研究で前向きな見通しを示しており、これにより AI の長いテキスト タスクの理解と生成の能力が向上することは間違いありません。処理などのパフォーマンスが向上します。文書の要約、ストーリーの作成、Q&A など。
 写真
写真
同時に、それがインテリジェントなアシスタントであれ、感情的なパートナーであれ、無制限のメモリを持つ AI はより魅力的に聞こえます。
興味深いことに、TransformerFAM の設計は生物学の記憶メカニズムに触発されており、AGI が追求する自然知能シミュレーションと一致しています。この論文は、神経科学の概念である注意ベースの作業記憶を深層学習の分野に統合する試みです。
TransformerFAM は、フィードバック ループを通じて大規模なモデルに作業記憶を導入し、モデルが短期的な情報を記憶するだけでなく、長期シーケンスにおける重要な情報の記憶を維持できるようにします。
研究者は、大胆な想像力を通じて、現実世界と抽象概念の間に仮説的な橋を架けます。 TransformerFAM のような革新的な成果が生まれ続けるにつれて、技術的なボトルネックは何度も突破され、よりインテリジェントで相互接続された未来がゆっくりと私たちに向かって展開されています。
AIGC の詳細については、次のサイトをご覧ください:
51CTO AI.x コミュニティ
https://www.51cto.com/aigc/
The above is the detailed content of Google takes action to rectify the 'amnesia' of large models! The feedback attention mechanism helps you 'update' the context, and the era of unlimited memory for large models is coming.. For more information, please follow other related articles on the PHP Chinese website!

 Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AM
Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AMRevolutionizing the Checkout Experience Sam's Club's innovative "Just Go" system builds on its existing AI-powered "Scan & Go" technology, allowing members to scan purchases via the Sam's Club app during their shopping trip.
 Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AM
Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AMNvidia's Enhanced Predictability and New Product Lineup at GTC 2025 Nvidia, a key player in AI infrastructure, is focusing on increased predictability for its clients. This involves consistent product delivery, meeting performance expectations, and
 Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AM
Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AMGoogle's Gemma 2: A Powerful, Efficient Language Model Google's Gemma family of language models, celebrated for efficiency and performance, has expanded with the arrival of Gemma 2. This latest release comprises two models: a 27-billion parameter ver
 The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AM
The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AMThis Leading with Data episode features Dr. Kirk Borne, a leading data scientist, astrophysicist, and TEDx speaker. A renowned expert in big data, AI, and machine learning, Dr. Borne offers invaluable insights into the current state and future traje
 AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AM
AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AMThere were some very insightful perspectives in this speech—background information about engineering that showed us why artificial intelligence is so good at supporting people’s physical exercise. I will outline a core idea from each contributor’s perspective to demonstrate three design aspects that are an important part of our exploration of the application of artificial intelligence in sports. Edge devices and raw personal data This idea about artificial intelligence actually contains two components—one related to where we place large language models and the other is related to the differences between our human language and the language that our vital signs “express” when measured in real time. Alexander Amini knows a lot about running and tennis, but he still
 Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AM
Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AMCaterpillar's Chief Information Officer and Senior Vice President of IT, Jamie Engstrom, leads a global team of over 2,200 IT professionals across 28 countries. With 26 years at Caterpillar, including four and a half years in her current role, Engst
 New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AM
New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AMGoogle Photos' New Ultra HDR Tool: A Quick Guide Enhance your photos with Google Photos' new Ultra HDR tool, transforming standard images into vibrant, high-dynamic-range masterpieces. Ideal for social media, this tool boosts the impact of any photo,
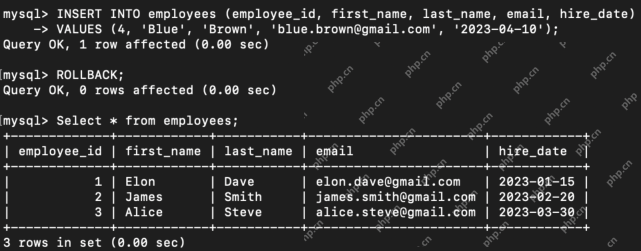 What are the TCL Commands in SQL? - Analytics VidhyaApr 22, 2025 am 11:07 AM
What are the TCL Commands in SQL? - Analytics VidhyaApr 22, 2025 am 11:07 AMIntroduction Transaction Control Language (TCL) commands are essential in SQL for managing changes made by Data Manipulation Language (DML) statements. These commands allow database administrators and users to control transaction processes, thereby


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SublimeText3 Mac version
God-level code editing software (SublimeText3)

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

Atom editor mac version download
The most popular open source editor

