
 Technology peripheralsAIWho says elephants can't dance! Reprogramming large language models to achieve timing prediction of cross-modal interactions | ICLR 2024
Technology peripheralsAIWho says elephants can't dance! Reprogramming large language models to achieve timing prediction of cross-modal interactions | ICLR 2024Who says elephants can't dance! Reprogramming large language models to achieve timing prediction of cross-modal interactions | ICLR 2024

Recently, researchers from Monash University in Australia, Ant Group, IBM Research and other institutions have explored the application of model reprogramming (model reprogramming) on large language models (LLMs), and proposed a new perspective: Efficient reprogramming of large language models for general time series forecasting systems, the Time-LLM framework. This framework can achieve high-precision and efficient predictions without modifying the language model, and can surpass traditional time series models in multiple data sets and prediction tasks, allowing LLMs to demonstrate outstanding performance when processing cross-modal time series data. Like an elephant dancing.

Recently, with the development of large language models in the field of general intelligence, the new direction of "large model time series/time data" has shown many related developments. Current LLMs have the potential to revolutionize time series/temporal data mining methods, thereby promoting efficient decision-making in classic complex systems such as cities, energy, transportation, health, etc., and moving towards more universal intelligent forms of time/space analysis.
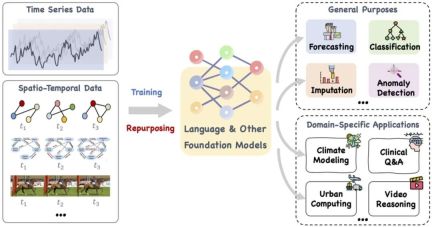
This paper proposes a large base model, such as language and other related models, that can be trained and also cleverly retuned Purpose to process time series and time-spatial data for a range of general-purpose tasks and domain-specific applications. Reference: https://arxiv.org/pdf/2310.10196.pdf.
Recent research has expanded large-scale language models from processing natural language to time series and spatio-temporal tasks. This new research direction, namely "large model time series / spatiotemporal data", has produced many related developments, such as LLMTime, which directly utilizes LLMs for zero-shot time series predictive inference. Although LLMs have powerful learning and expression capabilities and can effectively capture complex patterns and long-term dependencies in text sequence data, as a "black box" focused on processing natural language, the application of LLMs in time series and spatiotemporal tasks is still face the challenge. Compared with traditional time series models such as TimesNet, TimeMixer, etc., LLMs are comparable to "elephant" due to their huge parameters and scale.
What you are asking is how to "tame" such large language models (LLMs) trained in the field of natural language so that they can process numerical sequence data across text patterns and perform in time series and spatiotemporal tasks. Developing powerful reasoning and prediction capabilities has become a key focus of current research. To this end, more in-depth theoretical analysis is needed to explore potential pattern similarities between linguistic and temporal data and effectively apply them to specific time series and spatiotemporal tasks.
LLM Reprogramming model (LLM Reprogramming) is a general time series prediction technology. It proposes two key technologies, namely (1) temporal input reprogramming and (2) prompt pre-programming, which converts the temporal prediction task into a "language" task that can be effectively solved by LLMs, successfully activating large language models to achieve high performance. Ability to perform precise timing reasoning.

Paper address: https://openreview.net/pdf?id=Unb5CVPtae
Paper code: https://github.com/KimMeen/ Time-LLM
1. Problem background
Time series data is widely stored in reality, in which time series prediction is of great significance in many real-world dynamic systems , and has also been extensively studied. Unlike natural language processing (NLP) and computer vision (CV), where a single large model can handle multiple tasks, time series prediction models often need to be specially designed to meet the needs of different tasks and application scenarios. Recent research has shown that large language models (LLMs) are also reliable when processing complex temporal sequences. It is still a challenge to utilize the reasoning capabilities of large language models themselves to handle temporal analysis tasks.
2. Paper Overview
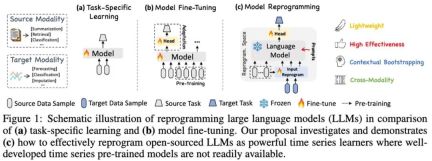
In this work, the author proposes Time-LLM, which is a general The language model reprogramming (LLM Reprogramming) framework can easily use LLM for general time series prediction without any training on the large language model itself. Time-LLM first uses text prototypes (Text Prototypes) to reprogram the input time series data, and uses natural language representation to represent the semantic information of the time series data, thereby aligning two different data modalities, so that the large language model does not require any modification. You can understand the information behind another data modality.
In order to further enhance LLM's understanding of input time series data and corresponding tasks, the author proposed the prompt-as-prefix (PaP) paradigm. By adding additional contextual prompts and task instructions before the time series data representation, Fully activate LLM's processing capabilities on timing tasks. In this work, the author conducted sufficient experiments on mainstream time series benchmark data sets, and the results showed that Time-LLM can surpass the traditional time series model in most cases and achieve better performance in few-shot and zero-shot samples. The sample (zero-shot) learning task has been greatly improved.
The main contributions in this work can be summarized as follows:
1. This work proposes a new concept of reprogramming large language models for timing analysis without having to do any modifications to the backbone language model. Any modifications. The authors show that time series prediction can be considered as another "linguistic" task that can be effectively solved by off-the-shelf LLMs.
2. This work proposes a general language model reprogramming framework, namely Time-LLM, which consists of reprogramming input temporal data into a more natural text prototype representation, and through declarative prompts such as domain expert knowledge and task description) to enhance the input context to guide LLM for effective cross-domain reasoning. This technology provides a solid foundation for the development of multimodal timing basic models.
3. Time-LLM consistently outperforms the best existing model performance in mainstream prediction tasks, especially in few-sample and zero-sample scenarios. Furthermore, Time-LLM is able to achieve higher performance while maintaining excellent model reprogramming efficiency. Dramatically unlock the untapped potential of LLM for time series and other sequential data.
3. Model framework
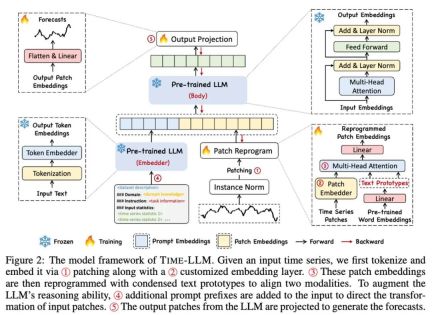
#As shown in ① and ② in the model framework diagram above, the input time series data is first refined through RevIN. The unification operation is then divided into different patches and mapped to the latent space.
There are significant differences in expression methods between time series data and text data, and they belong to different modalities. Time series can neither be directly edited nor described losslessly in natural language, which poses a significant challenge to directly prompting LLM to understand time series. Therefore, we need to align temporal input features to the natural language text domain.
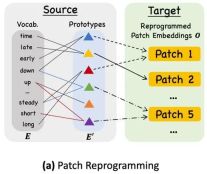
A common method to align different modalities is cross-attention. As shown in ③ in the model framework diagram, you only need to make an embedding and timing input feature of all words. cross-attention (where the time series input feature is Query, and the embedding of all words is Key and Value). However, the inherent vocabulary of LLM is very large, so it cannot effectively directly align temporal features to all words, and not all words have aligned semantic relationships with time series. In order to solve this problem, this work performs a linear combination of vocabulary to obtain text prototypes. The number of text prototypes is much smaller than the original vocabulary. The combination can be used to represent the changing characteristics of time series data, such as "a brief rise or a slow decline." ",As shown in FIG.
In order to fully activate the ability of LLM on specified timing tasks, this work proposes a prompt prefixing paradigm, which is a simple and effective method, as shown in ④ in the model framework diagram. Recent advances have shown that other data patterns such as images can be seamlessly integrated into the prefix of cues, allowing efficient inference based on these inputs. Inspired by these findings, the authors, in order to make their method directly applicable to real-world time series, pose an alternative question: Can hints serve as prefix information to enrich the input context and guide the transformation of reprogrammed time series patches? This concept is called Prompt-as-Prefix (PaP), and furthermore, the authors observed that it significantly improves the adaptability of LLM to downstream tasks while complementing patch reprogramming. In layman's terms, it means feeding some prior information of the time series data set in the form of natural language as a prefix prompt, and splicing it with the aligned time series features to LLM. Can it improve the prediction effect?

The picture above shows two prompt methods. In Patch-as-Prefix, a language model is prompted to predict subsequent values in a time series, expressed in natural language. This approach encounters some constraints: (1) Language models often exhibit low sensitivity when processing high-precision numbers without the assistance of external tools, which brings significant challenges to accurate processing of long-term prediction tasks; (2) Complex customized post-processing is required for different language models because they are pre-trained on different corpora and may employ different word segmentation types when generating high-precision numbers. This results in predictions being represented in different natural language formats, such as [‘0’, ‘.’, ‘6’, ‘1’] and [‘0’, ‘.’, ‘61’], which represents 0.61.
In practice, the authors identified three key components for building effective prompts: (1) dataset context; (2) task instructions to adapt LLM to different downstream tasks; (3) statistical description, For example, trends, time delays, etc. allow LLM to better understand the characteristics of time series data. The image below gives an example of a prompt.

#4. Experimental results
We conducted comprehensive tests on 8 classic public data sets for long-range prediction. As shown in the table below, Time-LLM significantly exceeds the previous best results in the field in the benchmark comparison. In addition, compared with GPT4TS that directly uses GPT-2, Time-LLM adopts the reprogramming idea and Prompt-as-Prefix. There is also a significant improvement, indicating the effectiveness of this method.
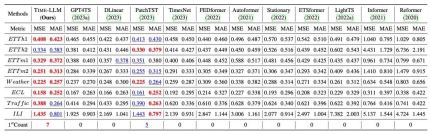
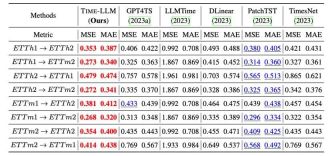
In addition, we evaluate the zero-shot zero-shot learning ability of reprogrammed LLM within the framework of cross-domain adaptation. Thanks to the ability of reprogramming, we fully activate It improves the prediction ability of LLM in cross-domain scenarios. As shown in the table below, Time-LLM also shows extraordinary prediction effects in zero-shot scenarios.
5. Summary
The rapid development of large language models (LLMs) has greatly promoted the application of artificial intelligence in cross-modal scenarios. progress and promote their wide application in many fields. However, the large parameter scale of LLMs and their design mainly for natural language processing (NLP) scenarios bring many challenges to their cross-modal and cross-domain applications. In view of this, we propose a new idea for reprogramming large models, aiming to achieve cross-modal interaction between text and sequence data, and widely apply this method to processing large-scale time series and spatiotemporal data. In this way, we hope to make LLMs like flexibly dancing elephants, able to demonstrate their powerful capabilities in a wider range of application scenarios.
Interested friends are welcome to read the paper (https://arxiv.org/abs/2310.01728) or visit the project page (https://github.com/KimMeen/Time-LLM) to learn more.
This project has received full support from NextEvo, the AI innovation R&D department of Ant Group’s Intelligent Engine Division, especially thanks to the close collaboration between the language and machine intelligence team and the optimization intelligence team. Under the leadership and guidance of Zhou Jun, Vice President of the Intelligent Engine Division, and Lu Xingyu, Head of the Optimization Intelligence Team, we worked together to successfully complete this important achievement.
The above is the detailed content of Who says elephants can't dance! Reprogramming large language models to achieve timing prediction of cross-modal interactions | ICLR 2024. For more information, please follow other related articles on the PHP Chinese website!

 AI Therapists Are Here: 14 Groundbreaking Mental Health Tools You Need To KnowApr 30, 2025 am 11:17 AM
AI Therapists Are Here: 14 Groundbreaking Mental Health Tools You Need To KnowApr 30, 2025 am 11:17 AMWhile it can’t provide the human connection and intuition of a trained therapist, research has shown that many people are comfortable sharing their worries and concerns with relatively faceless and anonymous AI bots. Whether this is always a good i
 Calling AI To The Grocery AisleApr 30, 2025 am 11:16 AM
Calling AI To The Grocery AisleApr 30, 2025 am 11:16 AMArtificial intelligence (AI), a technology decades in the making, is revolutionizing the food retail industry. From large-scale efficiency gains and cost reductions to streamlined processes across various business functions, AI's impact is undeniabl
 Getting Pep Talks From Generative AI To Lift Your SpiritApr 30, 2025 am 11:15 AM
Getting Pep Talks From Generative AI To Lift Your SpiritApr 30, 2025 am 11:15 AMLet’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI including identifying and explaining various impactful AI complexities (see the link here). In addition, for my comp
 Why AI-Powered Hyper-Personalization Is A Must For All BusinessesApr 30, 2025 am 11:14 AM
Why AI-Powered Hyper-Personalization Is A Must For All BusinessesApr 30, 2025 am 11:14 AMMaintaining a professional image requires occasional wardrobe updates. While online shopping is convenient, it lacks the certainty of in-person try-ons. My solution? AI-powered personalization. I envision an AI assistant curating clothing selecti
 Forget Duolingo: Google Translate's New AI Feature Teaches LanguagesApr 30, 2025 am 11:13 AM
Forget Duolingo: Google Translate's New AI Feature Teaches LanguagesApr 30, 2025 am 11:13 AMGoogle Translate adds language learning function According to Android Authority, app expert AssembleDebug has found that the latest version of the Google Translate app contains a new "practice" mode of testing code designed to help users improve their language skills through personalized activities. This feature is currently invisible to users, but AssembleDebug is able to partially activate it and view some of its new user interface elements. When activated, the feature adds a new Graduation Cap icon at the bottom of the screen marked with a "Beta" badge indicating that the "Practice" feature will be released initially in experimental form. The related pop-up prompt shows "Practice the activities tailored for you!", which means Google will generate customized
 They're Making TCP/IP For AI, And It's Called NANDAApr 30, 2025 am 11:12 AM
They're Making TCP/IP For AI, And It's Called NANDAApr 30, 2025 am 11:12 AMMIT researchers are developing NANDA, a groundbreaking web protocol designed for AI agents. Short for Networked Agents and Decentralized AI, NANDA builds upon Anthropic's Model Context Protocol (MCP) by adding internet capabilities, enabling AI agen
 The Prompt: Deepfake Detection Is A Booming BusinessApr 30, 2025 am 11:11 AM
The Prompt: Deepfake Detection Is A Booming BusinessApr 30, 2025 am 11:11 AMMeta's Latest Venture: An AI App to Rival ChatGPT Meta, the parent company of Facebook, Instagram, WhatsApp, and Threads, is launching a new AI-powered application. This standalone app, Meta AI, aims to compete directly with OpenAI's ChatGPT. Lever
 The Next Two Years In AI Cybersecurity For Business LeadersApr 30, 2025 am 11:10 AM
The Next Two Years In AI Cybersecurity For Business LeadersApr 30, 2025 am 11:10 AMNavigating the Rising Tide of AI Cyber Attacks Recently, Jason Clinton, CISO for Anthropic, underscored the emerging risks tied to non-human identities—as machine-to-machine communication proliferates, safeguarding these "identities" become


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SublimeText3 Chinese version
Chinese version, very easy to use

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

