
Home >Technology peripherals >AI >The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-04-15 09:01:011480browse
Ollama is a super practical tool that allows you to easily run open source models such as Llama 2, Mistral, and Gemma locally. In this article, I will introduce how to use Ollama to vectorize text. If you don't have Ollama installed locally, you can read this article.
In this article we will use the nomic-embed-text[2] model. It is a text encoder that outperforms OpenAI text-embedding-ada-002 and text-embedding-3-small on short context and long context tasks.
Start the nomic-embed-text service
After you have successfully installed ollama, use the following command to pull the nomic-embed-text model:
ollama pull nomic-embed-text
After successfully pulling the model, enter the following command in the terminal to start the ollama service:
ollama serve
After that, we can use curl to verify whether the embedding service can run normally:
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'Using the nomic-embed-text service
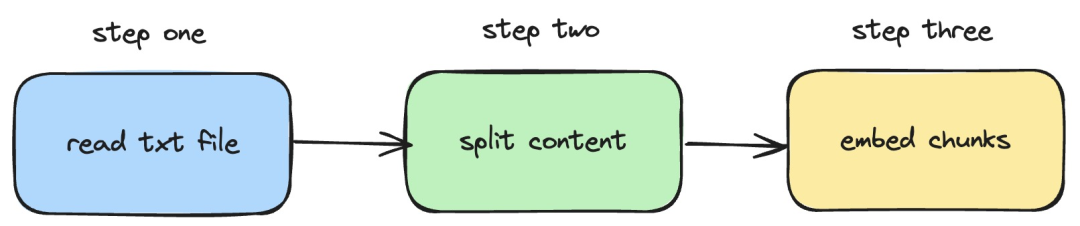
Next, we will introduce how to use langchainjs and the nomic-embed-text service to perform embeddings operations on local txt documents . The corresponding process is shown in the figure below:
 Picture
Picture
1. Read the local txt file
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}In the above code, we define a load function, which internally uses the TextLoader provided by langchainjs to read the local txt document.
2. Split the txt content into text blocks
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}In the above code, we use RecursiveCharacterTextSplitter to cut the read txt text and set each text The block size is 500.
3. Perform embeddings operations on text blocks
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}In the above code, we define an embedding function, in which the load defined earlier will be called and split function. Then traverse the generated text block and call the locally started nomic-embed-text embedding service. The sendRequest function is used to send embedding requests. Its implementation code is very simple, which is to use the fetch API to call the existing REST API.
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}Next, we continue to define an embedTxtFile function, directly call the existing embedding function inside the function and add corresponding exception handling.
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")Finally, we use the npx esno src/index.ts command to quickly execute the local ts file. If the code in index.ts is successfully executed, the following results will be output in the terminal:
 Picture
Picture
In fact, in addition to using the above method, We can also directly use the [OllamaEmbeddings](https://js.langchain.com/docs/integrations/text_embedding/ollama "OllamaEmbeddings") object in the @langchain/community module, which internally encapsulates the logic of calling the ollama embedding service:
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);This article introduces the process of establishing a knowledge base content index when developing a RAG system. If you don’t know about the RAG system, you can read related articles.
References
[1]Ollama: https://ollama.com/
[2]nomic-embed-text: https://ollama.com/ library/nomic-embed-text
The above is the detailed content of The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- The difference between has and with in Laravel association model (detailed introduction)
- What is a software development model, and what are the common software development models?
- What are the common software development models?
- What model does the 7-layer network structure refer to?
- How to copy a model to another file in 3dmax