

 Technology peripheralsAINew ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~
Technology peripheralsAINew ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~New ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~

Original title: LidarDM: Generative LiDAR Simulation in a Generated World
Paper link: https://arxiv.org/pdf/2404.02903.pdf
Code link: https ://github.com/vzyrianov/lidardm
Author affiliation: University of Illinois, Massachusetts Institute of Technology

Thesis idea:
This article introduces LidarDM, a novel lidar generation model capable of producing realistic, layout-aware, physically believable, and temporally coherent lidar videos. LidarDM has two unprecedented capabilities in lidar generation modeling: (1) lidar generation guided by driving scenarios, providing significant incentives for autonomous driving simulations; (2) 4D lidar point cloud generation, enabling the creation of realistic and Temporally coherent lidar sequences are possible. The core of our model is a novel comprehensive 4D world generation framework. Specifically, this paper uses latent diffusion models to generate 3D scenes, combines them with dynamic actors to form the underlying 4D world, and then generates realistic laser perception data in this virtual environment. . Our experiments show that our method outperforms competing algorithms in terms of fidelity, temporal coherence, and layout consistency. This paper also demonstrates that LidarDM can be used as a generative world simulator for training and testing perception models.
Network Design:
The developed generative models have attracted increasing attention in handling data distribution and content creation, such as image and video generation [ 10, 33, 52-55], 3D object generation [10, 19, 38, 52], compression [5, 29, 68] and editing [37, 47] and other fields. Generative models also show excellent potential for simulation [6, 11, 18, 34, 46, 60, 64, 66, 76, 82], enabling the creation of realistic scenarios and their associated sensory data for training and evaluation of safety Critical intelligence capabilities, such as robots and self-driving vehicles, eliminate the need for costly manual modeling of the real world. These capabilities are critical for applications that rely on extensive environmental training or scenario testing.
Progress in conditional image and video generation has been remarkable, but the specific task of generating realistic lidar point cloud sequences for functionally specific scenarios for autonomous driving applications remains underexplored. Current lidar generation methods fall into two main categories, each of which faces specific challenges.
- Current lidar generation modeling methods [8, 72, 79, 83] are limited to single-frame generation and do not provide means for semantic controllability and temporal consistency.
- LiDAR resimulation [14, 17, 46, 65, 67, 74] relies heavily on user-created or real-world collected assets. This adds high operating costs, limits diversity, and limits wider applicability.
To address these challenges, this paper proposes LidarDM (Lidar Diffusion Model), which can create realistic, layout-aware, physically believable, and temporally coherent lidar videos. . This paper explores two novel capabilities that have not been addressed before: (i) lidar synthesis guided by driving scenarios, which has great potential for autonomous driving simulation, and (ii) aiming to produce realistic, annotated lidar point clouds Sequential 4D lidar point cloud synthesis. The key insight in achieving these goals in this paper lies in first generating and combining the underlying 4D world and then creating realistic perceptual observations within this virtual environment. To achieve this, this paper integrates existing 3D object generation methods to create dynamic actors and develops a new method for large-scale 3D scene generation based on latent diffusion models. This approach is capable of producing realistically diverse 3D driving scenes from the semantic layout of particles, and to the best of the knowledge of this paper, it is the first attempt. This article applies trajectories to generate a 3D world and performs stochastic raycasting simulation to generate the final 4D lidar sequence. As shown in Figure 1, the results generated in this paper are diverse, aligned with the layout conditions, and are both realistic and temporally coherent.
The experimental results of this paper show that single-frame images generated by LidarDM exhibit realism and diversity, and their performance is comparable to the state-of-the-art stripe-free single-frame laser point cloud generation technology. Furthermore, this paper demonstrates that LidarDM is capable of producing temporally coherent laser point cloud videos, beyond the robust diffusion sensor generation baseline. To the best of our knowledge, this is the first laser point cloud generation method with this capability. This paper further demonstrates the item generation capabilities of LidarDM by demonstrating good agreement between the generated laser point cloud and the real laser point cloud under matching map items. Finally, this paper demonstrates that data generated using LidarDM exhibit minimal domain gaps when tested with perception modules trained on real data, and can also be used to extend the training data, significantly improving the performance of 3D detectors. This provides a prerequisite for using the generated laser point cloud model to create a realistic and controllable simulation environment for training and testing driving models.
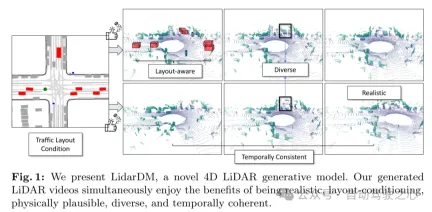
Figure 1: This paper demonstrates LidarDM, a novel 4D lidar generative model. The lidar video generated in this article has the advantages of realism, layout conditionality, physical credibility, diversity and temporal coherence at the same time.
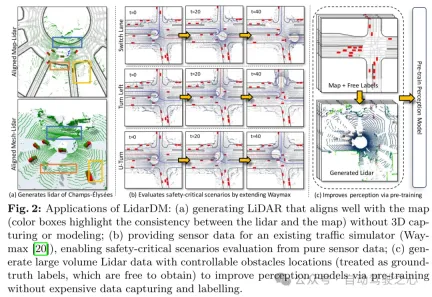
Figure 2: Application of LidarDM: (a) Generating lidar closely aligned with the map without 3D capture or modeling (colored box highlights lidar consistency with maps); (b) provide sensor data to an existing traffic simulator (Waymax [20]), enabling it to evaluate safety-critical scenarios from pure sensor data only; (c) generate traffic with controllable obstacles Large amounts of lidar data of object locations (considered as freely available ground truth labels) to improve perception models through pre-training without expensive data capture and annotation.

Figure 3: LidarDM Overview: Given the traffic layout input at time t = 0, LidarDM first generates traffic participants (actors) and static scenes. Then, this article generates the movements of traffic participants (actors) and self-vehicles, and builds the underlying 4D world. Finally, use generative and physics-based simulation to create realistic 4D sensor data.

Figure 4: The 3D scene generation process of this article. First, the accumulated point cloud is used to reconstruct each real mesh sample. Next, a variational autoencoder (VAE) is trained to compress the grid into an implicit encoding. Finally, a diffusion model conditioned on the map is trained to sample within the latent space of the VAE to generate new samples.
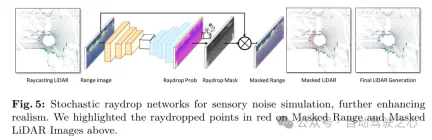
Figure 5: Random raydrop network for perceptual noise simulation, further enhancing realism. This article highlights raydropped points in red in the masked distance map and masked lidar image above.
Experimental results:

Figure 6: Real KITTI-360 samples compared to unconditioned samples from competing methods. UltraLiDAR sample visualizations are taken directly from their paper. Compared to previous methods, LidarDM generates samples with a greater number of more detailed salient objects (e.g., cars, pedestrians), clearer 3D structures (e.g., straight walls), and a more realistic road layout.
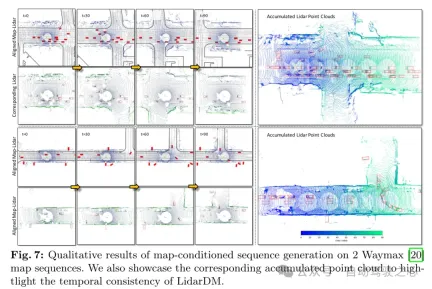
Figure 7: Qualitative results of map-conditioned sequence generation on 2 Waymax [20] map sequences. This paper also shows the corresponding cumulative point cloud to highlight the temporal consistency of LidarDM.




Summary:
This paper proposes LidarDM, which is a novel layout-based Conditional latent diffusion models for generating realistic lidar point clouds. Our approach frames the problem as a joint 4D world creation and perception data generation task, and develops a novel latent diffusion model to create 3D scenes. The resulting point cloud video is realistic, coherent, and layout-aware.
The above is the detailed content of New ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~. For more information, please follow other related articles on the PHP Chinese website!

 Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AM
Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AMSince 2008, I've championed the shared-ride van—initially dubbed the "robotjitney," later the "vansit"—as the future of urban transportation. I foresee these vehicles as the 21st century's next-generation transit solution, surpas
 Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AM
Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AMRevolutionizing the Checkout Experience Sam's Club's innovative "Just Go" system builds on its existing AI-powered "Scan & Go" technology, allowing members to scan purchases via the Sam's Club app during their shopping trip.
 Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AM
Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AMNvidia's Enhanced Predictability and New Product Lineup at GTC 2025 Nvidia, a key player in AI infrastructure, is focusing on increased predictability for its clients. This involves consistent product delivery, meeting performance expectations, and
 Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AM
Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AMGoogle's Gemma 2: A Powerful, Efficient Language Model Google's Gemma family of language models, celebrated for efficiency and performance, has expanded with the arrival of Gemma 2. This latest release comprises two models: a 27-billion parameter ver
 The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AM
The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AMThis Leading with Data episode features Dr. Kirk Borne, a leading data scientist, astrophysicist, and TEDx speaker. A renowned expert in big data, AI, and machine learning, Dr. Borne offers invaluable insights into the current state and future traje
 AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AM
AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AMThere were some very insightful perspectives in this speech—background information about engineering that showed us why artificial intelligence is so good at supporting people’s physical exercise. I will outline a core idea from each contributor’s perspective to demonstrate three design aspects that are an important part of our exploration of the application of artificial intelligence in sports. Edge devices and raw personal data This idea about artificial intelligence actually contains two components—one related to where we place large language models and the other is related to the differences between our human language and the language that our vital signs “express” when measured in real time. Alexander Amini knows a lot about running and tennis, but he still
 Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AM
Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AMCaterpillar's Chief Information Officer and Senior Vice President of IT, Jamie Engstrom, leads a global team of over 2,200 IT professionals across 28 countries. With 26 years at Caterpillar, including four and a half years in her current role, Engst
 New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AM
New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AMGoogle Photos' New Ultra HDR Tool: A Quick Guide Enhance your photos with Google Photos' new Ultra HDR tool, transforming standard images into vibrant, high-dynamic-range masterpieces. Ideal for social media, this tool boosts the impact of any photo,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SublimeText3 English version
Recommended: Win version, supports code prompts!

Atom editor mac version download
The most popular open source editor

