
Home >Technology peripherals >AI >US$100,000 to train Llama-2 large model! All Chinese people build a new MoE, Jia Yangqing, former CEO of SD, looks on
US$100,000 to train Llama-2 large model! All Chinese people build a new MoE, Jia Yangqing, former CEO of SD, looks on

- WBOYforward
- 2024-04-07 09:04:01601browse
If you want to know more about AIGC,
please visit: 51CTO AI.x Community
https ://www.51cto.com/aigc/
"Only"$100,000 can be used to train a large model at the Llama-2 level.
Smaller size but no loss in performanceMoEThe model is here:
It’s calledJetMoE, from research institutions such as MIT and Princeton.
The performance is much better than Llama-2 of the same scale.
△Jia Yangqing forwarded
You must know that the latter has an investment cost of billions of dollars.
JetMoE is completely open source when released, and is friendly to academia: only public data sets and open source code are used, and consumer-grade GPU can be fine-tuned.
It must be said that the cost of building large models is really much cheaper than people think.
Ps. Emad, the former boss of Stable Diffusion, also liked it:
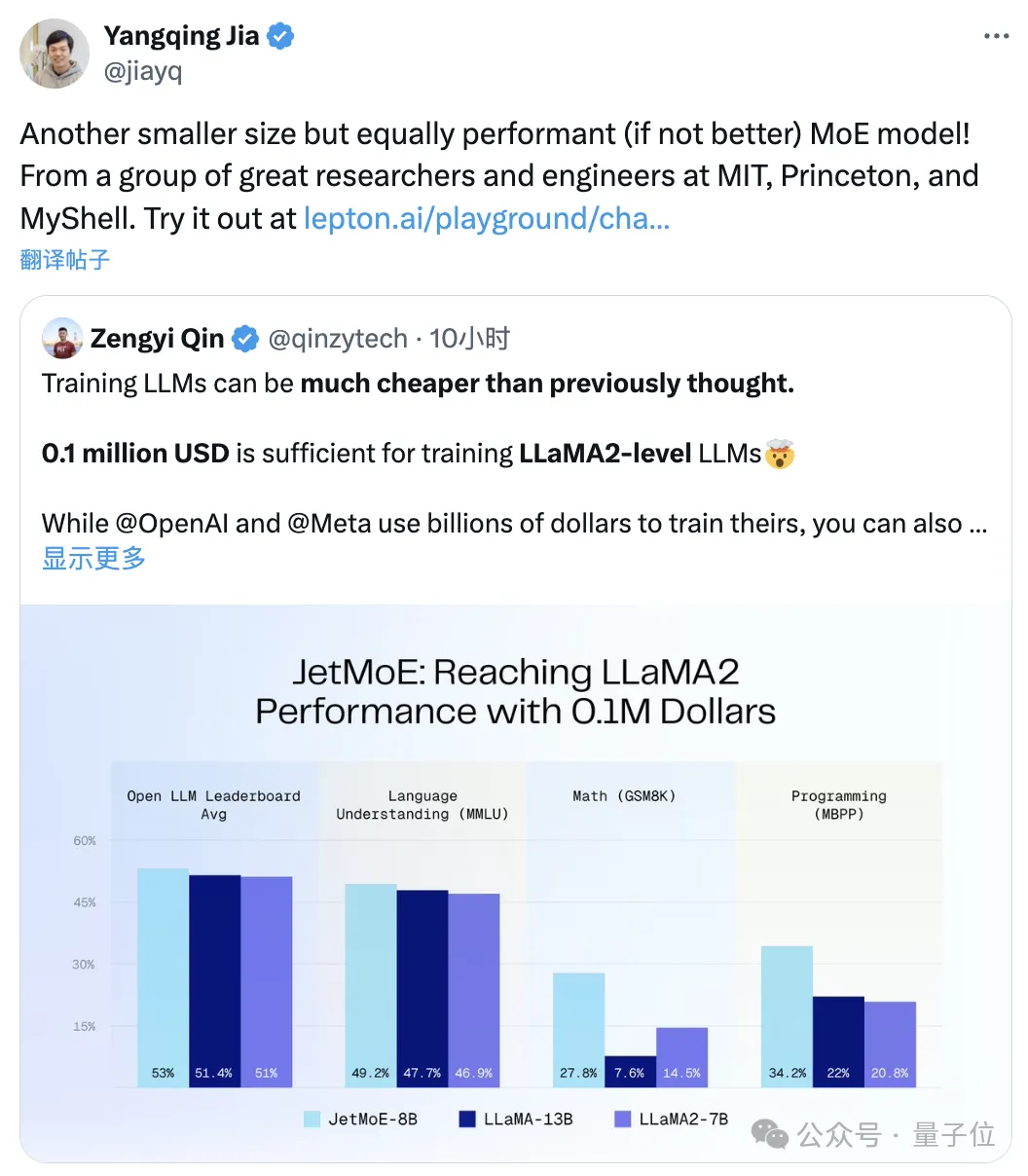
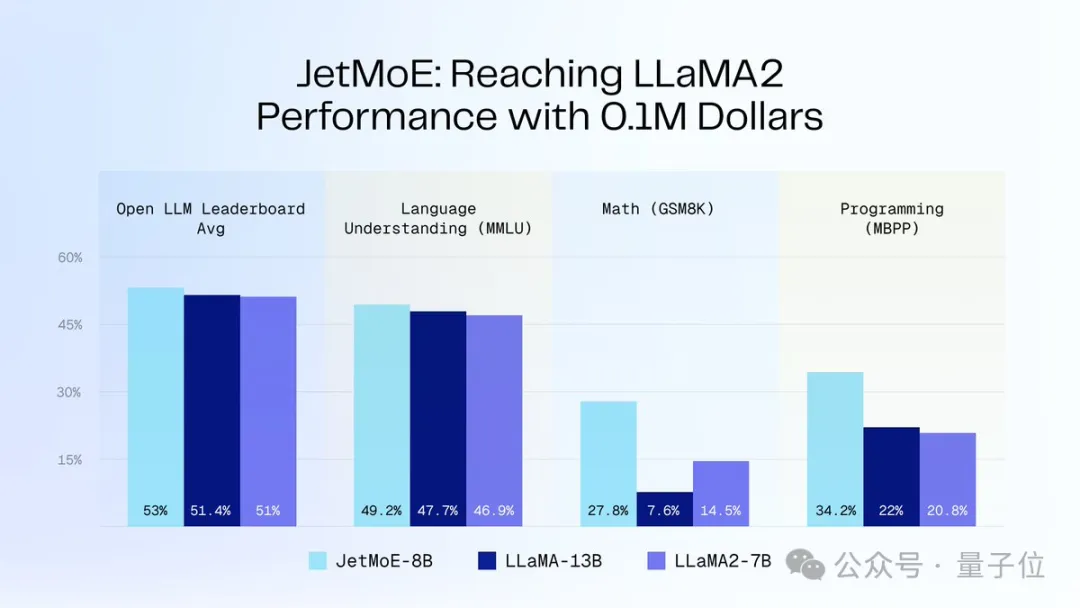
100,000 USD to achieve Llama-2 performance
JetMoE is inspired by the sparse activation architecture of ModuleFormer.
(ModuleFormer, a modular architecture based on Sparse Mixture of Experts (SMoE), which can improve the efficiency and flexibility of large models, was proposed in June last year)
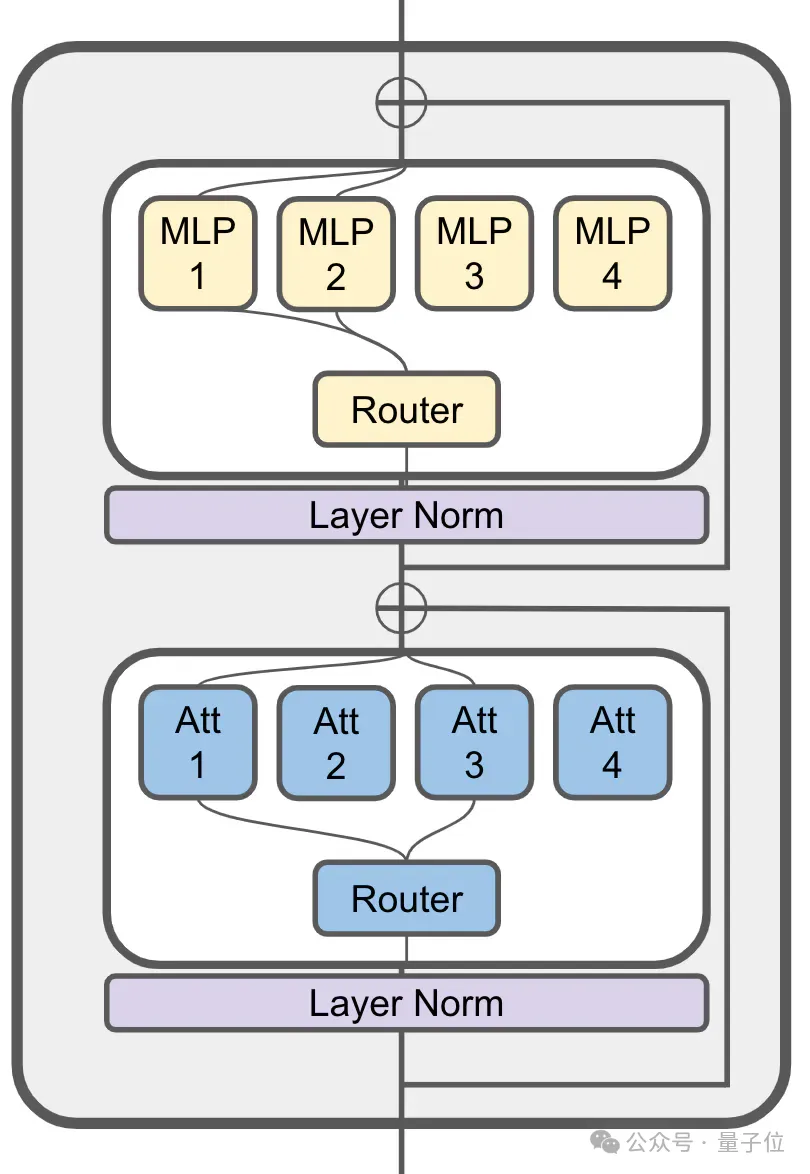
It MoE is still used in the attention layer:
8 billion parameter JetMoE has a total of 24 blocks, each block contains 2 MoE layers, namely attention head mixing (MoA) mixed with MLP experts (MoE).
Each MoA and MoE layer has 8 experts, and 2 are activated each time the token is input.
JetMoE-8B uses 1.25T token in the public data set for training, with a learning rate of 5.0 x 10-4, global The batch size is 4M tokens.
Specific training planFollows the ideas of MiniCPM (from wall-facing intelligence, 2B model can catch up with Mistral-7B), including a total ofTwo stages:
The first stage uses a constant learning rate with linear warm-up and is trained with 1 trillion tokens from a large-scale open source pre-training data set. These data sets include RefinedWeb, Pile, Github data, etc.
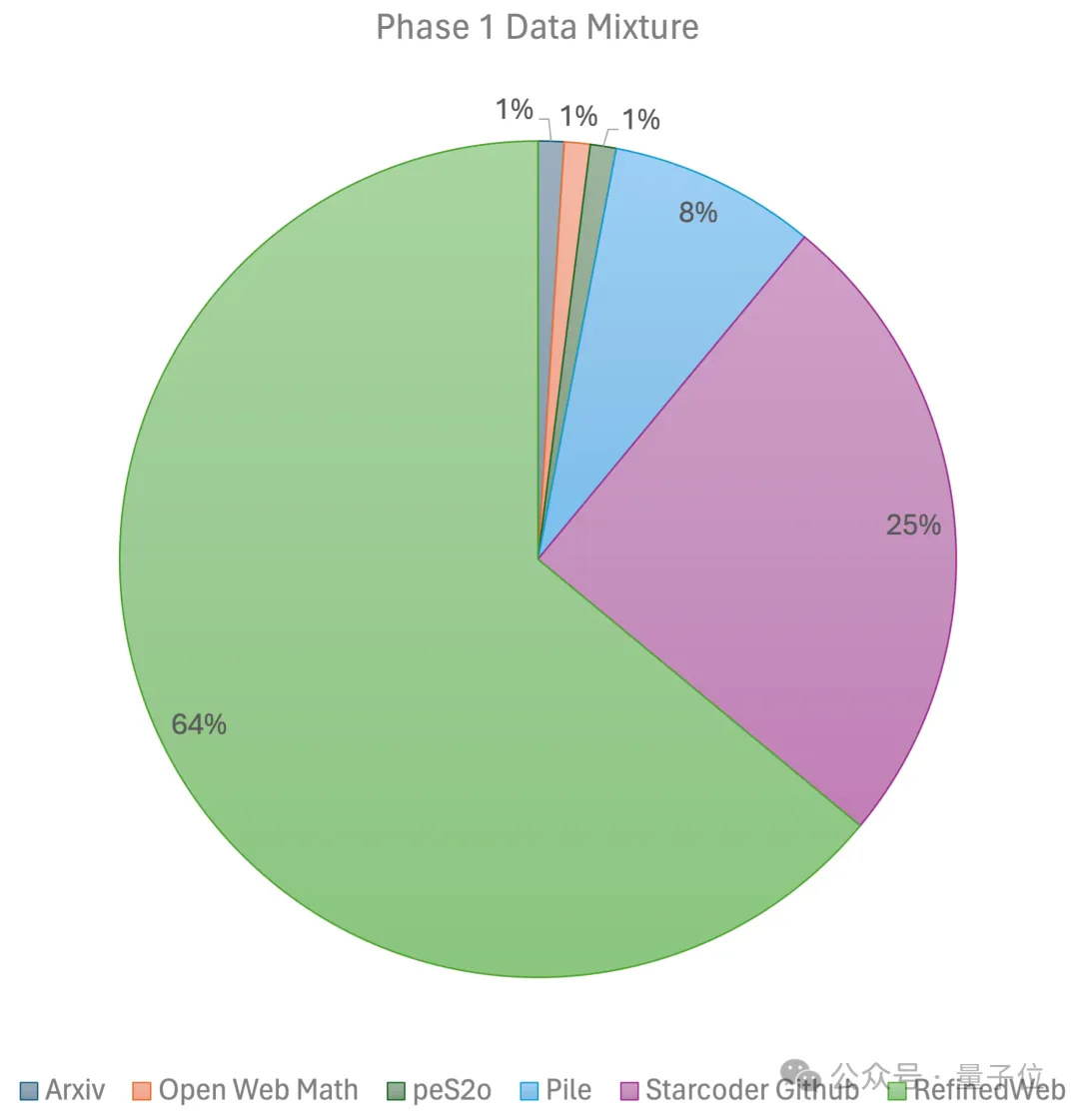
The second stage uses exponential learning rate decay and uses 250 billion tokens to train tokens from the first stage data set and ultra-high-quality open source data sets.
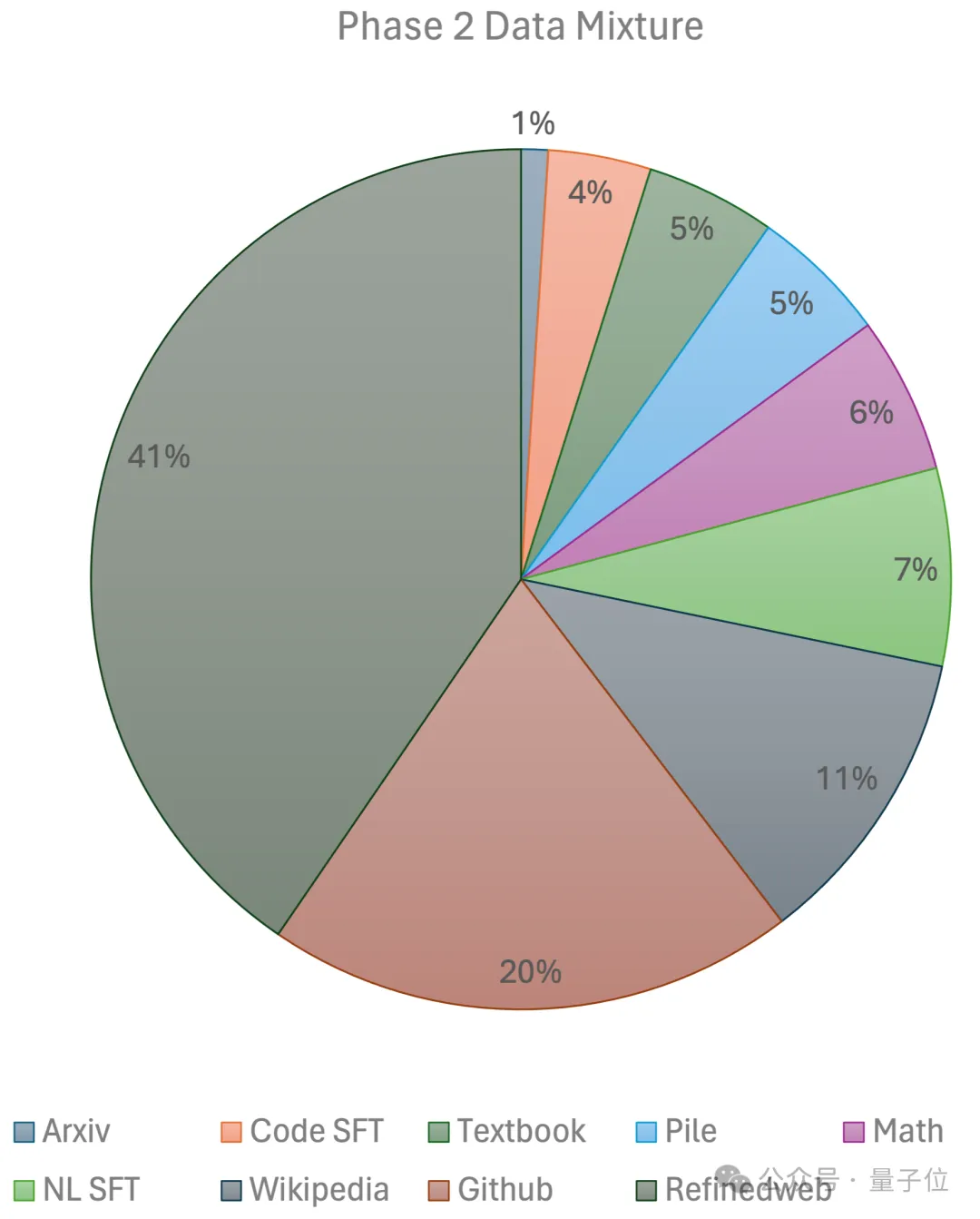
In the end, the team used a 96×H100 GPU cluster, which took 2 weeks and about $80,000Get JetMoE-8B.
More technical details will be revealed in a technical report released soon.
During the inference process, since JetMoE-8B only has 2.2 billion activation parameters, the computational cost is greatly reduced——
At the same time , it also achieved good performance.
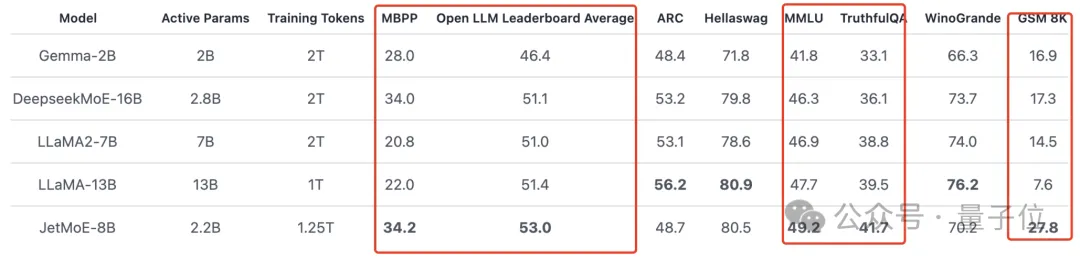
As shown in the figure below:
JetMoE-8B obtained 5 sota (including large model arena Open LLM Leaderboard) on 8 evaluation benchmarks, exceeding LLaMA -13B, LLaMA2-7B and DeepseekMoE-16B.
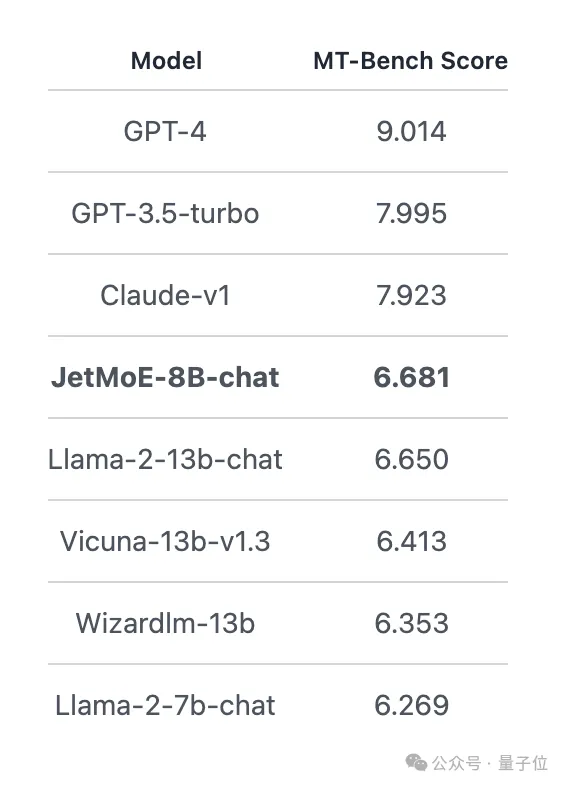
Scored 6.681 on the MT-Bench benchmark, also surpassing LLaMA2, Vicuna and other models with 13 billion parameters.
Author introduction
JetMoE has a total of 4 authors, namely:
- Yikang Shen
Researcher at MIT-IBM Watson Lab, research direction NLP.
Graduated from Beihang University with a bachelor's degree and a doctoral degree from Mila Research Institute founded by Yoshua Bengio.
- 国正 (Gavin Guo)
Ph.D. from MIT Currently studying, my research direction is data-efficient machine learning for 3D imaging.
Graduated from UC Berkeley with a bachelor's degree, he joined the MIT-IBM Watson Lab as a student researcher last summer. His mentor was Yikang Shen and others.
- 蔡天乐
普林斯顿博士在读生,本科毕业于北大应用数学和计算机科学,目前也是Together. Part-time researcher at ai, working with Tri Dao.
- Zengyi Qin
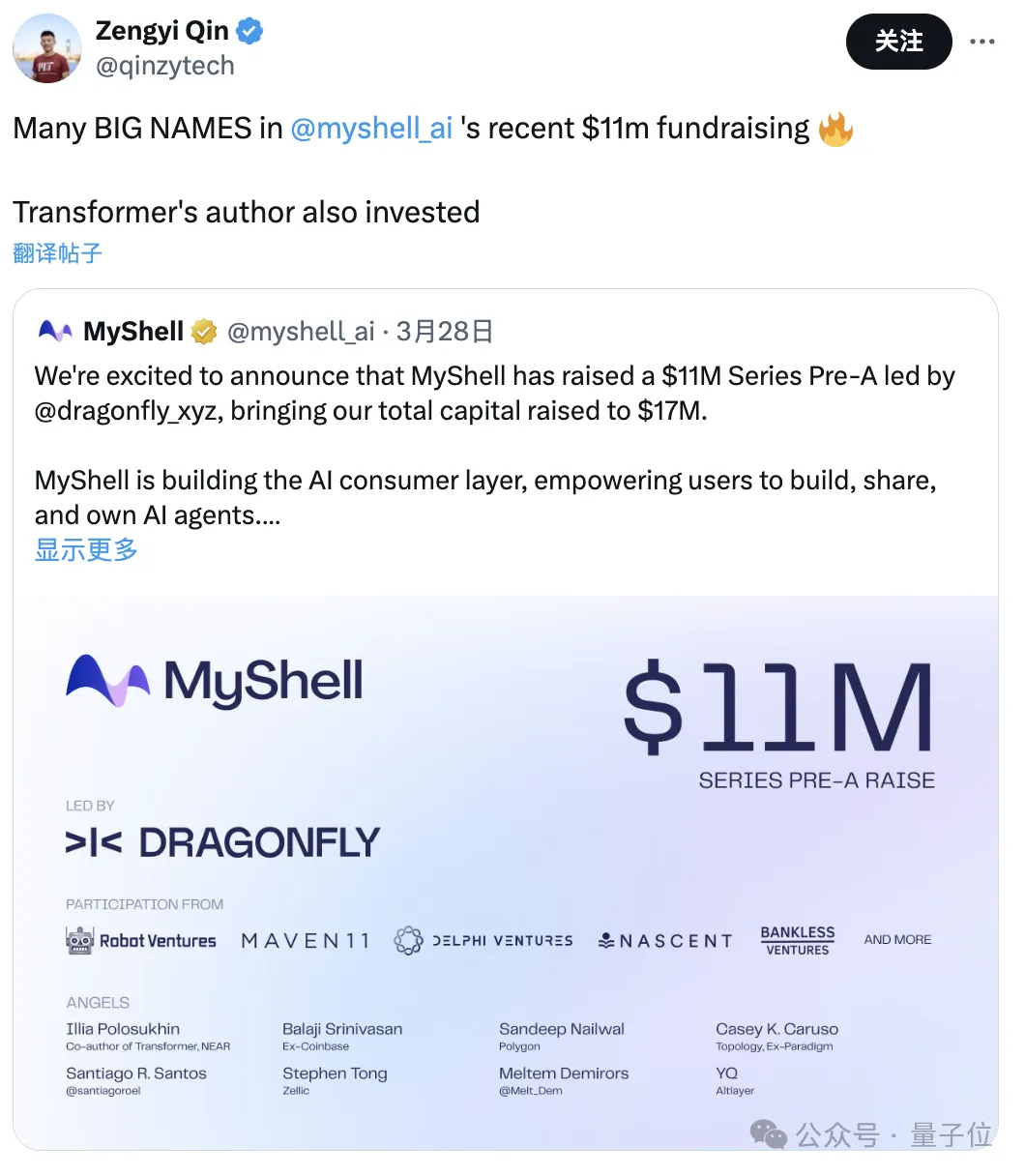
#'s AI R&D director.
The company has just raised $11 million, with investors including the author of Transformer.The above is the detailed content of US$100,000 to train Llama-2 large model! All Chinese people build a new MoE, Jia Yangqing, former CEO of SD, looks on. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- What does the python ipo model mean?
- What is the color model used by computer monitors?
- Implement edge training with less than 256KB of memory, and the cost is less than one thousandth of PyTorch
- IBM develops cloud-native AI supercomputer Vela to flexibly deploy and train tens of billions of parameter models
- Training time problem of deep learning model