
Home >Technology peripherals >AI >OpenAI large model upper body robot demonstrates the explosion at full speed!
OpenAI large model upper body robot demonstrates the explosion at full speed!

- WBOYforward
- 2024-03-15 09:37:23529browse
The robot blessed by OpenAI's large model comes late at night!
It’s called Figure 01. It can listen, speak, and move flexibly.

Can describe to humans everything they see:
I saw a red apple on the table, and a few more on the draining rack. A plate and a cup; you stand next to them, your hands resting lightly on the table.
 Picture
Picture
When a human says "I want to eat", I immediately hand over the apple.
 Picture
Picture
And he has a clear understanding of what he is doing. He gives the apple because it is the only edible thing on the table.
I also organize things by the way, and can handle two tasks at the same time.
 Picture
Picture
The most important thing is that these demonstrations are not accelerated, the original movement of the robot is so fast.
(No one is behind the scenes)

Now netizens couldn’t sit still and immediately @Boston Dynamics:
Old man Guys, this guy is really excited. We have to go back to the lab and let the old robot (Boston Dynamics) dance a little more.
 Picture
Picture
Some netizens also sighed after watching OpenAI roll out the large language model and Vincent video, and then sniped the robot:
It's a tough competition; working with OpenAl, Apple could surpass Tesla.
But in terms of hardware, Optimus Prime looks more beautiful, and Figure 01 still needs some "cosmetic surgery." (doge)
 Picture
Picture
Next, let’s continue to look at the details of Figure 01.
OpenAI visual language large model blessing
According to the founder’s introduction, Figure 01 can freely talk to humans through an end-to-end neural network.
Based on the visual understanding and language understanding capabilities provided by OpenAI, it can complete fast, simple, and dexterous actions.
The model is only said to be a large visual language model. It is unknown whether it is GPT-4V.
 Picture
Picture
It can also plan actions, have short-term memory capabilities, and explain its reasoning process in language.
 Picture
Picture
For example, in the dialogue, "Can you put them there?"
"Them", "There" The understanding of this vague expression reflects the robot's short-term memory ability.
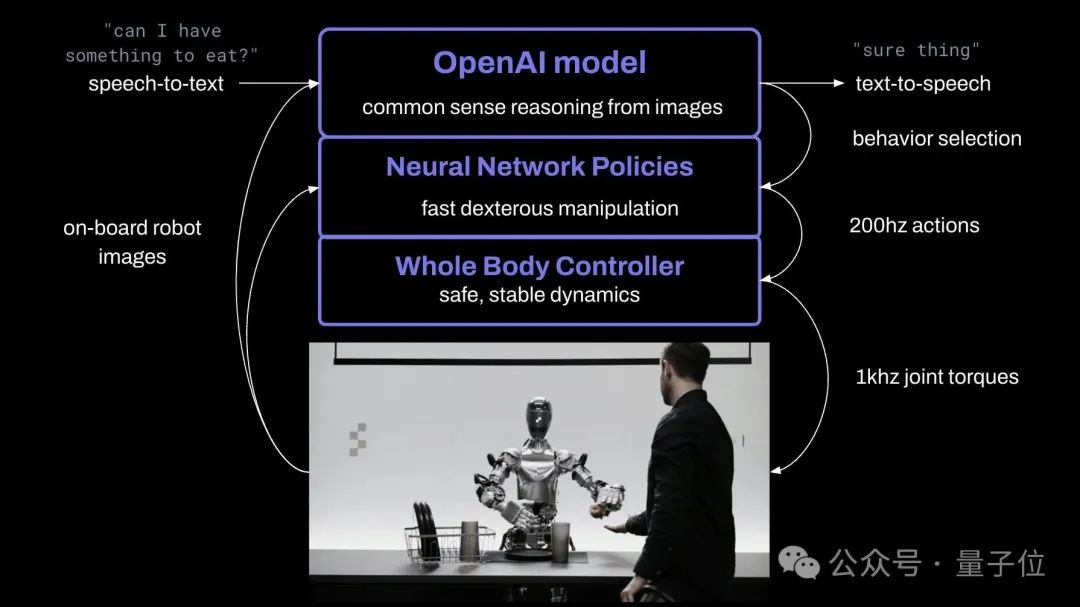
It uses the visual language model trained by OpenAI. The robot camera will capture the image at 10Hz, and then the neural network will output 24 degrees of freedom motion (wrist finger joint angle) at 200Hz.
In terms of specific division of labor, the robot's strategy is also very similar to that of humans.
Complex actions are handed over to the large AI model. The pre-trained model will perform common sense reasoning on images and texts and give action plans;
Simple actions such as grabbing a plastic bag (you can grab it anywhere) , the robot can make some "subconscious" quick reaction actions based on the learned vision-action execution strategy.
At the same time, the whole body controller will be responsible for maintaining body balance and stable movement.
 Picture
Picture
The robot’s voice capabilities are fine-tuned based on a large text-speech model.
 Picture
Picture
In addition to the most advanced AI model, the founder and CEO of Figure, the company behind Figure 01, also mentioned in a tweet that Figure Integrates all key components of a robot.
Including motors, middleware operating systems, sensors, mechanical structures, etc., all designed by Figure engineers.
It is understood that this robotics start-up company only officially announced its cooperation with OpenAI 2 weeks ago, but it only brought such a major result 13 days later. Many people are beginning to look forward to subsequent cooperation.
 Picture
Picture
Thus, another new star in the field of embodied intelligence has stepped into the spotlight.
“Bringing humanoid robots into life”
Speaking of Figure, this company was founded in 2022. As mentioned above, it once again attracted attention from the outside world, just a dozen days ago——
Officially announced that it has raised US$675 million in a new round of financing, with its valuation reaching US$2.6 billion. Investors have gathered almost half of Silicon Valley, including Microsoft, OpenAI, Nvidia and Amazon founder Bezos etc.
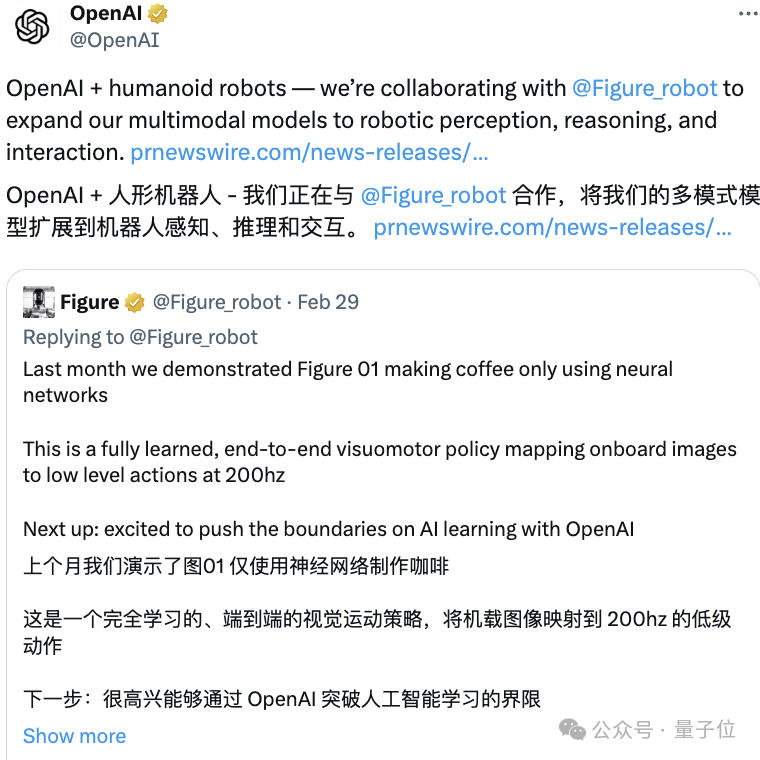
More importantly, OpenAI also disclosed plans for further cooperation with Figure: to extend the capabilities of multi-modal large models to the perception, reasoning and interaction of robots, "developing the ability to replace humans in physical labor" humanoid robot".
To use the hottest technology vocabulary right now, we need to work together to develop embodied intelligence.
 Picture
Picture
At that time, the latest progress of Figure 01 was Aunt Jiang’s:
By watching human demonstration videos, just After 10 hours of end-to-end training, Figure 01 can learn to make coffee using a capsule coffee machine.
 Picture
Picture
As soon as the cooperation between Figure and OpenAI was made public, netizens were already full of expectations for future breakthroughs.
 Picture
Picture
After all, Brett Adcock said that "the only focus is to establish Figure with a 30-year perspective to positively impact the future of mankind." It's all written on my personal homepage.
But perhaps no one could have imagined that in just about two weeks, new progress would come.
So fast, so far. And it can continue to be generalized and expanded in scale.
 Picture
Picture
It is worth mentioning that Figure’s recruitment information was released at the same time as the bombing site demo:
We are bringing humanoid robots to life. join us.
 Picture
Picture
Reference link:
[1]https://www.php.cn/link/59bbfbe0d3922ccd1d167661a26d8353
[2]https://www.php.cn/link/a3fc34dce15cda93287496c84af5203c
[3]https://www.php.cn/link/194585b5215aea447389c5fefca09c61
The above is the detailed content of OpenAI large model upper body robot demonstrates the explosion at full speed!. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- AIML-based PHP chatbot
- What impact will robots have on the future?
- What is the process of converting an e-r diagram into a relational data model?
- Let you use CSS+jQuery to implement a text-to-speech robot
- Copilot comes on the scene, ChatGPT uses Bing search by default, and the big universe of Microsoft and OpenAI is here