

 Technology peripheralsAIStable Diffusion 3 technical report released: revealing the same architecture details of Sora
Technology peripheralsAIStable Diffusion 3 technical report released: revealing the same architecture details of SoraStable Diffusion 3 technical report released: revealing the same architecture details of Sora

Very soon, the technical report of Stable Diffusion 3, the “new king of Vincentian graphics”, is here.
The full text has a total of 28 pages and is full of sincerity.

"Old rules", the promotional poster (⬇️) is directly generated with the model, and then shows off the text rendering ability:
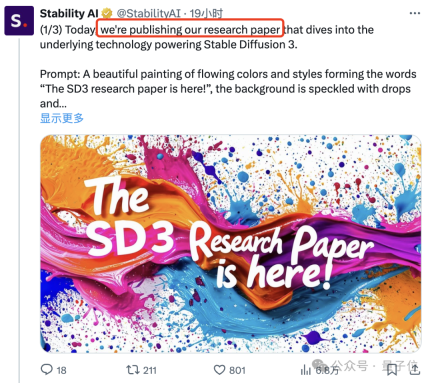
So, how does SD3 light up its text and command following skills, which are stronger than DALL·E 3 and Midjourney v6?
Technical report reveals:
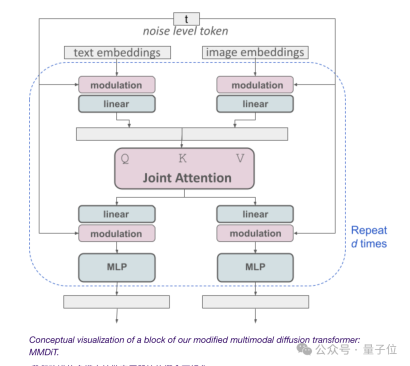
It all relies on the multi-modal diffusion Transformer architecture MMDiT.
By applying different sets of weights to image and text representations, a more powerful performance improvement than previous versions was achieved, which is the key to success.
Let’s open the report to see the details.
Fine-tuning DiT to improve text rendering capabilities
At the beginning of the release of SD3, the official revealed that its architecture has the same origin as Sora and is a diffusion Transformer-DiT.
Now the answer is revealed:
Since the Vincent graph model needs to consider both text and image modes, Stability AI goes one step further than DiT and proposes a new architecture MMDiT.
The "MM" here refers to "multimodal".
Like previous versions of Stable Diffusion, the official uses two pre-trained models to obtain suitable text and image representations.
The encoding of text representation is done using three different text embedders (embedders), including two CLIP models and a T5 model.
The encoding of the image token is completed using an improved autoencoder model.
Since text and image embedding are conceptually not the same thing, SD3 uses two sets of independent weights for these two modes.
(Some netizens complained: This architecture diagram seems to start the "Human Completion Project", um, yes, some people just "saw "Neon Genesis Evangelion" I just clicked on the information to enter this report")
Getting back to the point, as shown in the figure above, this is equivalent to having two independent transformers for each modality, but the Their sequences are concatenated for attentional operations.
This way both representations can work in their own space while still taking the other into account.
Ultimately, through this method, information can "flow" between images and text tokens, improving the model's overall understanding and text rendering capabilities during output.
And as shown previously, this architecture can be easily extended to video and other modes.

Specific tests show that MMDiT is better than DiT out of DiT:
It has both visual fidelity and text alignment during the training process. Better than existing text-to-image backbones, such as UViT and DiT.

Reweighted flow technology to continuously improve performance
At the beginning of the release, in addition to the diffusion Transformer architecture, the official also revealed that SD3 incorporates flow matching.
What "flow"?
As revealed in the title of the paper released today, SD3 uses "Rectified Flow" (RF).

This is an "extremely simplified, one-step generation" new diffusion model generation method, which was selected for ICLR2023.
It enables the model's data and noise to be connected in a linear trajectory during training, resulting in a more "straight" inference path that can use fewer steps for sampling.
Based on RF, SD3 introduces a new trajectory sampling during the training process.
It focuses on giving more weight to the middle part of the trajectory, because the author assumes that these parts will complete more challenging prediction tasks.
Testing this generation method against 60 other diffusion trajectory methods (such as LDM, EDM and ADM) across multiple datasets, metrics and sampler configurations found:
While the previous RF Methods show good performance in few-step sampling schemes, but their relative performance decreases as the number of steps increases.
In contrast, the SD3 reweighted RF variant consistently improves performance.
The model capability can be further improved
The official conducted a scaling study on text-to-image generation using the reweighted RF method and MMDiT architecture.
Trained models range from 15 modules with 450 million parameters to 38 modules with 8 billion parameters.
They observed from this: As the model size and training steps increase, the validation loss shows a smooth downward trend, that is, the model adapts to more complex data through continuous learning.

To test whether this translated into more meaningful improvements in model output, we also evaluated the automatic image alignment metric (GenEval) as well as humans Preference Rating (ELO) .
The result is:
There is a strong correlation between the two. That is, verification loss can be used as a very powerful indicator to predict overall model performance.

In addition, since the expansion trend here shows no signs of saturation (that is, as the model size increases, the performance is still improving and has not reached its limit), the official is optimistic Said:
The performance of SD3 can continue to improve in the future.
Finally, the technical report also mentions the issue of text encoders:
By removing the 4.7 billion parameter, memory-intensive T5 text encoder used for inference, the memory requirements of SD3 can be significantly reduced Reduced, but at the same time, the performance loss is very small (win rate dropped from 50% to 46%).
However, for the sake of text rendering capabilities, officials still recommend not to remove T5, because without it, the win rate of text representation will drop to 38%.

So to summarize: among the three text encoders of SD3, T5 makes the greatest contribution when generating images with text (and highly detailed scene description images) .
Netizens: The open source commitment has been fulfilled as scheduled, thank you
As soon as the SD3 report came out, many netizens said:
Stability AI’s commitment to open source has been fulfilled as scheduled. It's a pleasure and I hope they can continue to operate for a long time.

There are still people who have just announced the name of OpenAI:

What’s even more gratifying is that there are people who are The comment area mentioned:
All the weights of the SD3 model can be downloaded. Currently, 800 million parameters, 2 billion parameters and 8 billion parameters are planned.


How is the speed?
Ahem, the technical report mentioned:
8 billion SD3 takes 34s to generate a 1024*1024 image on a 24GB RTX 4090 (50 sampling steps)——But this is just an early preliminary inference test result without optimization.
Full text of the report: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable Diffusion 3 Paper.pdf.
Reference link:
[1]https://stability.ai/news/stable-diffusion- 3-research-paper.
[2]https://news.ycombinator.com/item?id=39599958.
The above is the detailed content of Stable Diffusion 3 technical report released: revealing the same architecture details of Sora. For more information, please follow other related articles on the PHP Chinese website!

 Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AM
Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AMSince 2008, I've championed the shared-ride van—initially dubbed the "robotjitney," later the "vansit"—as the future of urban transportation. I foresee these vehicles as the 21st century's next-generation transit solution, surpas
 Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AM
Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AMRevolutionizing the Checkout Experience Sam's Club's innovative "Just Go" system builds on its existing AI-powered "Scan & Go" technology, allowing members to scan purchases via the Sam's Club app during their shopping trip.
 Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AM
Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AMNvidia's Enhanced Predictability and New Product Lineup at GTC 2025 Nvidia, a key player in AI infrastructure, is focusing on increased predictability for its clients. This involves consistent product delivery, meeting performance expectations, and
 Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AM
Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AMGoogle's Gemma 2: A Powerful, Efficient Language Model Google's Gemma family of language models, celebrated for efficiency and performance, has expanded with the arrival of Gemma 2. This latest release comprises two models: a 27-billion parameter ver
 The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AM
The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AMThis Leading with Data episode features Dr. Kirk Borne, a leading data scientist, astrophysicist, and TEDx speaker. A renowned expert in big data, AI, and machine learning, Dr. Borne offers invaluable insights into the current state and future traje
 AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AM
AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AMThere were some very insightful perspectives in this speech—background information about engineering that showed us why artificial intelligence is so good at supporting people’s physical exercise. I will outline a core idea from each contributor’s perspective to demonstrate three design aspects that are an important part of our exploration of the application of artificial intelligence in sports. Edge devices and raw personal data This idea about artificial intelligence actually contains two components—one related to where we place large language models and the other is related to the differences between our human language and the language that our vital signs “express” when measured in real time. Alexander Amini knows a lot about running and tennis, but he still
 Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AM
Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AMCaterpillar's Chief Information Officer and Senior Vice President of IT, Jamie Engstrom, leads a global team of over 2,200 IT professionals across 28 countries. With 26 years at Caterpillar, including four and a half years in her current role, Engst
 New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AM
New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AMGoogle Photos' New Ultra HDR Tool: A Quick Guide Enhance your photos with Google Photos' new Ultra HDR tool, transforming standard images into vibrant, high-dynamic-range masterpieces. Ideal for social media, this tool boosts the impact of any photo,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

Dreamweaver Mac version
Visual web development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

