

 Technology peripheralsAINew work by the author of ControlNet: AI painting can be divided into layers! The project earned 660 stars without being open source
Technology peripheralsAINew work by the author of ControlNet: AI painting can be divided into layers! The project earned 660 stars without being open sourceNew work by the author of ControlNet: AI painting can be divided into layers! The project earned 660 stars without being open source

"It is by no means a simple cutout."
ControlNet authorThe latest study has received a wave of high attention——
Give me a prompt, you can use Stable Diffusion to directly generate single or multiple transparent layers (PNG) !
For example:
A woman with messy hair is in the bedroom.
Woman with messy hair, in the bedroom.

As you can see, AI not only generated a complete image that conforms to the prompt, but even the background Can also be separated from characters.
And if you zoom in on the character PNG image and take a closer look, you will see that the hair strands are clearly defined.

Look at another example:
Burning firewood, on a table, in the countryside.
Burning firewood, on a table, in the countryside.

Similarly, zoom in on the PNG of the "burning match", even the black smoke around the flame can all be separated:

This is the new method proposed by the author of ControlNet - LayerDiffusion, which allows large-scale pre-training of latent diffusion models (Latent Diffusion Model) generates transparent images.

It is worth emphasizing again that LayerDiffusion is by no means as simple as cutout, the focus is on generating.
As netizens said:
This is one of the core processes in animation and video production now. If this step can be passed, it can be said that SD consistency is no longer a problem.
# Some netizens thought that a job like this was not difficult, just a matter of "adding an alpha channel by the way", but what surprised him was:
It took so long for the results to come out.
#So how is LayerDiffusion implemented?
PNG, now starting to take the generation route
The core of LayerDiffusion is a method called latent transparency(latent transparency).
Simply put, it allows adding transparency to the model without destroying the latent distribution of the pre-trained latent diffusion model (such as Stable Diffusion) .
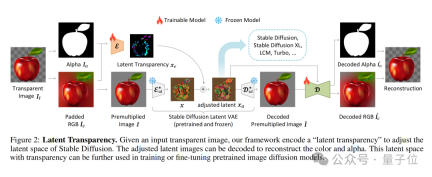
In terms of specific implementation, it can be understood as adding a carefully designed small perturbation (offset) to the latent image. This perturbation is encoded as an additional channel, which together with the RGB channel constitutes a complete potential image.
In order to achieve encoding and decoding of transparency, the author trained two independent neural network models: one is the latent transparency encoder(latent transparency encoder), and the other One is latent transparency decoder(latent transparency decoder).
The encoder receives the RGB channel and alpha channel of the original image as input and converts the transparency information into an offset in the latent space.
The decoder receives the adjusted latent image and the reconstructed RGB image, and extracts the transparency information from the latent space to reconstruct the original transparent image.
To ensure that the added potential transparency does not destroy the underlying distribution of the pre-trained model, the authors propose a measure of "harmlessness" .
This metric evaluates the impact of latent transparency by comparing the decoding results of the adjusted latent image by the original pre-trained model's decoder to the original image.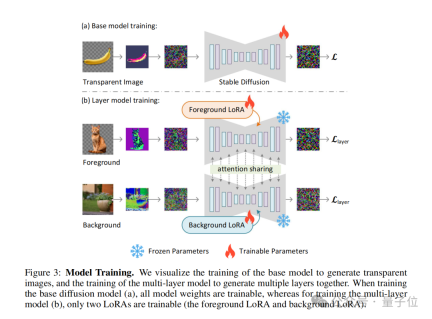
(joint loss function), which combines the reconstruction loss( reconstruction loss), identity loss (identity loss) and discriminator loss. Their functions are:
Reconstruction loss: used to ensure that the decoded image is as similar as possible to the original image;- Identity loss: used to ensure The adjusted latent image can be correctly decoded by the pre-trained decoder;
- discriminator loss: is used to improve the realism of the generated image.
- With this approach, any latent diffusion model can be converted into a transparent image generator by simply fine-tuning it to fit the adjusted latent space.
 The concept of latent transparency can also be extended to generate multiple transparent layers, as well as combined with other conditional control systems to achieve more complex image generation tasks such as foreground/background Conditional generation, joint layer generation, structural control of layer content, etc.
The concept of latent transparency can also be extended to generate multiple transparent layers, as well as combined with other conditional control systems to achieve more complex image generation tasks such as foreground/background Conditional generation, joint layer generation, structural control of layer content, etc.


##It is worth mentioning that the author also shows how to introduce ControlNet to enrich the functions of LayerDiffusion: 
The difference with traditional cutout
Native generation vs. post-processing
LayerDiffusion is a native transparent image generation method that considers and encodes transparency information directly during the generation process. This means that the model creates an alpha channel when generating the image, thus producing an image with transparency.
Traditional matting methods usually involve first generating or obtaining an image, and then using image editing techniques(such as chroma key, edge detection, user-specified masks, etc.) to separate the foreground and background. This approach often requires additional steps to handle transparency and can produce unnatural transitions on complex backgrounds or edges.
Latent space operations vs. pixel space operations
LayerDiffusion operates in latent space (latent space) , which is an intermediate representation that allows the model to learn and generate more complex image features. By encoding transparency in the latent space, the model can naturally handle transparency during generation without the need for complex calculations at the pixel level.
Traditional cutout technology is usually performed in pixel space, which may involve direct editing of the original image, such as color replacement, edge smoothing, etc. These methods may have difficulty handling translucent effects (such as fire, smoke) or complex edges.
Dataset and training
LayerDiffusion uses a large-scale data set for training. This data set contains transparent image pairs, allowing the model to learn to generate high-definition images. Complex distribution required for quality transparent images.
Traditional matting methods may rely on smaller data sets or specific training sets, which may limit their ability to handle diverse scenarios.
Flexibility and control
LayerDiffusion provides greater flexibility and control because it allows users to prompt via text (text prompts) to guide the generation of images and can generate multiple layers that can be blended and combined to create complex scenes.
Traditional cutout methods may be more limited in control, especially when dealing with complex image content and transparency.
Quality Comparison
User research shows that transparent images generated by LayerDiffusion are preferred by users in most cases (97%) , indicating The transparent content it generates is visually equivalent to, or perhaps even superior to, commercial transparent assets.
Traditional cutout methods may not achieve the same quality in some cases, especially when dealing with challenging transparency and edges.
In short, LayerDiffusion provides a more advanced and flexible method to generate and process transparent images.
It encodes transparency directly during the generation process and is able to produce high-quality results that are difficult to achieve in traditional matting methods.
About the author
As we just mentioned, one of the authors of this study is the inventor of the famous ControlNet-Zhang Lumin.
He graduated from Suzhou University with an undergraduate degree. He published a paper related to AI painting when he was a freshman. During his undergraduate period, he published 10 top-level works.
Zhang Lumin is currently studying for a PhD at Stanford University, but he can be said to be very low-key and has not even registered for Google Scholar.
As of now, LayerDiffusion is not open source in GitHub, but even so it cannot stop everyone's attention and has already gained 660 stars.
After all, Zhang Lumin has also been ridiculed by netizens as a "time management master". Friends who are interested in LayerDiffusion can mark it in advance.
The above is the detailed content of New work by the author of ControlNet: AI painting can be divided into layers! The project earned 660 stars without being open source. For more information, please follow other related articles on the PHP Chinese website!

 You Must Build Workplace AI Behind A Veil Of IgnoranceApr 29, 2025 am 11:15 AM
You Must Build Workplace AI Behind A Veil Of IgnoranceApr 29, 2025 am 11:15 AMIn John Rawls' seminal 1971 book The Theory of Justice, he proposed a thought experiment that we should take as the core of today's AI design and use decision-making: the veil of ignorance. This philosophy provides a simple tool for understanding equity and also provides a blueprint for leaders to use this understanding to design and implement AI equitably. Imagine that you are making rules for a new society. But there is a premise: you don’t know in advance what role you will play in this society. You may end up being rich or poor, healthy or disabled, belonging to a majority or marginal minority. Operating under this "veil of ignorance" prevents rule makers from making decisions that benefit themselves. On the contrary, people will be more motivated to formulate public
 Decisions, Decisions… Next Steps For Practical Applied AIApr 29, 2025 am 11:14 AM
Decisions, Decisions… Next Steps For Practical Applied AIApr 29, 2025 am 11:14 AMNumerous companies specialize in robotic process automation (RPA), offering bots to automate repetitive tasks—UiPath, Automation Anywhere, Blue Prism, and others. Meanwhile, process mining, orchestration, and intelligent document processing speciali
 The Agents Are Coming – More On What We Will Do Next To AI PartnersApr 29, 2025 am 11:13 AM
The Agents Are Coming – More On What We Will Do Next To AI PartnersApr 29, 2025 am 11:13 AMThe future of AI is moving beyond simple word prediction and conversational simulation; AI agents are emerging, capable of independent action and task completion. This shift is already evident in tools like Anthropic's Claude. AI Agents: Research a
 Why Empathy Is More Important Than Control For Leaders In An AI-Driven FutureApr 29, 2025 am 11:12 AM
Why Empathy Is More Important Than Control For Leaders In An AI-Driven FutureApr 29, 2025 am 11:12 AMRapid technological advancements necessitate a forward-looking perspective on the future of work. What happens when AI transcends mere productivity enhancement and begins shaping our societal structures? Topher McDougal's upcoming book, Gaia Wakes:
 AI For Product Classification: Can Machines Master Tax Law?Apr 29, 2025 am 11:11 AM
AI For Product Classification: Can Machines Master Tax Law?Apr 29, 2025 am 11:11 AMProduct classification, often involving complex codes like "HS 8471.30" from systems such as the Harmonized System (HS), is crucial for international trade and domestic sales. These codes ensure correct tax application, impacting every inv
 Could Data Center Demand Spark A Climate Tech Rebound?Apr 29, 2025 am 11:10 AM
Could Data Center Demand Spark A Climate Tech Rebound?Apr 29, 2025 am 11:10 AMThe future of energy consumption in data centers and climate technology investment This article explores the surge in energy consumption in AI-driven data centers and its impact on climate change, and analyzes innovative solutions and policy recommendations to address this challenge. Challenges of energy demand: Large and ultra-large-scale data centers consume huge power, comparable to the sum of hundreds of thousands of ordinary North American families, and emerging AI ultra-large-scale centers consume dozens of times more power than this. In the first eight months of 2024, Microsoft, Meta, Google and Amazon have invested approximately US$125 billion in the construction and operation of AI data centers (JP Morgan, 2024) (Table 1). Growing energy demand is both a challenge and an opportunity. According to Canary Media, the looming electricity
 AI And Hollywood's Next Golden AgeApr 29, 2025 am 11:09 AM
AI And Hollywood's Next Golden AgeApr 29, 2025 am 11:09 AMGenerative AI is revolutionizing film and television production. Luma's Ray 2 model, as well as Runway's Gen-4, OpenAI's Sora, Google's Veo and other new models, are improving the quality of generated videos at an unprecedented speed. These models can easily create complex special effects and realistic scenes, even short video clips and camera-perceived motion effects have been achieved. While the manipulation and consistency of these tools still need to be improved, the speed of progress is amazing. Generative video is becoming an independent medium. Some models are good at animation production, while others are good at live-action images. It is worth noting that Adobe's Firefly and Moonvalley's Ma
 Is ChatGPT Slowly Becoming AI's Biggest Yes-Man?Apr 29, 2025 am 11:08 AM
Is ChatGPT Slowly Becoming AI's Biggest Yes-Man?Apr 29, 2025 am 11:08 AMChatGPT user experience declines: is it a model degradation or user expectations? Recently, a large number of ChatGPT paid users have complained about their performance degradation, which has attracted widespread attention. Users reported slower responses to models, shorter answers, lack of help, and even more hallucinations. Some users expressed dissatisfaction on social media, pointing out that ChatGPT has become “too flattering” and tends to verify user views rather than provide critical feedback. This not only affects the user experience, but also brings actual losses to corporate customers, such as reduced productivity and waste of computing resources. Evidence of performance degradation Many users have reported significant degradation in ChatGPT performance, especially in older models such as GPT-4 (which will soon be discontinued from service at the end of this month). this


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

Atom editor mac version download
The most popular open source editor

WebStorm Mac version
Useful JavaScript development tools

