

 Technology peripheralsAINew work by Chen Danqi's team: Llama-2 context is expanded to 128k, 10 times throughput only requires 1/6 of the memory
Technology peripheralsAINew work by Chen Danqi's team: Llama-2 context is expanded to 128k, 10 times throughput only requires 1/6 of the memoryNew work by Chen Danqi's team: Llama-2 context is expanded to 128k, 10 times throughput only requires 1/6 of the memory

The Chen Danqi team has just released a new LLMContext window extensionMethod:
It only uses 8k token documents for training, and can Llama-2 Window extended to 128k.
The most important thing is that in this process, the model only requires 1/6 of the original memory, and the model obtains 10 times the throughput.
In addition, it can also greatly reduce the training cost:
Use this method to train 7B alpaca 2 For transformation, you only need a piece of A100 to complete it.
The team expressed:We hope this method will be useful and easy to use, and provideCurrently, the model and code have been released on HuggingFace and GitHub.cheap and effective long context capabilities for future LLMs.

CEPE, the full name is "Parallel Encoding Context Extension(Context Expansion with Parallel Encoding)”.
As a lightweight framework, it can be used to extend the context window of anypre-trained and directive fine-tuning model.
For any pretrained decoder-only language model, CEPE extends it by adding two small components:One is a small encoder for long The context is block-encoded;
One is the cross-attention module, which is inserted into each layer of the decoder to focus on the encoder representation.
The complete architecture is as follows:
(1) The length can be generalized
because it is not subject to positional encoding A constraint, instead, has its context encoded in segments, each segment having its own positional encoding.(2) High efficiencyUsing small encoders and parallel encoding to process context can reduce computational costs.
(3) Reduce training cost
with a 400M encoder and cross-attention layer (a total of 1.4 billion parameters), it can be completed with an 80GB A100 GPU.
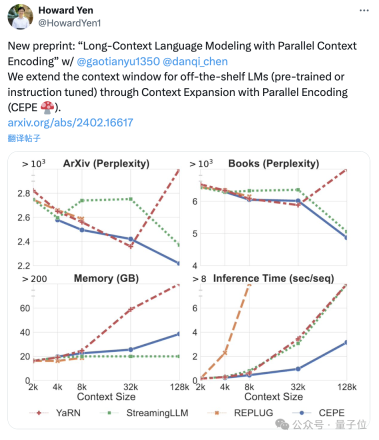
Perplexity continues to decreaseThe team applies CEPE to Llama-2 and trains on the filtered version of RedPajama with 20 billion tokens(only the Llama-2 pre-training budget 1%).
First, compared to two fully fine-tuned models, LLAMA2-32K and YARN-64K, CEPE achieves lower or comparableperplexity## on all datasets. #, with both lower memory usage and higher throughput.
 When the context is increased to 128k
When the context is increased to 128k
, CEPE’s perplexity continues to decrease while remaining low memory status. In contrast, Llama-2-32K and YARN-64K not only fail to generalize beyond their training length, but are also accompanied by a significant increase in memory cost.
 Secondly,
Secondly,
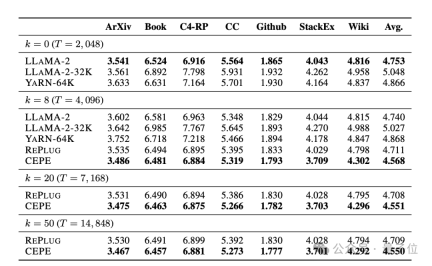
retrieval capability is enhanced. As shown in the following table:
By using the retrieved context, CEPE can effectively improve model perplexity, and its performance is better than RePlug.
It is worth noting that even if paragraph k=50 (training is 60), CEPE will continue to improve the perplexity.
This shows that CEPE transfers well to the retrieval enhancement setting, whereas the full-context decoder model degrades in this ability.
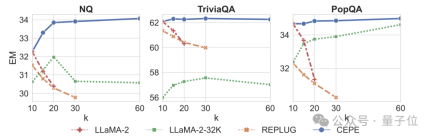
Third, open domain question and answer capabilitiesare significantly surpassed.
As shown in the figure below, CEPE is significantly better than other models in all data sets and paragraph k parameters, and unlike other models, the performance drops significantly as the k value becomes larger and larger.
This also shows that CEPE is not sensitive to a large number of redundant or irrelevant paragraphs.
So to summarize, CEPE outperforms on all the above tasks with much lower memory and computational cost compared to most other solutions.
Finally, based on these, the author proposed CEPE-Distilled (CEPED) specifically for the instruction tuning model.
It uses only unlabeled data to expand the context window of the model, distilling the behavior of the original instruction-tuned model into a new architecture through assisted KL divergence loss, thereby eliminating the need to manage expensive long context instruction tracking data.
Ultimately, CEPED can expand the context window of Llama-2 and improve the long text performance of the model while retaining the ability to understand instructions.
Team Introduction
CEPE has a total of 3 authors.
Yan Heguang(Howard Yen) is a master's student in computer science at Princeton University.
The second person is Gao Tianyu, a doctoral student at the same school and a bachelor's degree graduate from Tsinghua University.
They are all students of the corresponding author Chen Danqi.

Original paper: https://arxiv.org/abs/2402.16617
Reference link: https://twitter. com/HowardYen1/status/1762474556101661158
The above is the detailed content of New work by Chen Danqi's team: Llama-2 context is expanded to 128k, 10 times throughput only requires 1/6 of the memory. For more information, please follow other related articles on the PHP Chinese website!

 An easy-to-understand explanation of how to set up two-step authentication in ChatGPT!May 12, 2025 pm 05:37 PM
An easy-to-understand explanation of how to set up two-step authentication in ChatGPT!May 12, 2025 pm 05:37 PMChatGPT Security Enhanced: Two-Stage Authentication (2FA) Configuration Guide Two-factor authentication (2FA) is required as a security measure for online platforms. This article will explain in an easy-to-understand manner the 2FA setup procedure and its importance in ChatGPT. This is a guide for those who want to use ChatGPT safely. Click here for OpenAI's latest AI agent, OpenAI Deep Research ⬇️ [ChatGPT] What is OpenAI Deep Research? A thorough explanation of how to use it and the fee structure! table of contents ChatG
![[For businesses] ChatGPT training | A thorough introduction to 8 free training options, subsidies, and examples!](https://img.php.cn/upload/article/001/242/473/174704251871181.jpg?x-oss-process=image/resize,p_40) [For businesses] ChatGPT training | A thorough introduction to 8 free training options, subsidies, and examples!May 12, 2025 pm 05:35 PM
[For businesses] ChatGPT training | A thorough introduction to 8 free training options, subsidies, and examples!May 12, 2025 pm 05:35 PMThe use of generated AI is attracting attention as the key to improving business efficiency and creating new businesses. In particular, OpenAI's ChatGPT has been adopted by many companies due to its versatility and accuracy. However, the shortage of personnel who can effectively utilize ChatGPT is a major challenge in implementing it. In this article, we will explain the necessity and effectiveness of "ChatGPT training" to ensure successful use of ChatGPT in companies. We will introduce a wide range of topics, from the basics of ChatGPT to business use, specific training programs, and how to choose them. ChatGPT training improves employee skills
 A thorough explanation of how to use ChatGPT to streamline your Twitter operations!May 12, 2025 pm 05:34 PM
A thorough explanation of how to use ChatGPT to streamline your Twitter operations!May 12, 2025 pm 05:34 PMImproved efficiency and quality in social media operations are essential. Particularly on platforms where real-time is important, such as Twitter, requires continuous delivery of timely and engaging content. In this article, we will explain how to operate Twitter using ChatGPT from OpenAI, an AI with advanced natural language processing capabilities. By using ChatGPT, you can not only improve your real-time response capabilities and improve the efficiency of content creation, but you can also develop marketing strategies that are in line with trends. Furthermore, precautions for use
![[For Mac] Explaining how to get started and how to use the ChatGPT desktop app!](https://img.php.cn/upload/article/001/242/473/174704239752855.jpg?x-oss-process=image/resize,p_40) [For Mac] Explaining how to get started and how to use the ChatGPT desktop app!May 12, 2025 pm 05:33 PM
[For Mac] Explaining how to get started and how to use the ChatGPT desktop app!May 12, 2025 pm 05:33 PMChatGPT Mac desktop app thorough guide: from installation to audio functions Finally, ChatGPT's desktop app for Mac is now available! In this article, we will thoroughly explain everything from installation methods to useful features and future update information. Use the functions unique to desktop apps, such as shortcut keys, image recognition, and voice modes, to dramatically improve your business efficiency! Installing the ChatGPT Mac version of the desktop app Access from a browser: First, access ChatGPT in your browser.
 What is the character limit for ChatGPT? Explanation of how to avoid it and upper limits by modelMay 12, 2025 pm 05:32 PM
What is the character limit for ChatGPT? Explanation of how to avoid it and upper limits by modelMay 12, 2025 pm 05:32 PMWhen using ChatGPT, have you ever had experiences such as, "The output stopped halfway through" or "Even though I specified the number of characters, it didn't output properly"? This model is very groundbreaking and not only allows for natural conversations, but also allows for email creation, summary papers, and even generate creative sentences such as novels. However, one of the weaknesses of ChatGPT is that if the text is too long, input and output will not work properly. OpenAI's latest AI agent, "OpenAI Deep Research"
 What is ChatGPT's voice input and voice conversation function? Explaining how to set it up and how to use itMay 12, 2025 pm 05:27 PM
What is ChatGPT's voice input and voice conversation function? Explaining how to set it up and how to use itMay 12, 2025 pm 05:27 PMChatGPT is an innovative AI chatbot developed by OpenAI. It not only has text input, but also features voice input and voice conversation functions, allowing for more natural communication. In this article, we will explain how to set up and use the voice input and voice conversation functions of ChatGPT. Even when you can't take your hands off, ChatGPT responds and responds with audio just by talking to you, which brings great benefits in a variety of situations, such as busy business situations and English conversation practice. A detailed explanation of how to set up the smartphone app and PC, as well as how to use each.
 An easy-to-understand explanation of how to use ChatGPT for job hunting and job hunting!May 12, 2025 pm 05:26 PM
An easy-to-understand explanation of how to use ChatGPT for job hunting and job hunting!May 12, 2025 pm 05:26 PMThe shortcut to success! Effective job change strategies using ChatGPT In today's intensifying job change market, effective information gathering and thorough preparation are key to success. Advanced language models like ChatGPT are powerful weapons for job seekers. In this article, we will explain how to effectively utilize ChatGPT to improve your job hunting efficiency, from self-analysis to application documents and interview preparation. Save time and learn techniques to showcase your strengths to the fullest, and help you make your job search a success. table of contents Examples of job hunting using ChatGPT Efficiency in self-analysis: Chat
 An easy-to-understand explanation of how to create and output mind maps using ChatGPT!May 12, 2025 pm 05:22 PM
An easy-to-understand explanation of how to create and output mind maps using ChatGPT!May 12, 2025 pm 05:22 PMMind maps are useful tools for organizing information and coming up with ideas, but creating them can take time. Using ChatGPT can greatly streamline this process. This article will explain in detail how to easily create mind maps using ChatGPT. Furthermore, through actual examples of creation, we will introduce how to use mind maps on various themes. Learn how to effectively organize and visualize your ideas and information using ChatGPT. OpenAI's latest AI agent, OpenA


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 Linux new version
SublimeText3 Linux latest version

