
Home >Technology peripherals >AI >Generate 25 frames of high-quality animation in two steps, calculated as 8% of SVD | Playable online
Generate 25 frames of high-quality animation in two steps, calculated as 8% of SVD | Playable online

- PHPzforward
- 2024-02-20 15:54:161022browse
The computing resources consumed are only 2/25 of the traditional Stable Video Diffusion (SVD) model!
AnimateLCM-SVD-xt is released, changing the video diffusion model for repeated denoising, which is both time-consuming and requires a lot of calculations.
Let’s first look at the generated animation effect.
Cyberpunk style is easy to control, the boy is wearing headphones, standing in the neon city street:
 Picture
Picture
Realistic The wind is okay, a newlywed couple cuddles together, holding exquisite bouquets, witnessing love under the ancient stone wall:
 Picture
Picture
Science fiction style, There is also a visual sense of aliens invading the earth:
 Picture
Picture
AnimateLCM-SVD-xt is produced by MMLab, Avolution AI, Shanghai, Chinese University of Hong Kong Researchers from the Artificial Intelligence Laboratory and SenseTime Research Institute jointly proposed.
 Picture
Picture
You can generate 25 frame resolution 576x1024 high-quality animation in 2~8 steps, andno need Classifier guidance, the video generated in 4 steps can achieve high fidelity, faster and more efficient than traditional SVD:
 Picture
Picture
At present, the AnimateLCM code will be open source and there will be an online demo available for trial play.
Get started with the demo
As you can see from the demo interface, AnimateLCM currently has three versions. AnimateLCM-SVD-xt is a general-purpose image to video generation; AnimateLCM-t2v tends to personalize text to video. Generate; AnimateLCM-i2v generates personalized images to videos.
 Picture
Picture
The following is a configuration area. You can choose the basic Dreambooth model or the LoRA model, and adjust the LoRA alpha value through the slider. .
 Picture
Picture
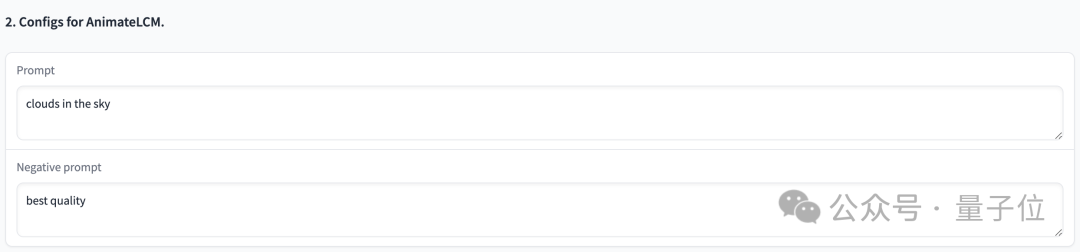
Next, you can enter prompt and negative prompt to guide the content and quality of the generated animation:
 Picture
Picture
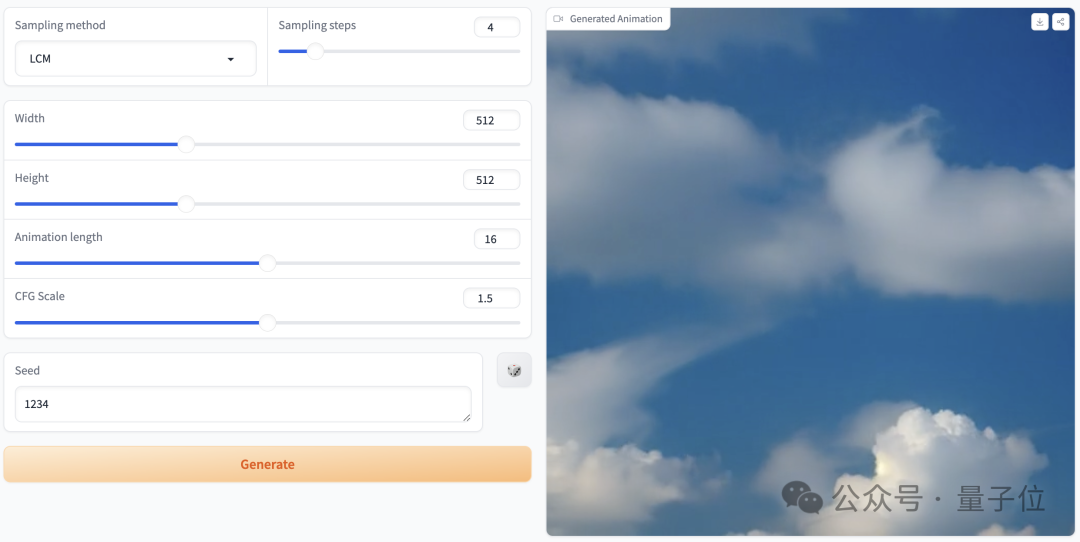
There are also some parameters that can be adjusted:
 Picture
Picture
We have tried it out, and the prompt is "clouds in the sky", the parameter settings are as shown above, and when the sampling step is only 4 steps, the generated effect is like this:
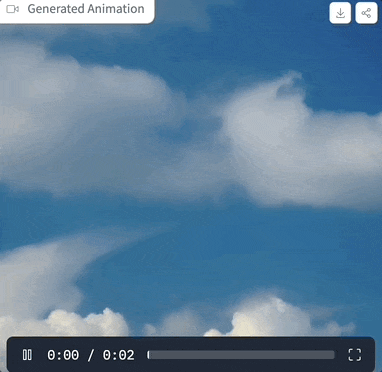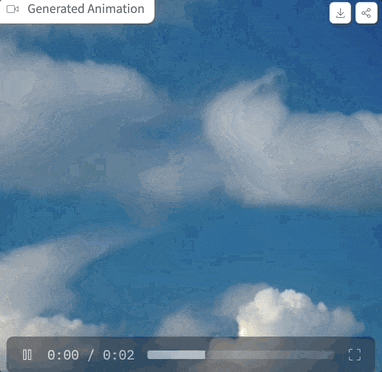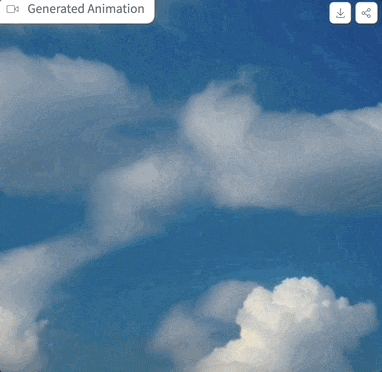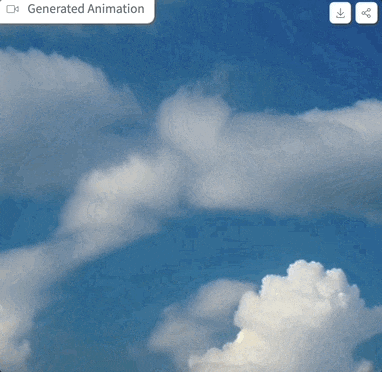 Picture
Picture
When the sampling step is 25 steps, the prompt word "a boy holding a rabbit", the effect is as follows:
 Picture
Picture
Look at the official release again display effect. The comparison of the effects of 2 steps, 4 steps and 8 steps is as follows:
 Picture
Picture
The more steps, the better the animation quality. Only 4 steps of AnimateLCM can Achieve high fidelity:
 Picture
Picture
Various styles can be achieved:
 Picture
Picture
 Picture
Picture
How to do it?
Be aware that although video diffusion models have received increasing attention due to their ability to generate coherent and high-fidelity videos, one of the difficulties is that the iterative denoising process is not only time-consuming but also computationally intensive, which also This limits its scope of application.
And in this work AnimateLCM, the researchers were inspired by the Consistency Model(CM), which simplifies the pre-trained image diffusion model to reduce the steps required for sampling, and Successfully extended the latent consistency model (LCM) on conditional image generation.
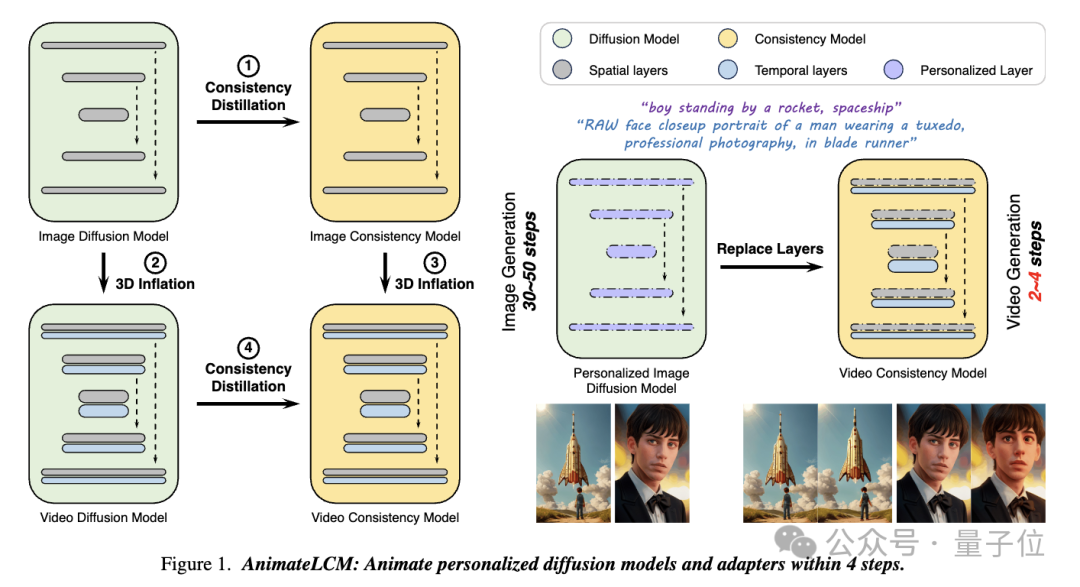 Picture
Picture
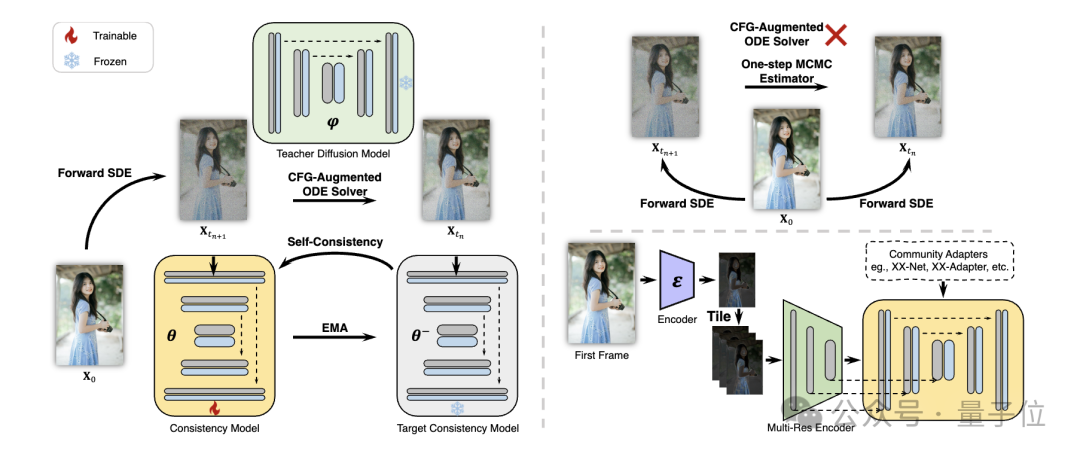
Specifically, the researchers proposed a Decoupled Consistency Learning(Decoupled Consistency Learning)Strategy.
First distill the stable diffusion model into an image consistency model on a high-quality image-text data set, and then perform consistency distillation on video data to obtain a video consistency model. This strategy improves training efficiency by training separately at the spatial and temporal levels.
 Picture
Picture
In addition, in order to be able to implement various functions of plug-and-play adapters in the Stable Diffusion community (for example, using ControlNet Controlled generation), the researchers also proposed the Teacher-Free Adaptation (Teacher-Free Adaptation) strategy to make the existing control adapter more consistent with the consistency model, Achieve better controllable video generation.
 Picture
Picture
Both quantitative and qualitative experiments prove the effectiveness of the method.
In the zero-sample text-to-video generation task on the UCF-101 dataset, AnimateLCM achieved the best performance on both FVD and CLIPSIM metrics.
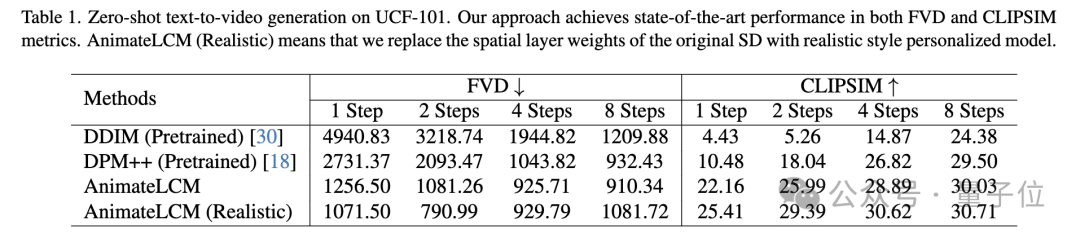 Picture
Picture
 Picture
Picture
Ablation study validates decoupled consistency learning and specific initialization Effectiveness of the strategy:
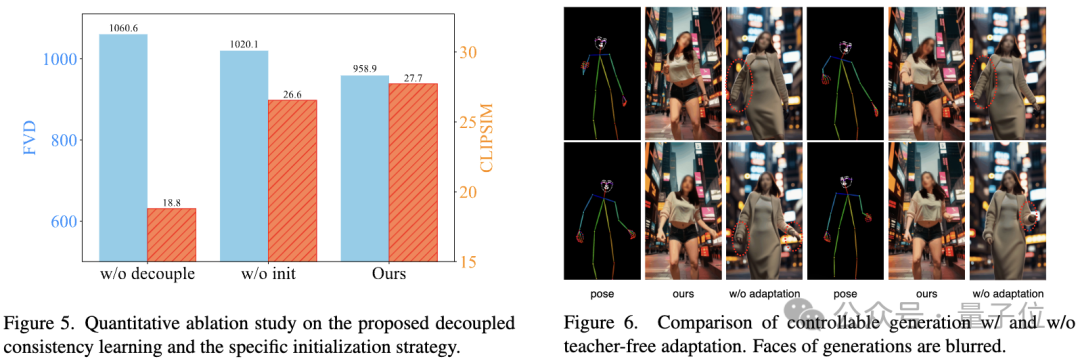 Picture
Picture
Project link:
[1]https://animatelcm.github.io/
[2]https://huggingface.co/wangfuyun/AnimateLCM-SVD-xt
The above is the detailed content of Generate 25 frames of high-quality animation in two steps, calculated as 8% of SVD | Playable online. For more information, please follow other related articles on the PHP Chinese website!