



Written before&The author’s personal summary
In recent years, the 3D occupancy prediction task in the field of autonomous driving has been widely studied by academia and industry because of its unique advantages. focus on. This task provides detailed information for autonomous driving planning and navigation by reconstructing the 3D structure of the surrounding environment. However, most current mainstream methods rely on labels generated based on LiDAR point clouds to supervise network training. In a recent OccNeRF study, the authors proposed a self-supervised multi-camera occupancy prediction method called Parameterized Occupancy Fields. This method solves the problem of boundarylessness in outdoor scenes and reorganizes the sampling strategy. Then, through volume rendering (Volume Rendering) technology, the occupied field is converted into a multi-camera depth map and supervised by multi-frame photometric consistency (Photometric Error). In addition, the method also utilizes a pre-trained open vocabulary semantic segmentation model to generate 2D semantic labels to endow the occupation field with semantic information. This open-lexicon semantic segmentation model is able to segment different objects in a scene and assign semantic labels to each object. By combining these semantic labels with occupancy fields, models are able to better understand the environment and make more accurate predictions. In summary, the OccNeRF method achieves high-precision occupancy prediction in autonomous driving scenarios through the combined use of parameterized occupancy fields, volume rendering, and multi-frame photometric consistency, as well as with an open vocabulary semantic segmentation model. This method provides the autonomous driving system with more environmental information and is expected to improve the safety and reliability of autonomous driving.

- Paper link: https://arxiv.org/pdf/2312.09243.pdf
- Code link: https://github.com /LinShan-Bin/OccNeRF
OccNeRF Problem Background
In recent years, with the rapid development of artificial intelligence technology, great progress has been made in the field of autonomous driving . 3D perception is the basis for autonomous driving and provides necessary information for subsequent planning and decision-making. In traditional methods, lidar can directly capture accurate 3D data, but the high cost of the sensor and the sparse scanning points limit its practical application. In contrast, image-based 3D sensing methods are low-cost and effective and have received increasing attention. Multi-camera 3D object detection has been the mainstream of 3D scene understanding tasks for some time, but it cannot cope with the infinite categories in the real world and is subject to dataThe influence of long tail distribution.
3D occupancy prediction can well compensate for these shortcomings by directly reconstructing the geometry of the surrounding scene through multi-view input. Most existing methods focus on model design and performance optimization, relying on labels generated by LiDAR point clouds to supervise network training, which is not available in image-based systems. In other words, we still need to use expensive data collection vehicles to collect training data and waste a large amount of real data without LiDAR point cloud-assisted annotation, which limits the development of 3D occupancy prediction to a certain extent. Therefore exploring self-supervised 3D occupancy prediction is a very valuable direction.
Detailed explanation of OccNeRF algorithmThe following figure shows the basic process of the OccNeRF method. The model takes multi-camera images
as input, first uses 2D backbone to extract features of N pictures , and then directly obtains 3D features through simple projection and bilinear interpolation (in Parameterized space below), and finally optimize the 3D features through the 3D CNN network and output the prediction results. To train the model, the OccNeRF method generates a depth map of the current frame through volume rendering and introduces the previous and next frames to calculate the photometric loss. To introduce more timing information, OccNeRF uses an occupancy field to render multi-frame depth maps and calculate the loss function. At the same time, OccNeRF also renders 2D semantic maps simultaneously and is supervised by the Open Lexicon Semantic Segmentation Model.
 Parameterized Occupancy Fields
Parameterized Occupancy Fields
Parameterized Occupancy Fields are proposed to solve the
perception range gap between the camera and the occupied gridThis One question. Theoretically, cameras can capture objects at infinite distances, while previous occupancy prediction models only consider closer spaces (for example, within 40 m). In supervised methods, the model can learn to ignore distant objects based on supervision signals; in unsupervised methods, if only the near space is still considered, the presence of a large number of out-of-range objects in the image will have a negative impact on the optimization process. Influence. Based on this, OccNeRF adopts Parameterized Occupancy Fields to model an unlimited range of outdoor scenes.
The parameterization space in OccNeRF is divided into internal and external. The inner space is a linear mapping of the original coordinates, maintaining a high resolution; while the outer space represents an infinite range. Specifically, OccNeRF makes the following changes to the coordinates of the points in the 3D space:
where is the coordinate,, is an adjustable parameter, indicating the boundary value corresponding to the internal space. is also an adjustable parameter, indicating the proportion of the internal space occupied. When generating parameterized occupancy fields, OccNeRF first samples in the parameterized space, obtains the original coordinates through inverse transformation, then projects the original coordinates onto the image plane, and finally obtains the occupancy field through sampling and three-dimensional convolution.
Multi-frame Depth Estimation
In order to train the occupancy network, OccNeRF chooses to use volume rendering to convert occupancy into a depth map and supervise it through a photometric loss function. The sampling strategy is important when rendering depth maps. In the parameterized space, if you directly sample uniformly based on depth or parallax, the sampling points will be unevenly distributed in the internal or external space, which will affect the optimization process. Therefore, OccNeRF proposes to directly sample uniformly in the parameterized space under the premise that the camera center is close to the origin. Additionally, OccNeRF renders and supervises multi-frame depth maps while training.
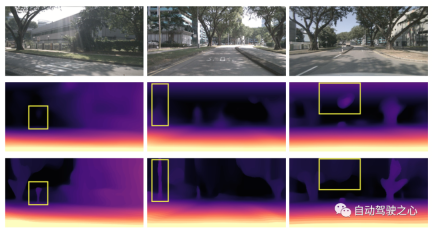
The figure below visually demonstrates the advantages of using parameterized space representation. (The third line uses the parameterized space, and the second line does not.)
Semantic Label Generation
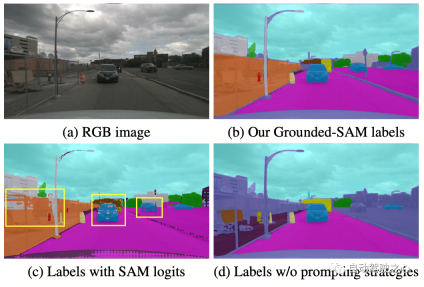
OccNeRF uses pre-trained GroundedSAM (Grounding DINO SAM) generates 2D semantic labels. In order to generate high-quality labels, OccNeRF adopts two strategies. One is cue word optimization, which replaces vague categories in nuScenes with precise descriptions. Three strategies are used in OccNeRF to optimize prompt words: ambiguous word replacement (car is replaced by sedan), word-to-word multi-word (manmade is replaced by building, billboard and bridge), and additional information is introduced (bicycle is replaced by bicycle, bicyclist). The second is to determine the category based on the confidence of the detection frame in Grounding DINO instead of the pixel-by-pixel confidence given by SAM. The semantic label effect generated by OccNeRF is as follows:
OccNeRF Experimental Results
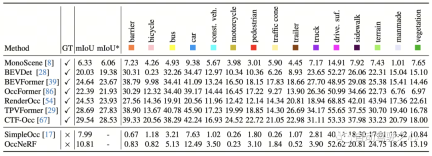
OccNeRF conducted experiments on nuScenes and mainly completed many Perspective self-supervised depth estimation and 3D occupancy prediction tasks. Multi-view self-supervised depth estimationOccNeRF’s multi-view self-supervised depth estimation performance on nuScenes is shown in the table below. It can be seen that OccNeRF based on 3D modeling significantly surpasses the 2D method and also surpasses SimpleOcc, largely due to the unlimited spatial range that OccNeRF models for outdoor scenes.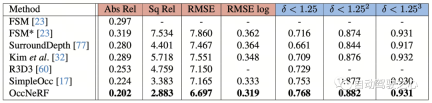


Summary
At a time when many car manufacturers are trying to remove LiDAR sensors, how to make good use of thousands of unlabeled image data is an important issue. And OccNeRF has brought us a valuable attempt.
The above is the detailed content of OccNeRF: No lidar data supervision required at all. For more information, please follow other related articles on the PHP Chinese website!

 A Comprehensive Guide to ExtrapolationApr 15, 2025 am 11:38 AM
A Comprehensive Guide to ExtrapolationApr 15, 2025 am 11:38 AMIntroduction Suppose there is a farmer who daily observes the progress of crops in several weeks. He looks at the growth rates and begins to ponder about how much more taller his plants could grow in another few weeks. From th
 The Rise Of Soft AI And What It Means For Businesses TodayApr 15, 2025 am 11:36 AM
The Rise Of Soft AI And What It Means For Businesses TodayApr 15, 2025 am 11:36 AMSoft AI — defined as AI systems designed to perform specific, narrow tasks using approximate reasoning, pattern recognition, and flexible decision-making — seeks to mimic human-like thinking by embracing ambiguity. But what does this mean for busine
 Evolving Security Frameworks For The AI FrontierApr 15, 2025 am 11:34 AM
Evolving Security Frameworks For The AI FrontierApr 15, 2025 am 11:34 AMThe answer is clear—just as cloud computing required a shift toward cloud-native security tools, AI demands a new breed of security solutions designed specifically for AI's unique needs. The Rise of Cloud Computing and Security Lessons Learned In th
 3 Ways Generative AI Amplifies Entrepreneurs: Beware Of Averages!Apr 15, 2025 am 11:33 AM
3 Ways Generative AI Amplifies Entrepreneurs: Beware Of Averages!Apr 15, 2025 am 11:33 AMEntrepreneurs and using AI and Generative AI to make their businesses better. At the same time, it is important to remember generative AI, like all technologies, is an amplifier – making the good great and the mediocre, worse. A rigorous 2024 study o
 New Short Course on Embedding Models by Andrew NgApr 15, 2025 am 11:32 AM
New Short Course on Embedding Models by Andrew NgApr 15, 2025 am 11:32 AMUnlock the Power of Embedding Models: A Deep Dive into Andrew Ng's New Course Imagine a future where machines understand and respond to your questions with perfect accuracy. This isn't science fiction; thanks to advancements in AI, it's becoming a r
 Is Hallucination in Large Language Models (LLMs) Inevitable?Apr 15, 2025 am 11:31 AM
Is Hallucination in Large Language Models (LLMs) Inevitable?Apr 15, 2025 am 11:31 AMLarge Language Models (LLMs) and the Inevitable Problem of Hallucinations You've likely used AI models like ChatGPT, Claude, and Gemini. These are all examples of Large Language Models (LLMs), powerful AI systems trained on massive text datasets to
 The 60% Problem — How AI Search Is Draining Your TrafficApr 15, 2025 am 11:28 AM
The 60% Problem — How AI Search Is Draining Your TrafficApr 15, 2025 am 11:28 AMRecent research has shown that AI Overviews can cause a whopping 15-64% decline in organic traffic, based on industry and search type. This radical change is causing marketers to reconsider their whole strategy regarding digital visibility. The New
 MIT Media Lab To Put Human Flourishing At The Heart Of AI R&DApr 15, 2025 am 11:26 AM
MIT Media Lab To Put Human Flourishing At The Heart Of AI R&DApr 15, 2025 am 11:26 AMA recent report from Elon University’s Imagining The Digital Future Center surveyed nearly 300 global technology experts. The resulting report, ‘Being Human in 2035’, concluded that most are concerned that the deepening adoption of AI systems over t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

Dreamweaver Mac version
Visual web development tools

Atom editor mac version download
The most popular open source editor

