
Home >Technology peripherals >AI >Understand LLM evaluation using Arthur Bench in one article
Understand LLM evaluation using Arthur Bench in one article

- 王林forward
- 2024-02-04 17:33:02825browse
Hello folks, I am Luga, today we will talk about technologies related to the artificial intelligence (AI) ecological field - LLM evaluation.

1. Challenges faced by traditional text evaluation
In recent years, the rapid development and improvement of large language models (LLM) have made traditional text evaluation methods in Some aspects may no longer apply. In the field of text evaluation, we have heard of methods such as "word occurrence" based evaluation methods, such as BLEU, and "pre-trained natural language processing models" based evaluation methods, such as BERTScore. These methods provide more accurate indicators for evaluating the quality and similarity of texts. The rapid development of LLM has brought new challenges and opportunities to the field of text evaluation. We need to continuously explore and improve evaluation methods to adapt to this development trend.
Although these methods once performed well, with the development of LLM ecological technology, they gradually appear not to be powerful enough to fully meet today's needs.
With the rapid development and improvement of LLM, we face new challenges and opportunities. LLM's capabilities and performance levels continue to increase, making it possible that word occurrence-based evaluation methods such as BLEU may not fully capture the quality and semantic accuracy of LLM-generated text. In contrast, LLM can generate more fluent, coherent, and semantically rich text, and traditional word occurrence-based evaluation methods cannot accurately measure these advantages.
In addition, evaluation methods based on pre-trained models, such as BERTScore, although performing well on many tasks, also face some challenges. Pre-trained models may not fully take into account the unique characteristics of the LLM (language model) and its performance on a specific task. Therefore, relying solely on evaluation methods based on pre-trained models may not fully evaluate the capabilities of LLM. This means that we need further research and development of new assessment methods to more accurately assess and understand the performance and capabilities of LLMs in specific tasks. This may involve task-specific fine-tuning and customization of the LLM to better suit mission requirements. At the same time, we also need to take into account the diversity of assessment methods and combine manual assessment and other measurement indicators to obtain more comprehensive and accurate assessment results. By continuously improving and developing evaluation methods, we can better understand and exploit the potential of LLM and drive further progress in the field of natural language processing.
2. Why is LLM guidance assessment needed? And what challenges does it bring?
Generally speaking, the most valuable thing about using LLM guidance assessment method in actual business scenarios is its speed and sensitivity.
1. Efficiency
First of all, the implementation speed of using LLM to guide assessment is usually faster. Compared to previous assessment pipelines, creating an LLM-guided assessment requires relatively little effort and is easy to implement. For the LLM Guided Assessment, only two things need to be prepared: a written description describing the assessment criteria, and examples to use in the prompt template. Compared to building your own pre-trained NLP model or fine-tuning an existing NLP model to serve as an evaluator, it is more efficient to use LLM to complete these tasks. Iteration of the evaluation criteria is also faster using LLM.
2. Sensitivity
Secondly, LLM is generally more sensitive than pre-trained NLP models and the evaluation methods discussed previously. This sensitivity has a positive impact in some respects, allowing LLM to handle specific situations more flexibly. However, this sensitivity may also make LLM assessment results less predictable.
As we discussed before, LLM evaluators are more sensitive than other evaluation methods. However, there are many different ways to configure LLM as an evaluator, and its behavior can vary greatly depending on the configuration chosen. Furthermore, another challenge is that LLM evaluators may get stuck if the evaluation involves too many inferential steps or requires processing too many variables simultaneously. Therefore, when designing and implementing assessments, the configuration of the LLM and the complexity of the assessment tasks need to be carefully considered to ensure accurate and valid assessment results.
Due to the characteristics of LLM, its evaluation results may be affected by different configurations and parameter settings. This means that when evaluating LLMs, the model needs to be carefully selected and configured to ensure that it behaves as expected. Different configurations may lead to different output results, so the evaluator needs to spend some time and effort to adjust and optimize the settings of the LLM to obtain accurate and reliable evaluation results.
Additionally, evaluators may face some challenges when faced with evaluation tasks that require complex reasoning or the simultaneous processing of multiple variables. This is because the reasoning ability of LLM may be limited when dealing with complex situations. The LLM may require additional effort to address these tasks to ensure the accuracy and reliability of the assessment.
3. What is Arthur Bench?
Arthur Bench is an open source evaluation tool used to compare the performance of generative text models (LLM). It can be used to evaluate different LLM models, cues, and hyperparameters and provide detailed reports on LLM performance on various tasks.
The main features of Arthur Bench include:The main features of Arthur Bench include:
- Compare different LLM models: Arthur Bench can be used to compare the performance of different LLM models, including models from different vendors, different versions of models, and models using different training data sets.
- Evaluate Tips: Arthur Bench can be used to evaluate the impact of different tips on LLM performance. Prompts are instructions used to guide LLM in generating text.
- Testing hyperparameters: Arthur Bench can be used to test the impact of different hyperparameters on LLM performance. Hyperparameters are settings that control the behavior of LLM.
Generally speaking, the Arthur Bench workflow mainly involves the following stages, and the detailed analysis is as follows:
1. Task definition
At this stage, we need to clarify our assessment goals. Arthur Bench supports a variety of assessment tasks, including:
- Q&A: Test LLM on open-ended, challenging or ambiguous questions ability to understand and answer.
- Summary: Evaluate LLM's ability to extract key information from text and generate concise summaries.
- Translation: Examine LLM’s ability to translate accurately and fluently between different languages.
- Code generation: Test the ability of LLM to generate code based on natural language descriptions.
2. Model selection
At this stage, the main work is to select the evaluation objects. Arthur Bench supports a variety of LLM models, covering leading technologies from well-known institutions such as OpenAI, Google AI, Microsoft, etc., such as GPT-3, LaMDA, Megatron-Turing NLG, etc. We can select specific models for evaluation based on research needs.
3. Parameter configuration
After completing the model selection, proceed to fine-tuning. To more accurately evaluate LLM performance, Arthur Bench allows users to configure hints and hyperparameters.
- Tip: Guide LLM in the direction and content of generated text, such as questions, descriptions, or instructions.
- Hyperparameters: Key settings that control LLM behavior, such as learning rate, number of training steps, model architecture, etc.
Through refined configuration, we can deeply explore the performance differences of LLM under different parameter settings and obtain evaluation results with more reference value.
4. Assessment run: automated process
The last step is to conduct task assessment with the help of automated process. Typically, Arthur Bench provides an automated assessment process that requires simple configuration to run assessment tasks. It will automatically perform the following steps:
- Call the LLM model and generate text output.
- For specific tasks, apply corresponding evaluation indicators for analysis.
- Generate detailed reports and present evaluation results.
4. Arthur Bench usage scenario analysis
As the key to a fast, data-driven LLM evaluation, Arthur Bench mainly provides the following solutions, specifically involving:
1. Model selection and verification
Model selection and verification are crucial steps in the field of artificial intelligence and are of great significance to ensure the validity and reliability of the model. In this process, Arthur Bench's role was crucial. His goal is to provide companies with a reliable comparison framework to help them make informed decisions among the many large language model (LLM) options through the use of consistent metrics and evaluation methods.
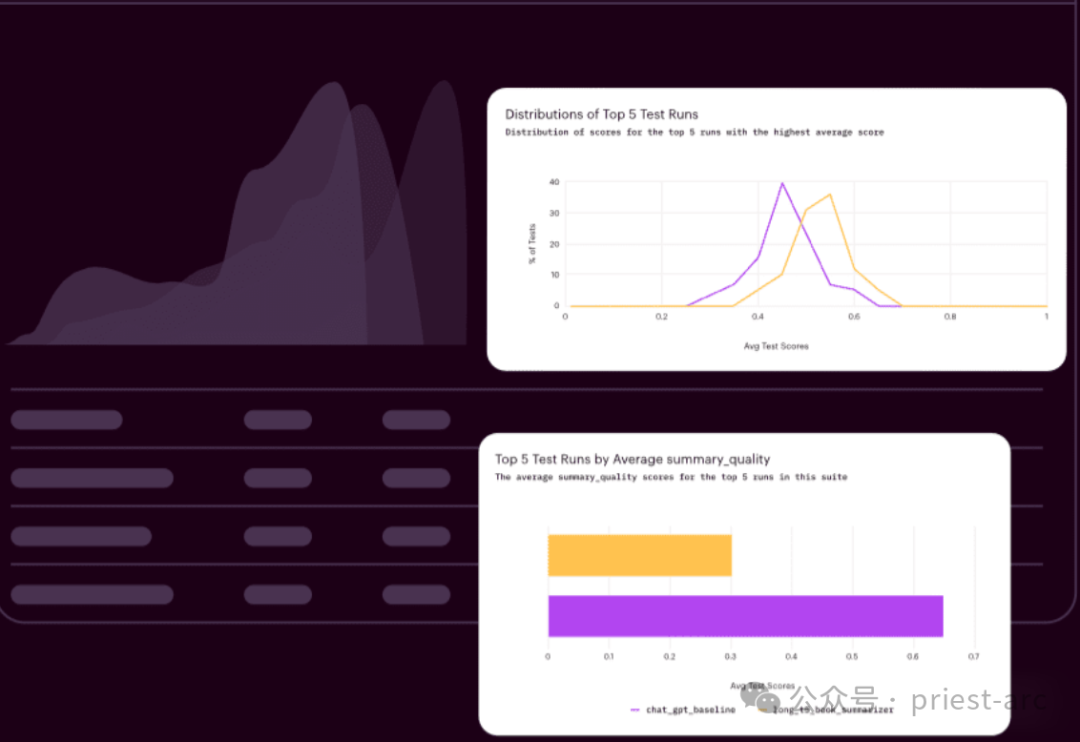
Arthur Bench will use his expertise and experience to evaluate each LLM option and ensure that consistent metrics are used to compare their strengths and weaknesses. He will consider factors such as model performance, accuracy, speed, resource requirements and more to ensure companies can make informed and clear choices.
By using consistent metrics and evaluation methodologies, Arthur Bench will provide companies with a reliable comparison framework, allowing them to fully evaluate the benefits and limitations of each LLM option. This will enable companies to make informed decisions to maximize the rapid advances in artificial intelligence and ensure the best possible experience with their applications.
2. Budget and Privacy Optimization
When choosing an artificial intelligence model, not all applications require the most advanced or expensive large language models (LLM). In some cases, mission requirements can be met using less expensive AI models.
This budget optimization approach can help companies make wise choices with limited resources. Instead of going for the most expensive or state-of-the-art model, choose the right one based on your specific needs. The more affordable models may perform slightly worse than state-of-the-art LLMs in some aspects, but for some simple or standard tasks, Arthur Bench can still provide a solution that meets the needs.
Additionally, Arthur Bench emphasized that bringing the model in-house allows for greater control over data privacy. For applications involving sensitive data or privacy issues, companies may prefer to use their own internally trained models rather than relying on external, third-party LLMs. By using internal models, companies can gain greater control over the processing and storage of data and better protect data privacy.
3. Translate academic benchmarks into real-world performance
Academic benchmarks refer to model evaluation indicators and methods established in academic research. These indicators and methods are usually specific to a specific task or domain and can effectively evaluate the performance of the model in that task or domain.
However, academic benchmarks do not always directly reflect the performance of models in the real world. This is because application scenarios in the real world are often more complex and require more factors to be considered, such as data distribution, model deployment environment, etc.
Arthur Bench helps translate academic benchmarks into real-world performance. It achieves this goal in the following ways:
- Provides a comprehensive set of evaluation indicators covering multiple aspects of the model's accuracy, efficiency, robustness, etc. These indicators can not only reflect the performance of the model under academic benchmarks, but also the potential performance of the model in the real world.
- Supports multiple model types and can compare different types of models. This enables enterprises to choose the model that best suits their application scenarios.
- Provides visual analysis tools to help enterprises intuitively understand the performance differences of different models. This enables businesses to make decisions more easily.
5. Arthur Bench Feature Analysis
As the key to a fast, data-driven LLM assessment, Arthur Bench has the following features:
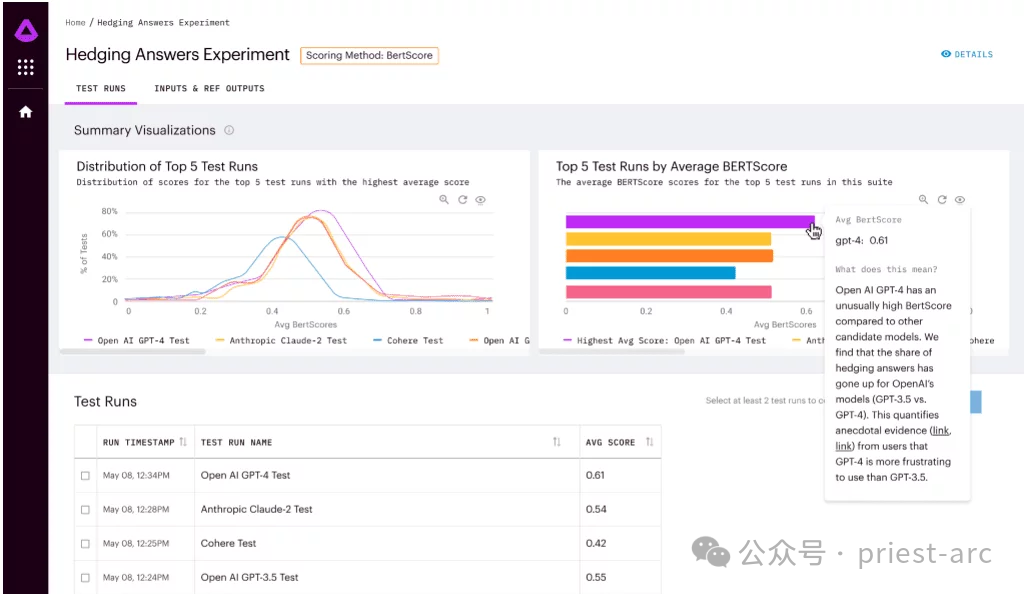
1. Full set of scores Metrics
Arthur Bench has a comprehensive set of scoring metrics covering everything from summary quality to user experience. He can use these scoring metrics at any time to evaluate and compare different models. The combined use of these scoring metrics can help him fully understand the strengths and weaknesses of each model.
The scope of these scoring indicators is very wide, including but not limited to summary quality, accuracy, fluency, grammatical correctness, context understanding ability, logical coherence, etc. Arthur Bench will evaluate each model against these metrics and combine the results into a comprehensive score to assist companies in making informed decisions.
Additionally, if a company has specific needs or concerns, Arthur Bench can create and add custom scoring metrics based on the company's requirements. This is done to better meet the company's specific needs and ensure that the assessment process is consistent with the company's goals and standards.
2. Local and cloud-based versions
For those who prefer local deployment and autonomous control, you can get access from the GitHub repository permissions and deploy Arthur Bench to your local environment. In this way, everyone can fully master and control the operation of Arthur Bench and customize and configure it according to their own needs.
On the other hand, for those users who prefer convenience and flexibility, cloud-based SaaS products are also available. You can choose to register to access and use Arthur Bench through the cloud. This method eliminates the need for cumbersome local installation and configuration, and enables you to enjoy the provided functions and services immediately.
3. Completely open source
As an open source project, Arthur Bench shows its typical open source characteristics in terms of transparency, scalability and community collaboration. This open source nature provides users with a wealth of advantages and opportunities to gain a deeper understanding of how the project works, and to customize and extend it to suit their needs. At the same time, the openness of Arthur Bench also encourages users to actively participate in community collaboration, collaborate and develop with other users. This open cooperation model helps promote the continuous development and innovation of the project, while also creating greater value and opportunities for users.
In short, Arthur Bench provides an open and flexible framework that enables users to customize evaluation indicators, and has been widely used in the financial field. Partnerships with Amazon Web Services and Cohere further advance the framework, encouraging developers to create new metrics for Bench and contribute to advances in the field of language model evaluation.
Reference:
- [1] https://github.com/arthur-ai/bench
- [2] https://neurohive.io/ en/news/arthur-bench-framework-for-evaluating-language-models/
The above is the detailed content of Understand LLM evaluation using Arthur Bench in one article. For more information, please follow other related articles on the PHP Chinese website!