

 Technology peripheralsAILearn and grow from criticism like humans, 1317 comments increased LLaMA2's winning rate by 30 times
Technology peripheralsAILearn and grow from criticism like humans, 1317 comments increased LLaMA2's winning rate by 30 timesLearn and grow from criticism like humans, 1317 comments increased LLaMA2's winning rate by 30 times

Existing large model alignment methods include examplebased supervised fine-tuning (SFT) and score feedbackbased reinforcement learning (RLHF). However, the score can only reflect the quality of the current response and cannot clearly indicate the shortcomings of the model. In contrast, we humans typically learn and adjust our behavioral patterns from verbal feedback. Just like the review comments are not just a score, but also include many reasons for acceptance or rejection.
So, can large language models also use language feedback to improve themselves like humans?
Researchers from the Chinese University of Hong Kong and Tencent AI Lab recently proposed an innovative research called Contrastive Unlikelihood Learning (CUT). The research uses language feedback to adjust language models so that they can learn and improve from different criticisms, just like humans. This research aims to improve the quality and accuracy of language models to make them more consistent with the way humans think. By comparing non-likelihood training, researchers hope to enable the language model to better understand and adapt to diverse language usage situations, thereby improving its performance in natural language processing tasks. This innovative research is expected to provide a simple and effective method for language models
#CUT. By using only 1317 pieces of language feedback data, CUT was able to significantly improve the winning rate of LLaMA2-13b on AlpacaEval, soaring from 1.87% to 62.56%, and successfully defeated 175B DaVinci003. What’s exciting is that CUT can also perform iterative cycles of exploration, criticism, and improvement like other reinforcement learning and reinforcement learning reinforcement feedback (RLHF) frameworks. In this process, the criticism stage can be completed by the automatic evaluation model to achieve self-evaluation and improvement of the entire system.
The author conducted four rounds of iterations on LLaMA2-chat-13b, gradually improving the model's performance on AlpacaEval from 81.09% to 91.36%. Compared with alignment technology based on score feedback (DPO), CUT performs better under the same data size. The results reveal that language feedback has great potential for development in the field of alignment, opening up new possibilities for future alignment research. This finding has important implications for improving the accuracy and efficiency of alignment techniques and provides guidance for achieving better natural language processing tasks.

- ##Paper title: Reasons to Reject? Aligning Language Models with Judgments
- Paper link: https://arxiv.org/abs/2312.14591
- Github link: https://github.com/ wwxu21/CUT
Alignment of large models
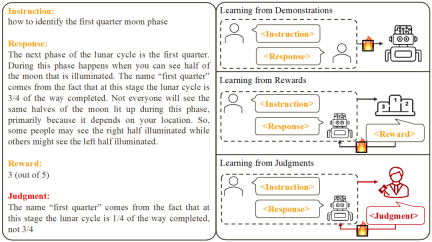
Based on existing work , researchers summarized two common large model alignment methods:
1. Learning from Demonstration: Based on ready-made instructions - Reply Yes, using supervised training methods to align large models.
Advantages: stable training; simple implementation.- Disadvantages: The cost of collecting high-quality and diverse example data is high; it is impossible to learn from error responses; example data is often irrelevant to the model.
- 2. Learning from Rewards: Score the command-reply pair and use reinforcement learning to train the model to maximize its response score.
Advantages: Correct responses and error responses can be used simultaneously; feedback signals are related to the model.
- Disadvantages: The feedback signal is sparse; the training process is often complicated.
- This study focuses on learning from Language feedback (Learning from Judgments): giving instructions - replying to writing comments, based on the language feedback Improve the defects of the model and maintain the advantages of the model, thereby improving the model performance.
It can be seen that language feedback inherits the advantages of score feedback. Compared with score feedback, verbal feedback is more informative: instead of letting the model guess what it did right and what it went wrong, verbal feedback can directly point out detailed deficiencies and directions for improvement. Unfortunately, however, researchers have found that there is currently no effective way to fully utilize verbal feedback. To this end, researchers have proposed an innovative framework, CUT, designed to take full advantage of language feedback.
Contrastive non-likelihood training
The core idea of CUT is to learn from contrast. Researchers compare the responses of large models under different conditions to find out which parts are satisfactory and should be maintained, and which parts are flawed and need to be modified. Based on this, researchers use maximum likelihood estimation (MLE) to train the satisfactory part, and use unlikelihood training (UT) to modify the flaws in the reply.
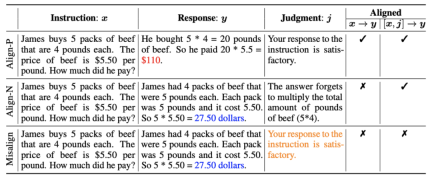
1. Alignment scenario: As shown in the figure above, the researchers considered two alignment scenarios:
a) : This is a commonly understood alignment scenario where a reply needs to faithfully follow instructions and be consistent with human expectations and values.
: This is a commonly understood alignment scenario where a reply needs to faithfully follow instructions and be consistent with human expectations and values.
b) : This scenario introduces verbal feedback as an additional condition. In this scenario, the response must satisfy both instructions and verbal feedback. For example, when receiving a negative feedback, the large model needs to make mistakes based on the issues mentioned in the corresponding feedback.
: This scenario introduces verbal feedback as an additional condition. In this scenario, the response must satisfy both instructions and verbal feedback. For example, when receiving a negative feedback, the large model needs to make mistakes based on the issues mentioned in the corresponding feedback.
2. Alignment data: As shown in the figure above, based on the above two alignment scenarios, researchers constructed three types of alignment data:
a) Align-P: The large model generated satisfactory responses and thus received positive feedback. Obviously, Align-P satisfies alignment in both  and
and  scenarios.
scenarios.
b) Align-N: The large model generated flawed (blue bold) replies and therefore received negative feedback. For Align-N, alignment is not satisfied in  . But after considering this negative feedback, Align-N is still aligned in the
. But after considering this negative feedback, Align-N is still aligned in the  scenario.
scenario.
c) Misalign: Real negative feedback in Align-N is replaced with a fake positive feedback. Obviously, Misalign does not satisfy alignment in both  and
and  scenarios.
scenarios.
3. Learn from contrast:
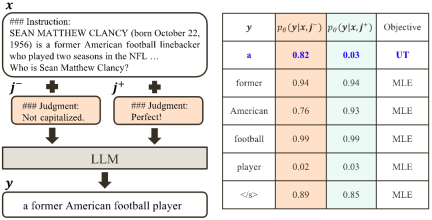
a) Align-N vs. Misalign: The difference between the two is mainly the degree of alignment under  . Given the powerful in-context learning capabilities of large models, the alignment polarity flip from Align-N to Misalign is usually accompanied by a significant change in the generation probability of specific words, especially those words that are closely related to real negative feedback. . As shown in the figure above, under the condition of Align-N (left channel), the probability of large model generating "a" is significantly higher than Misalign (right channel). And the place where the probability changes significantly is where the big model makes a mistake.
. Given the powerful in-context learning capabilities of large models, the alignment polarity flip from Align-N to Misalign is usually accompanied by a significant change in the generation probability of specific words, especially those words that are closely related to real negative feedback. . As shown in the figure above, under the condition of Align-N (left channel), the probability of large model generating "a" is significantly higher than Misalign (right channel). And the place where the probability changes significantly is where the big model makes a mistake.
In order to learn from this comparison, the researchers input Align-N and Misalign data to the large model at the same time to obtain the generation probabilities of the output words under the two conditions and
and . Words that have a significantly higher generation probability in the
. Words that have a significantly higher generation probability in the  condition than in the
condition than in the  condition are marked as inappropriate words. Specifically, researchers used the following criteria to quantify the definition of inappropriate words:
condition are marked as inappropriate words. Specifically, researchers used the following criteria to quantify the definition of inappropriate words:
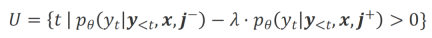
where  is Hyperparameters that trade off precision and recall during inappropriate word recognition.
is Hyperparameters that trade off precision and recall during inappropriate word recognition.
The researchers used unlikelihood training (UT) on these identified inappropriate words, thereby forcing the large model to explore more satisfactory responses. For other reply words, researchers still use maximum likelihood estimation (MLE) to optimize:
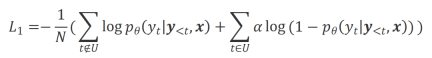
where is a hyperparameter that controls the proportion of non-likelihood training,
is a hyperparameter that controls the proportion of non-likelihood training,  is the number of reply words.
is the number of reply words.
b) Align-P v.s. Align-N: The difference between the two mainly lies in the degree of alignment under  . Essentially, the large model controls the quality of the output reply by introducing language feedback of different polarities. Therefore, the comparison between the two can inspire large models to distinguish satisfactory responses from defective responses. Specifically, we learn from this set of comparisons via the following maximum likelihood estimation (MLE) loss:
. Essentially, the large model controls the quality of the output reply by introducing language feedback of different polarities. Therefore, the comparison between the two can inspire large models to distinguish satisfactory responses from defective responses. Specifically, we learn from this set of comparisons via the following maximum likelihood estimation (MLE) loss:
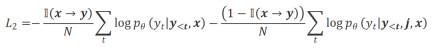
where  is an indicator function that returns 1 if the data satisfies
is an indicator function that returns 1 if the data satisfies  alignment, otherwise it returns 0.
alignment, otherwise it returns 0.
CUT’s final training goal combines the above two sets of comparisons:  .
.
Experimental evaluation
1. Offline alignment
In order to save Qian, the researchers first tried to use existing language feedback data to align large models. This experiment was used to demonstrate CUT's ability to utilize language feedback.
a) General model
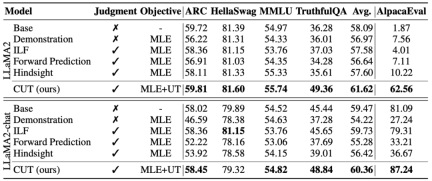
As shown in the table above, for general model alignment, the researchers used 1317 alignment data provided by Shepherd to compare CUT under cold start (LLaMA2) and hot start (LLaMA2-chat) conditions. versus existing methods for learning from linguistic feedback.
Under the cold start experiment based on LLaMA2, CUT significantly surpassed existing alignment methods on the AlpacaEval test platform, fully proving its advantages in utilizing language feedback. Moreover, CUT has also achieved significant improvements in TruthfulQA compared to the base model, which reveals that CUT has great potential in alleviating the hallucination problem of large models.
In the hot start scenario based on LLaMA2-chat, existing methods perform poorly in improving LLaMA2-chat and even have negative effects. However, CUT can further improve the performance of the base model on this basis, once again verifying the great potential of CUT in utilizing language feedback.
b) Expert model
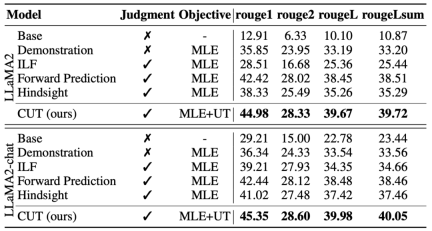
The researchers also tested on specific expert tasks (text abstract ) on the CUT alignment effect. As shown in the table above, CUT also achieves significant improvements compared to existing alignment methods on expert tasks.
2. Online alignment
Research on offline alignment has successfully demonstrated the powerful alignment performance of CUT. Now, researchers are further exploring online alignment scenarios that are closer to practical applications. In this scenario, researchers iteratively annotate the responses of the target large model with language feedback so that the target model can be more accurately aligned based on the language feedback associated with it. The specific process is as follows:
-
Step 1: Collect instructions
 , and obtain the reply from the target large model .
, and obtain the reply from the target large model .
-
Step 2: In response to the above instruction-reply pair, mark the language feedback .
-
Step 3: Use CUT to fine-tune the target large model based on the collected triplet data.
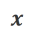
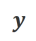
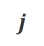
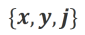
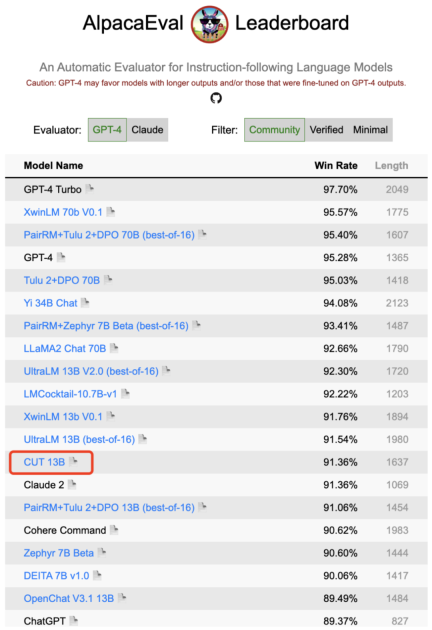
As shown in the figure above, after four rounds of online alignment iterations, CUT has only Under the conditions of 4000 training data and a small 13B model size, it can still achieve an impressive score of 91.36. This achievement further demonstrates CUT’s excellent performance and huge potential.
3. AI comment model
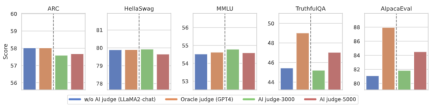
Annotation taking into account language feedback To reduce the cost, researchers try to train a judgment model to automatically annotate language feedback for the target large model. As shown in the figure above, the researchers used 5,000 pieces (AI Judge-5000) and 3,000 pieces (AI Judge-3000) of language feedback data to train two review models. Both review models have achieved remarkable results in optimizing the target large-scale model, especially the effect of AI Judge-5000.
This proves the feasibility of using AI comment models to align target large models, and also highlights the importance of comment model quality in the entire alignment process. This set of experiments also provides strong support for reducing annotation costs in the future.
4. Language feedback vs. score feedback
In order to deeply explore the huge potential of language feedback in large model alignment, researchers compared CUT based on language feedback with the method based on score feedback (DPO). In order to ensure a fair comparison, the researchers selected 4,000 sets of the same instruction-response pairs as experimental samples, allowing CUT and DPO to learn from the score feedback and language feedback corresponding to these data respectively.
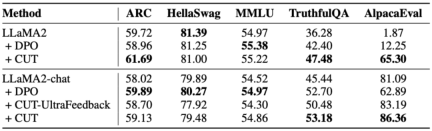
As shown in the table above, CUT performed significantly better than DPO in the cold start (LLaMA2) experiment. In the hot start (LLaMA2-chat) experiment, CUT can achieve results comparable to DPO on tasks such as ARC, HellaSwag, MMLU, and TruthfulQA, and is significantly ahead of DPO on the AlpacaEval task. This experiment confirmed the greater potential and advantages of linguistic feedback compared to fractional feedback during large model alignment.
Summary and Challenges
In this work, the researchers systematically explored the current status and innovation of language feedback in large model alignment We proposed an alignment framework CUT based on language feedback, revealing the great potential and advantages of language feedback in the field of large-scale model alignment. In addition, there are some new directions and challenges in the research of language feedback, such as:
1. The quality of the comment model: Although research The researchers have successfully demonstrated the feasibility of training a review model, but when observing the model output, they still find that the review model often gives less than accurate reviews. Therefore, improving the quality of the review model is of great significance for large-scale use of language feedback for alignment in the future.
2. Introduction of new knowledge: When language feedback involves knowledge that the large model lacks, even if the large model can accurately Errors were identified, but there was no clear direction for correction. Therefore, it is very important to supplement the knowledge that the large model lacks while aligning.
3. Multi-modal alignment: The success of language models has promoted the research of multi-modal large models, such as language, speech, A combination of images and videos. In these multi-modal scenarios, studying language feedback and feedback of corresponding modalities has ushered in new definitions and challenges.
The above is the detailed content of Learn and grow from criticism like humans, 1317 comments increased LLaMA2's winning rate by 30 times. For more information, please follow other related articles on the PHP Chinese website!

 The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AM
The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AMThe term "AI-ready workforce" is frequently used, but what does it truly mean in the supply chain industry? According to Abe Eshkenazi, CEO of the Association for Supply Chain Management (ASCM), it signifies professionals capable of critic
 How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AM
How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AMThe decentralized AI revolution is quietly gaining momentum. This Friday in Austin, Texas, the Bittensor Endgame Summit marks a pivotal moment, transitioning decentralized AI (DeAI) from theory to practical application. Unlike the glitzy commercial
 Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AM
Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AMEnterprise AI faces data integration challenges The application of enterprise AI faces a major challenge: building systems that can maintain accuracy and practicality by continuously learning business data. NeMo microservices solve this problem by creating what Nvidia describes as "data flywheel", allowing AI systems to remain relevant through continuous exposure to enterprise information and user interaction. This newly launched toolkit contains five key microservices: NeMo Customizer handles fine-tuning of large language models with higher training throughput. NeMo Evaluator provides simplified evaluation of AI models for custom benchmarks. NeMo Guardrails implements security controls to maintain compliance and appropriateness
 AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AM
AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AMAI: The Future of Art and Design Artificial intelligence (AI) is changing the field of art and design in unprecedented ways, and its impact is no longer limited to amateurs, but more profoundly affecting professionals. Artwork and design schemes generated by AI are rapidly replacing traditional material images and designers in many transactional design activities such as advertising, social media image generation and web design. However, professional artists and designers also find the practical value of AI. They use AI as an auxiliary tool to explore new aesthetic possibilities, blend different styles, and create novel visual effects. AI helps artists and designers automate repetitive tasks, propose different design elements and provide creative input. AI supports style transfer, which is to apply a style of image
 How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AM
How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AMZoom, initially known for its video conferencing platform, is leading a workplace revolution with its innovative use of agentic AI. A recent conversation with Zoom's CTO, XD Huang, revealed the company's ambitious vision. Defining Agentic AI Huang d
 The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AM
The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AMWill AI revolutionize education? This question is prompting serious reflection among educators and stakeholders. The integration of AI into education presents both opportunities and challenges. As Matthew Lynch of The Tech Edvocate notes, universit
 The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AM
The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AMThe development of scientific research and technology in the United States may face challenges, perhaps due to budget cuts. According to Nature, the number of American scientists applying for overseas jobs increased by 32% from January to March 2025 compared with the same period in 2024. A previous poll showed that 75% of the researchers surveyed were considering searching for jobs in Europe and Canada. Hundreds of NIH and NSF grants have been terminated in the past few months, with NIH’s new grants down by about $2.3 billion this year, a drop of nearly one-third. The leaked budget proposal shows that the Trump administration is considering sharply cutting budgets for scientific institutions, with a possible reduction of up to 50%. The turmoil in the field of basic research has also affected one of the major advantages of the United States: attracting overseas talents. 35
 All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AM
All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI unveils the powerful GPT-4.1 series: a family of three advanced language models designed for real-world applications. This significant leap forward offers faster response times, enhanced comprehension, and drastically reduced costs compared t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

WebStorm Mac version
Useful JavaScript development tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 English version
Recommended: Win version, supports code prompts!

