
Home >Technology peripherals >AI >UCLA Chinese propose a new self-playing mechanism! LLM trains itself, and the effect is better than that of GPT-4 expert guidance.
UCLA Chinese propose a new self-playing mechanism! LLM trains itself, and the effect is better than that of GPT-4 expert guidance.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-02-03 08:00:161366browse
Synthetic data has become the most important cornerstone in the evolution of large language models.
At the end of last year, some netizens revealed that former OpenAI chief scientist Ilya had repeatedly stated that there is no data bottleneck in the development of LLM, and synthetic data can solve most problems.
 Picture
Picture
Nvidia senior scientist Jim Fan concluded after studying the latest batch of papers that he believes that synthetic data Combined with traditional game and image generation technology, LLM can achieve huge self-evolution.
 Picture
Picture
The paper that formally proposed this method was written by a Chinese team from UCLA.
 Picture
Picture
Paper address: https://www.php.cn/link/236522d75c8164f90a85448456e1d1aa
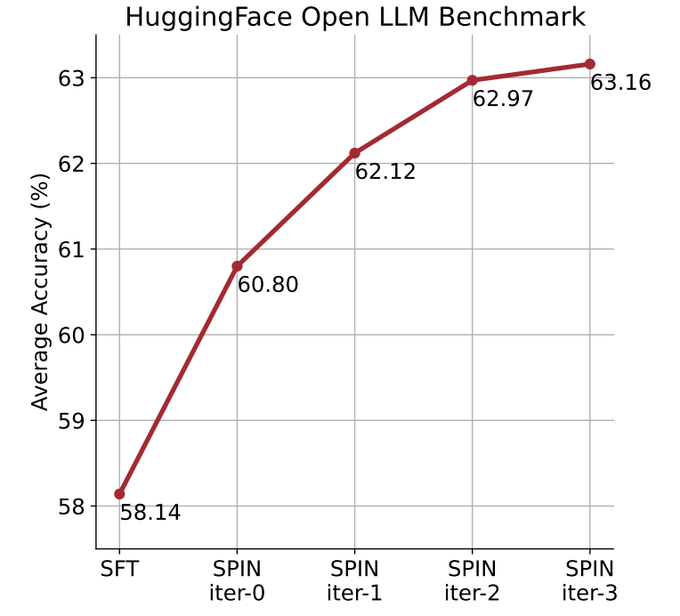
They used the self-playing mechanism (SPIN) to generate synthetic data, and through self-fine-tuning methods, without relying on new data sets, the average score of the weak LLM on the Open LLM Leaderboard Benchmark was improved from 58.14. to 63.16.
The researchers proposed a self-fine-tuning method called SPIN, through self-playing - LLM and its previous iteration version Conduct confrontation to gradually improve the performance of the language model.
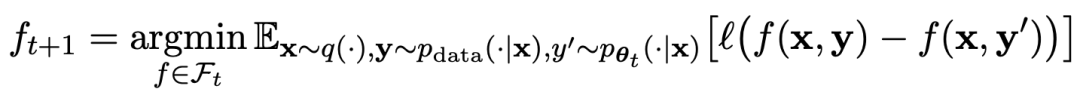 Picture
Picture
This way, there is no need for additional human annotated data or feedback from a higher-level language model to complete the model's self- evolution.
The parameters of the main model and the opponent model are exactly the same. Play against yourself with two different versions.
The game process can be summarized by the formula:
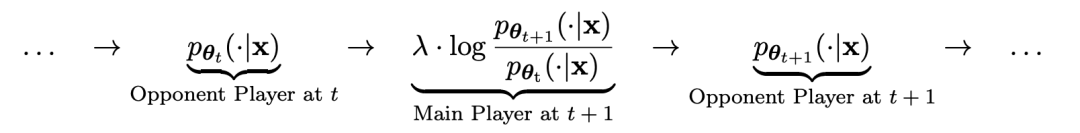 Picture
Picture
Self-Play The training method, in summary, the idea is roughly as follows:
By training the main model to distinguish the response generated by the opponent model and the human target response, the opponent model is a language model obtained by rounds of iterations, and the target is to generate responses that are as indistinguishable as possible.
Assuming that the language model parameter obtained in the t-th round of iteration is θt, then in the t-th round of iteration, use θt as the opponent player to fine-tune each prompt x in the data set for supervision, Use θt to generate the response y'.
Then optimize the new language model parameters θt 1 so that it can distinguish y' from the human response y in the supervised fine-tuning dataset. This can form a gradual process and gradually approach the target response distribution.
Here, the loss function of the main model adopts logarithmic loss, taking into account the function value difference between y and y'.
Add KL divergence regularization to the opponent model to prevent the model parameters from deviating too much.
The specific adversarial game training objectives are shown in Formula 4.7. It can be seen from the theoretical analysis that when the response distribution of the language model is equal to the target response distribution, the optimization process converges.
If you use synthetic data generated after the game for training, and then use SPIN for self-fine-tuning, the performance of LLM can be effectively improved.
 Picture
Picture
But then simply fine-tuning again on the initial fine-tuning data will cause performance degradation.
SPIN only requires the initial model itself and the existing fine-tuned data set, so that LLM can improve itself through SPIN.
In particular, SPIN even outperforms models trained with additional GPT-4 preference data via DPO.
 Picture
Picture
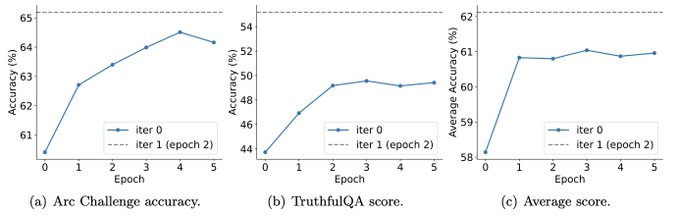
And experiments also show that iterative training can improve model performance more effectively than training with more epochs.
 Picture
Picture
Extending the training duration of a single iteration will not reduce the performance of SPIN, but it will reach its limit.
The more iterations, the more obvious the effect of SPIN.
After reading this paper, netizens sighed:
Synthetic data will dominate the development of large language models, and the research on large language models This will be very good news for readers!
 Picture
Picture
Self-playing allows LLM to continuously improve
Specifically , the SPIN system developed by the researchers is a system in which two mutually influencing models promote each other.
The LLM of the previous iteration t, denoted by 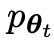 , is used by the researchers to generate responses y to prompts x in the manually annotated SFT dataset .
, is used by the researchers to generate responses y to prompts x in the manually annotated SFT dataset .
The next goal is to find a new LLM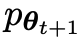 that is able to distinguish
that is able to distinguish 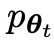 generated responses y from those generated by humans The response y'.
generated responses y from those generated by humans The response y'.
This process can be viewed as a two-player game:
Main player or new LLM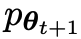 Try to discern between opponent player responses and human-generated responses, while opponent or old LLM
Try to discern between opponent player responses and human-generated responses, while opponent or old LLM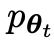 generated responses are as similar as possible to the data in the human-annotated SFT dataset.
generated responses are as similar as possible to the data in the human-annotated SFT dataset.
New LLM obtained by fine-tuning the old 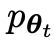
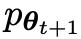 prefer
prefer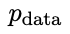 's response, resulting in a distribution
's response, resulting in a distribution 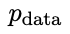 that is more consistent with
that is more consistent with 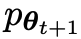 .
.
In the next iteration, the newly obtained LLM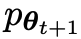 becomes the response generated opponent, and the goal of the self-playing process is that the LLM eventually converges to
becomes the response generated opponent, and the goal of the self-playing process is that the LLM eventually converges to 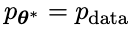 , Such that the strongest LLM is no longer able to distinguish between its previously generated version of the response and the human-generated version.
, Such that the strongest LLM is no longer able to distinguish between its previously generated version of the response and the human-generated version.
How to use SPIN to improve model performance
The researchers designed a two-player game in which the main model goal is to distinguish the responses generated by LLM and human-generated responses. At the same time, the role of the adversary is to produce responses that are indistinguishable from those of humans. Central to the researchers' approach is training the primary model.
First explain how to train the main model to distinguish LLM's responses from human responses.
The core of the researchers' approach is a self-game mechanism, in which the main player and the opponent are both from the same LLM, but from different iterations.
More specifically, the opponent is the old LLM from the previous iteration, and the main player is the new LLM to learn in the current iteration. Iteration t 1 includes the following two steps: (1) training the main model, (2) updating the opponent model.
Training the master model
First, the researchers will explain how to train the master player to distinguish between LLM responses and human responses. Inspired by the integral probability measure (IPM), the researchers formulated the objective function:
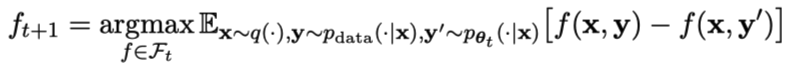 Picture
Picture
Update opponent Model
The goal of the adversary model is to find a better LLM such that it produces a response that is indistinguishable from the master model's p data.
Experiment
SPIN effectively improves benchmark performance
Researchers use HuggingFace Open LLM Leaderboard as Extensive evaluation to prove the effectiveness of SPIN.
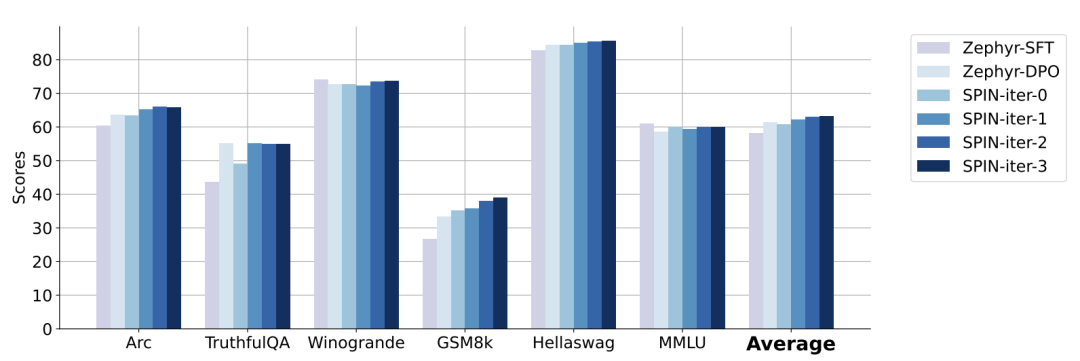
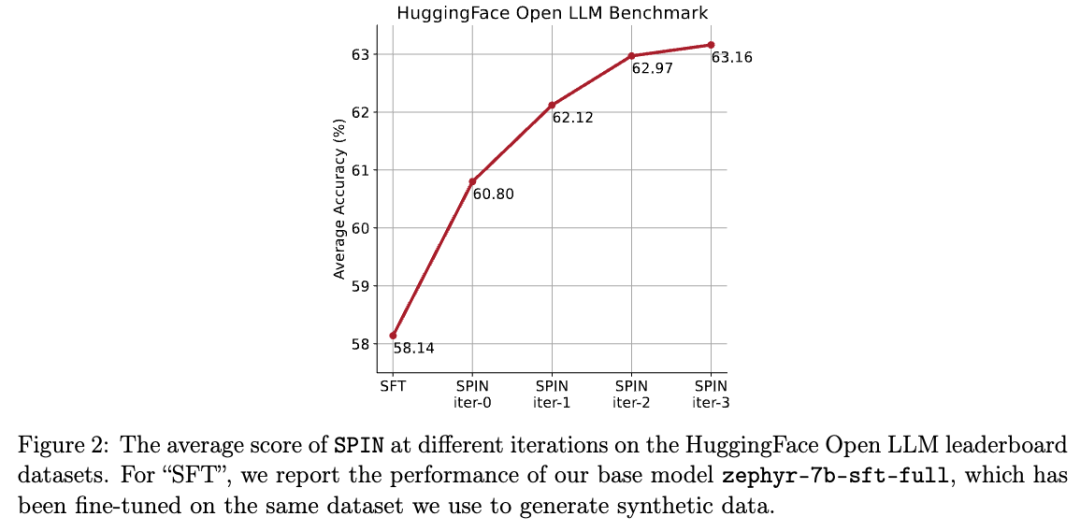
In the figure below, the researchers compared the performance of the model fine-tuned by SPIN after 0 to 3 iterations with the base model zephyr-7b-sft-full.
Researchers can observe that SPIN shows significant results in improving model performance by further leveraging the SFT dataset, on which the base model has already been tested Full of fine-tuning.
In iteration 0, the model response was generated from zephyr-7b-sft-full, and the researchers observed an overall improvement of 2.66% in the average score.
This improvement is particularly noticeable on the TruthfulQA and GSM8k benchmarks, with increases of more than 5% and 10% respectively.
In Iteration 1, the researchers employed the LLM model from Iteration 0 to generate new responses for SPIN, following the process outlined in Algorithm 1.
This iteration produces a further enhancement of 1.32% on average, which is particularly significant on the Arc Challenge and TruthfulQA benchmarks.
Subsequent iterations continued the trend of incremental improvements in various tasks. At the same time, the improvement at iteration t 1 is naturally smaller
 Picture
Picture
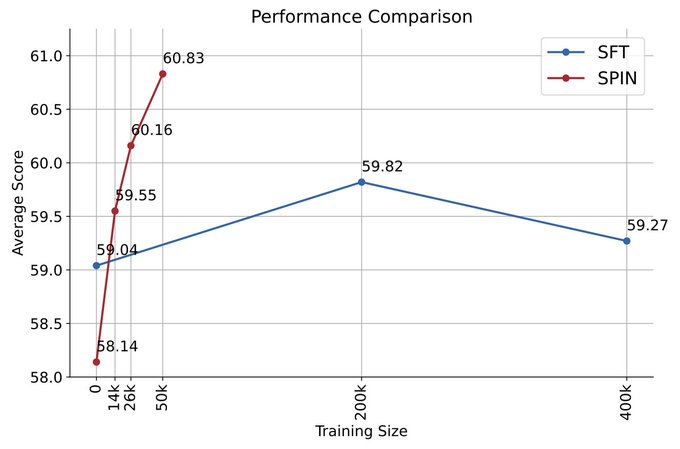
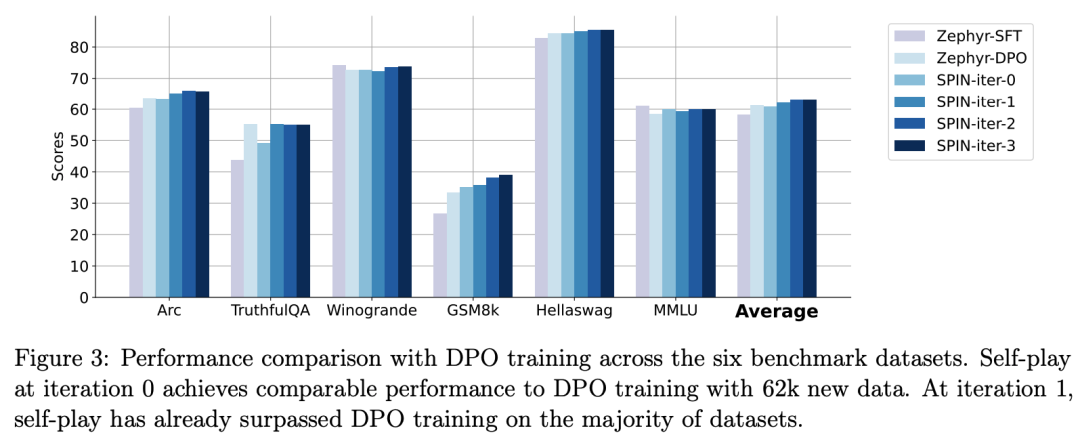
zephyr-7b-beta is derived from zephyr-7b- The model derived from sft-full is trained on approximately 62k preference data using DPO.
The researchers note that DPO requires human input or high-level language model feedback to determine preferences, so data generation is a fairly expensive process.
In contrast, the researchers’ SPIN only requires the initial model itself.
Additionally, unlike DPO, which requires new data sources, the researchers’ approach fully leverages existing SFT datasets.
The following figure shows the performance comparison of SPIN and DPO training at iterations 0 and 1 (using 50k SFT data).
 Picture
Picture
The researchers can observe that although the DPO utilizes more data from new sources, the SPIN based on the existing SFT data changes from iteration 1 Initially, SPIN even exceeded the performance of DPO, and SPIN even outperformed DPO in ranking benchmark tests.
Reference:
The above is the detailed content of UCLA Chinese propose a new self-playing mechanism! LLM trains itself, and the effect is better than that of GPT-4 expert guidance.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- For the first time: Microsoft uses GPT-4 to fine-tune large model instructions, and the zero-sample performance of new tasks is further improved.
- GPT-4 raises concerns, and thousands of tech figures including Musk call for a moratorium on stronger AI development
- watchGPT rebranded as 'Petey” and upgraded to GPT-4 to bypass App Store review
- Alibaba Cloud AnalyticDB (ADB) + LLM: Building an enterprise-specific Chatbot in the AIGC era