
Home >Technology peripherals >AI >The accuracy rate is less than 20%, GPT-4V/Gemini can't read comics! First open source image sequence benchmark
The accuracy rate is less than 20%, GPT-4V/Gemini can't read comics! First open source image sequence benchmark

- 王林forward
- 2024-02-01 19:06:131103browse
OpenAI’s GPT-4V and Google’s Gemini multi-modal large language model have attracted widespread attention from the industry and academia. These models demonstrate deep understanding of video in multiple domains, demonstrating its potential from different perspectives. These advances are widely viewed as an important step toward artificial general intelligence (AGI).
But if I tell you that GPT-4V can even misread the behavior of characters in comics, let me ask: Yuanfang, what do you think?
Let’s take a look at this mini comic series:
 Pictures
Pictures
If you ask the highest intelligence in the biological world - human beings, that is, readers, to describe it, you will most likely say:
 Picture
Picture
Then let’s take a look Look, when the highest intelligence in the machine world - that is, GPT-4V - looks at this mini comic series, what will it describe like this?
 Picture
Picture
GPT-4V, as a machine intelligence recognized as standing at the top of the contempt chain, openly tells lies.
What’s even more outrageous is that even if GPT-4V is given actual life image clips, it will also absurdly recognize the behavior of a person talking to another person while going up the stairs as two people holding " Weapons" fight and play with each other (as shown in the picture below).
 Picture
Picture
Gemini is not far behind. The same image fragment sees the process as a man struggling to go upstairs and arguing with his wife while being locked in inside the house.
 Picture
Picture
These examples come from the latest results of a research team from the University of Maryland and North Carolina Chapel Hill, who launched a system specifically designed for MLLM An inference benchmark for image sequences - Mementos.
Just as Nolan’s film Memento redefined storytelling, Mementos is reshaping the limits of testing artificial intelligence.
As a new benchmark test, it challenges artificial intelligence's understanding of image sequences like memory fragments.
 Pictures
Pictures
Paper link: https://arxiv.org/abs/2401.10529
Project homepage: https://mementos -bench.github.io
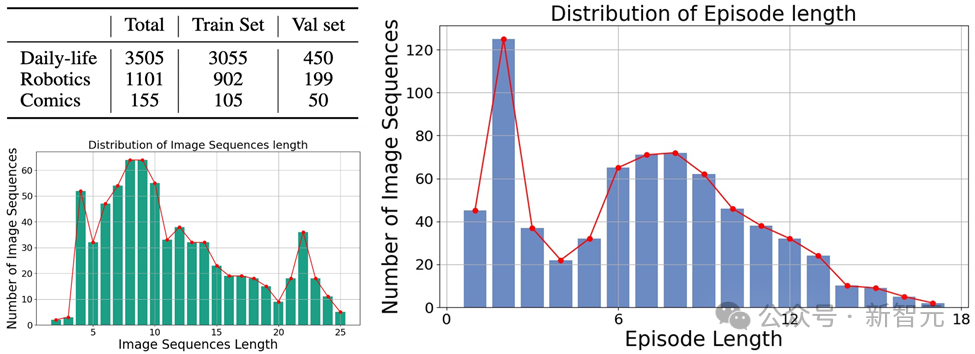
Mementos is the first benchmark test for image sequence reasoning designed specifically for MLLM, focusing on object hallucination and behavioral hallucination of large models on continuous images.
It involves a variety of image types, covering three major categories: real-world images, robot images, and animation images.
and contains 4,761 diverse image sequences of different lengths, each with human-annotated descriptions of the main objects and their behavior in the sequence.
 Picture
Picture
The data is now open source and is still being updated.
Type of hallucination
The author explains in the paper two kinds of hallucinations that MLLM will produce in Mementos: object hallucination and behavioral hallucination. .
As the name suggests, object hallucination is the imagining of a non-existent object (object), while behavioral hallucination is the imagining of actions and behaviors that the object did not perform.
Evaluation method
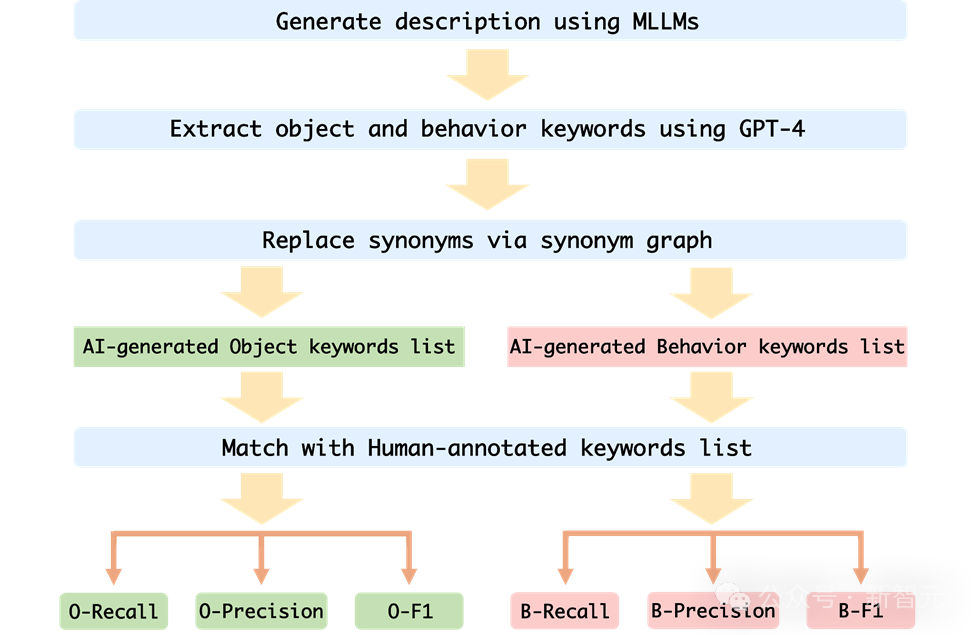
In order to accurately evaluate the behavioral hallucination and object hallucination of MLLM on Mementos, the research team chose to use the image description and person annotation generated by MLLM. Description for keyword matching.
In order to automatically evaluate the performance of each MLLM, the author uses the GPT-4 auxiliary test method to evaluate:
 Picture
Picture
1. The author takes the image sequence and prompt words as input to MLLM, and generates a description corresponding to the corresponding image sequence;
2. Request GPT-4 to extract the object and behavior keywords in the AI-generated description;
3. Obtain two keyword lists: the object keyword list generated by AI and the behavior keyword list generated by AI;
4. Calculate the object keyword list and behavior keyword list generated by AI and the person The recall rate, precision rate and F1 index of the annotated keyword table.
Evaluation results
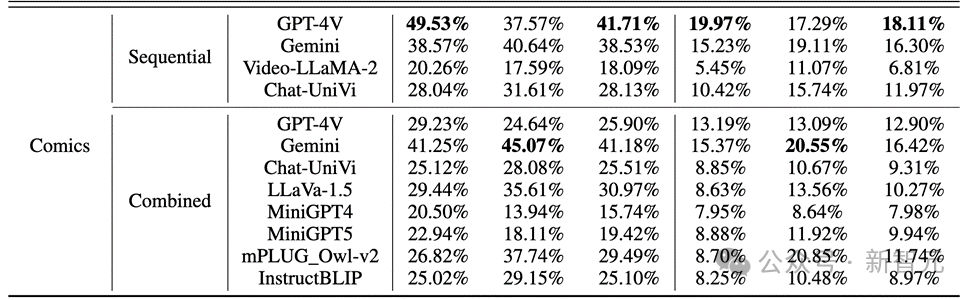
The author evaluated the performance of MLLMs in sequence image reasoning on Mementos, and conducted experiments on nine latest MLLMs including GPT4V and Gemini. Careful assessment.
MLLM is asked to describe the events occurring in the image sequence to evaluate the reasoning ability of MLLM for continuous images.
The results found that, as shown in the figure below, the accuracy of GPT-4V and Gemini for character behavior in the comic data set was less than 20%.
 Picture
Picture
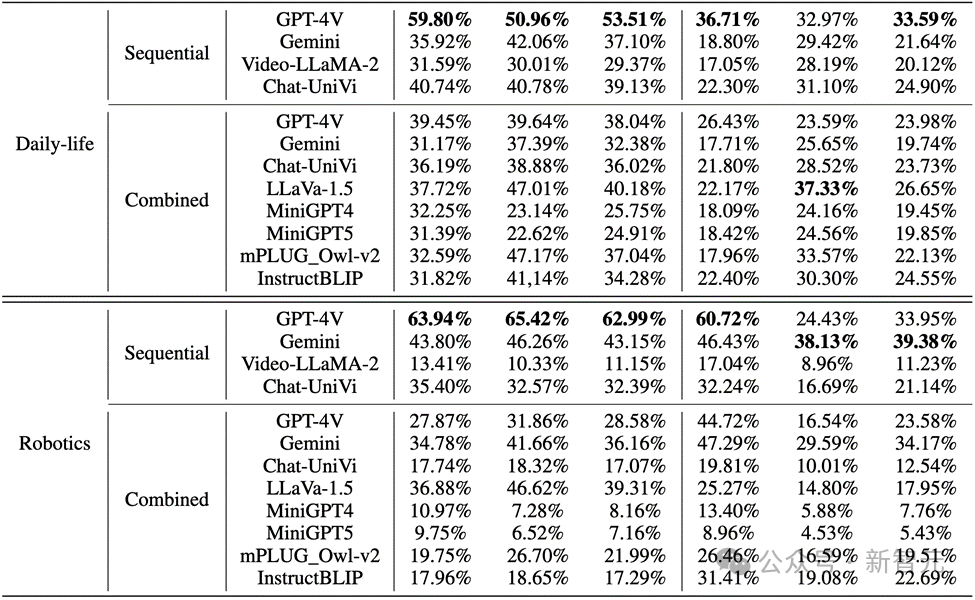
In real-world images and robot images, the performance of GPT-4V and Gemini is not satisfactory:
 Picture
Picture
Key Points
1. GPT-4V and LLaVA-1.5 when evaluating multi-modal large language models These are the best-performing models in black-box and open-source MLLMs respectively. GPT-4V outperforms all other MLLMs in reasoning ability in understanding image sequences, while LLaVA-1.5 is almost on par with or even surpasses the black-box model Gemini in object understanding.
2. Although Video-LLaMA-2 and Chat-UniVi are designed for video understanding, they do not show better advantages than LLaVA-1.5.
3. All MLLMs perform significantly better than behavioral reasoning on the three indicators of object reasoning in image sequences, indicating that current MLLMs are not strong in the ability to autonomously infer behaviors from consecutive images.
4. The black box model performs best in the field of robotics, while the open source model performs relatively well in the field of daily life. This may be related to the distribution shift of the training data.
5. The limitations of training data lead to weak inference capabilities of open source MLLMs. This demonstrates the importance of training data and its direct impact on model performance.
Error reasons
The author analyzed the reasons why current multi-modal large-scale language models fail when processing image sequence reasoning, and mainly identified three error reasons:
1. Interaction between object and behavioral hallucinations
The study hypothesized that incorrect object recognition would lead to inaccurate subsequent behavioral recognition. Quantitative analysis and case studies show that object hallucinations can lead to behavioral hallucinations to a certain extent. For example, when MLLM mistakenly identifies a scene as a tennis court, it may describe a character playing tennis, even though this behavior does not exist in the image sequence.
2. The impact of co-occurrence on behavioral hallucinations
MLLM tends to generate behavioral combinations that are common in image sequence reasoning, which exacerbates Problems with behavioral hallucinations. For example, when processing images from the robotics domain, MLLM may incorrectly describe a robot arm pulling open a drawer after "grabbing the handle" even though the actual action was "grabbing the side of the drawer."
3. The Snowball Effect of Behavioral Illusions
As the image sequence proceeds, errors may gradually accumulate or intensify, which is called Snowball effect. In image sequence reasoning, if errors occur early, these errors may accumulate and amplify in the sequence, resulting in reduced accuracy in object and action recognition.
For example
 Picture
Picture
From As can be seen from the above figure, the reasons for the failure of MLLM include object hallucinations, the correlation between object hallucinations and behavioral hallucinations, and co-occurring behaviors.
For example, after experiencing the object hallucination of "tennis court", MLLM then showed the behavioral hallucination of "holding a tennis racket" (correlation between object hallucination and behavioral hallucination) and the common feeling of "appearing to be playing tennis" current behavior.
 Picture
Picture
#Observing the sample in the picture above, you can find that MLLM mistakenly believes that the chair goes further Lean back and think the chair is broken.
This phenomenon reveals that MLLM can also produce the illusion that some action has occurred on the object for static objects in the image sequence.
 Picture
Picture
#In the above image sequence display of the robotic arm, the robotic arm reaches Next to the handle, MLLM mistakenly believed that the robot arm had grasped the handle, proving that MLLM generates behavioral combinations that are common in image sequence reasoning, thereby creating hallucinations.
 Picture
Picture
In the case above, the old master is not holding the dog, MLLM error It is believed that when walking a dog, the dog must be held on a leash, and "the dog's pole vaulting" is recognized as "creating a fountain".
The large number of errors reflects MLLM’s unfamiliarity with the comic field. In the field of two-dimensional animation, MLLM may require substantial optimization and pre-training.
In the appendix, the author displays failure cases in each major category in detail and conducts in-depth analysis.
Summary
In recent years, multi-modal large-scale language models have demonstrated excellent capabilities in processing various visual-linguistic tasks.
These models, such as GPT-4V and Gemini, are able to understand and generate text related to images, greatly promoting the development of artificial intelligence technology.
However, existing MLLM benchmarks mainly focus on inference based on a single static image, while inference from image sequences is crucial for understanding our changing world. , there are relatively few studies on the ability.
To address this challenge, the researchers proposed a new benchmark "Mementos" to evaluate the capabilities of MLLMs in sequence image reasoning.
Mementos contains 4761 diverse image sequences of different lengths. In addition, the research team also adopted the GPT-4 auxiliary method to evaluate the inference performance of MLLM.
Through careful evaluation of nine latest MLLMs (including GPT-4V and Gemini) on Mementos, the study found that these models exist in accurately describing the dynamic information of a given image sequence. Challenges, often resulting in hallucinations/misrepresentations of objects and their behavior.
Quantitative analysis and case studies identify three key factors affecting sequence image reasoning in MLLMs:
1. Between object and behavioral illusions Correlation;
2. Impact of co-occurring behaviors;
3. Cumulative impact of behavioral hallucinations.
This discovery is of great significance for understanding and improving the ability of MLLMs in processing dynamic visual information. The Mementos benchmark not only reveals the limitations of current MLLMs, but also provides directions for future research and improvements.
With the rapid development of artificial intelligence technology, the application of MLLMs in the field of multi-modal understanding will become more extensive and in-depth. The introduction of the Mementos benchmark not only promotes research in this field, but also provides us with new perspectives to understand and improve how these advanced AI systems process and understand our complex and ever-changing world.
Reference materials:
https://github.com/umd-huanglab/Mementos
The above is the detailed content of The accuracy rate is less than 20%, GPT-4V/Gemini can't read comics! First open source image sequence benchmark. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- ChatGPT Special Topic: The Capabilities and Future of Large Language Models
- The first domestic company, 360 Intelligent Brain passed the trusted AIGC large language model function evaluation of China Academy of Information and Communications Technology
- This article will take you to understand the universal large language model independently developed by Tencent - the Hunyuan large model.
- Quickly build a large language model AI knowledge base in just three minutes
- Huawei's first service flagship store in South China unveiled: Intelligent robots help engineers automatically obtain parts