
Home >Technology peripherals >AI >Data modeling using Kernel Model Gaussian Processes (KMGPs)
Data modeling using Kernel Model Gaussian Processes (KMGPs)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-01-30 11:15:321259browse
Kernel Model Gaussian Processes (KMGPs) are sophisticated tools for handling the complexity of various data sets. It extends the concept of traditional Gaussian processes through kernel functions. This article will discuss in detail the theoretical basis, practical applications and challenges of KMGPs.
The kernel model Gaussian process is an extension of the traditional Gaussian process and is used in machine learning and statistics. Before understanding kmgp, you need to master the basic knowledge of Gaussian process, and then understand the role of the kernel model.
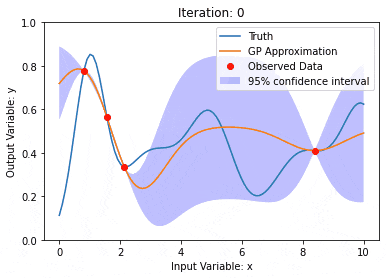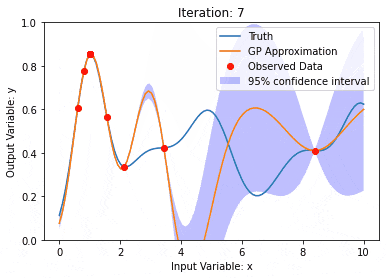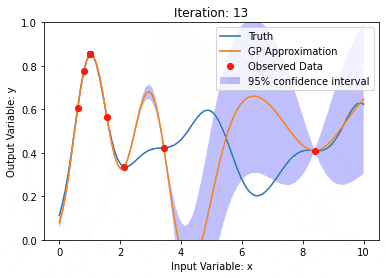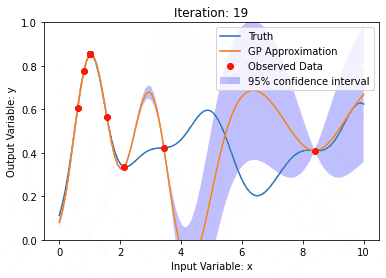
Gaussian processes (GPs)
The Gaussian process is a set of random variables, and a finite number of variables are combined with Gaussian Distribution, used to define function probability distributions.
The Gaussian process is commonly used in regression and classification tasks in machine learning and can be used to fit the probability distribution of data.
An important characteristic of Gaussian processes is the ability to provide uncertainty estimates and predictions, which is very useful in the task of understanding the confidence of the predictions is as important as the predictions themselves.
Kernel function modeling
In the Gaussian process, the kernel function (or covariance function) is used to measure the differences between different data points similarity. The kernel function takes two inputs and calculates the similarity score between them.
There are various types of kernels such as linear, polynomial, and radial basis functions (RBF). Each core has different characteristics, and the appropriate core can be selected according to the problem.
In Gaussian processes, kernel modeling is the process of selecting and optimizing kernel functions to best capture the underlying patterns in the data. This step is very important because the choice and configuration of the kernel can significantly affect the performance of the Gaussian process.
Kernel Model Gaussian Processes (KMGPs)
KMGPs is an extension of the standard GP (Gaussian process), focusing on the application of kernel functions. Compared with standard GPs, KMGPs focus more on customizing complex or custom-designed kernel functions based on specific types of data or problems. This approach is particularly useful when the data is complex and standard kernel functions fail to capture the underlying relationships. However, designing and tuning kernel functions in KMGPs is challenging and often requires deep domain knowledge and professional experience in the problem domain and statistical modeling.
The kernel model Gaussian process is a sophisticated tool in statistical learning, providing a flexible and powerful way to model complex data sets. They are particularly valued for their ability to provide uncertainty estimates and their adaptability to reconcile different types of data through custom reconciliations.
Well-designed kernels in KMGP can model complex phenomena such as nonlinear trends, periodicity, and heteroskedasticity (varying noise levels) in the data. So it requires in-depth domain knowledge and a thorough understanding of statistical modeling.
KMGP has applications in many fields. In geostatistics, they model spatial data to capture underlying geographic variation. In finance, they are used to predict stock prices, explaining the unstable and complex nature of financial markets. In robotics and control systems, KMGPs model and predict the behavior of dynamic systems under uncertainty.
Code
We use the synthetic data set to create a complete Python code example. Here we use a library GPy, which is a specialized Library for handling Gaussian processes.
pip install numpy matplotlib GPy
Import library
import numpy as np import matplotlib.pyplot as plt import GPy
We will then create a synthetic dataset using numpy.
X = np.linspace(0, 10, 100)[:, None] Y = np.sin(X) + np.random.normal(0, 0.1, X.shape)
Define and train a Gaussian process model using GPy
kernel = GPy.kern.RBF(input_dim=1, variance=1., lengthscale=1.) model = GPy.models.GPRegression(X, Y, kernel) model.optimize(messages=True)
After training the model, we will use it to make predictions on the test data set. Then plot a graph to visualize the model's performance.
X_test = np.linspace(-2, 12, 200)[:, None] Y_pred, Y_var = model.predict(X_test) plt.figure(figsize=(10, 5)) plt.plot(X_test, Y_pred, 'r-', lw=2, label='Prediction') plt.fill_between(X_test.flatten(), (Y_pred - 2*np.sqrt(Y_var)).flatten(), (Y_pred + 2*np.sqrt(Y_var)).flatten(), alpha=0.5, color='pink', label='Confidence Interval') plt.scatter(X, Y, c='b', label='Training Data') plt.xlabel('X') plt.ylabel('Y') plt.title('Kernel Modeled Gaussian Process Regression') plt.legend() plt.show()
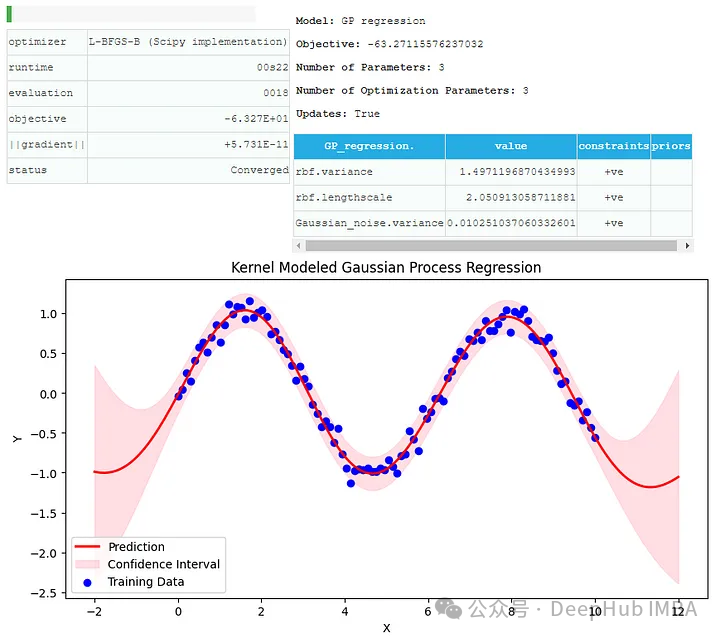
We apply the Gaussian process regression model with RBF kernel here, and you can see the prediction and training data and confidence interval.
Summary
The kernel model Gaussian process represents a major advance in the field of statistical learning, providing a flexible and powerful framework for understanding complex data sets. . GPy also contains basically all the kernel functions we can see. The following is a screenshot of the official document:
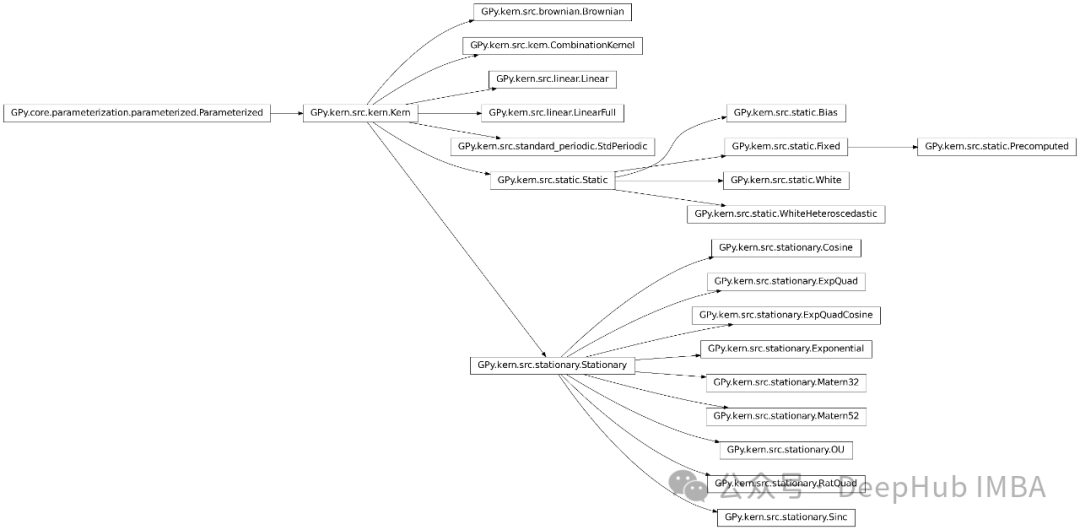
For different data You need to choose different kernel function kernel hyperparameters. Here GPy official also gives a flow chart
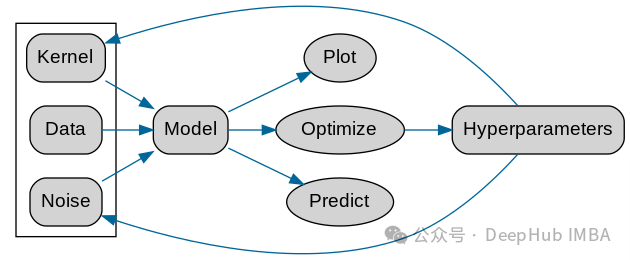
The above is the detailed content of Data modeling using Kernel Model Gaussian Processes (KMGPs). For more information, please follow other related articles on the PHP Chinese website!