


This is a simple guide on how to use reinforcement learning to train an AI to play the Snake game. The article shows step by step how to set up a custom game environment and use the python standardized Stable-Baselines3 algorithm library to train the AI to play Snake.
In this project, we are using Stable-Baselines3, a standardized library that provides easy-to-use PyTorch-based implementation of reinforcement learning (RL) algorithms.
First, set up the environment. There are many built-in game environments in the Stable-Baselines library. Here we use a modified version of the classic Snake, with additional crisscrossing walls in the middle.
A better reward plan would be to only reward steps that are closer to food. Care must be taken here, as the snake can still only learn to walk in a circle, receive a reward when approaching food, then turn around and come back. To avoid this, we must also give an equivalent penalty to staying away from food, in other words, we need to ensure that the net reward on the closed loop is zero. We also need to introduce a penalty for hitting walls, because in some cases a snake will choose to hit a wall to get closer to its food.
Most machine learning algorithms are quite complex and difficult to implement. Fortunately, Stable-Baselines3 already implements several state-of-the-art algorithms at our disposal. In the example we will use Proximal Policy Optimization (PPO). While we don't need to know the details of how the algorithm works (check out this explainer video if you're interested), we do need to have a basic understanding of what its hyperparameters are and what they do. Luckily PPO only has a few of them, we will use the following:
learning_rate: Sets how large the steps for policy updates are, the same as other machine learning scenarios. Setting it too high can prevent the algorithm from finding the correct solution or even push it in a direction from which it can never recover. Setting it too low will make training take longer. A common trick is to use a scheduler function to tune it during training.
gamma: Discount factor for future rewards, between 0 (only immediate rewards matter) and 1 (future rewards have the same value as immediate rewards). In order to maintain the training effect, it is best to keep it above 0.9.
clip_range1 -clip_range: An important feature of PPO, it exists to ensure that the model does not change significantly during training. Reducing it helps fine-tune the model in later training stages.
ent_coef: Essentially, the higher its value, the more the algorithm is encouraged to explore different non-optimal actions, which can help the scheme escape local reward maxima.
Generally speaking, just start with the default hyperparameters.
The next steps are to train for some predetermined steps, then see for yourself how the algorithm performs, and then start over with the new parameters possible that perform best. Here we plot the rewards for different training times.
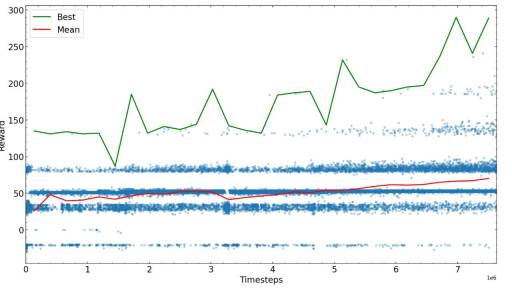
After enough steps, the snake training algorithm converges to a certain reward value, you can complete the training or try to fine-tune the parameters and continue training.
The training steps required to reach the maximum possible reward depend heavily on the problem, reward scheme, and hyperparameters, so it is recommended to optimize before training the algorithm. At the end of the example of training the AI to play the Snake game, we found that the AI was able to find food in the maze and avoid colliding with the tail.
The above is the detailed content of How to use Python to train AI to play the Snake game. For more information, please follow other related articles on the PHP Chinese website!

 Merging Lists in Python: Choosing the Right MethodMay 14, 2025 am 12:11 AM
Merging Lists in Python: Choosing the Right MethodMay 14, 2025 am 12:11 AMTomergelistsinPython,youcanusethe operator,extendmethod,listcomprehension,oritertools.chain,eachwithspecificadvantages:1)The operatorissimplebutlessefficientforlargelists;2)extendismemory-efficientbutmodifiestheoriginallist;3)listcomprehensionoffersf
 How to concatenate two lists in python 3?May 14, 2025 am 12:09 AM
How to concatenate two lists in python 3?May 14, 2025 am 12:09 AMIn Python 3, two lists can be connected through a variety of methods: 1) Use operator, which is suitable for small lists, but is inefficient for large lists; 2) Use extend method, which is suitable for large lists, with high memory efficiency, but will modify the original list; 3) Use * operator, which is suitable for merging multiple lists, without modifying the original list; 4) Use itertools.chain, which is suitable for large data sets, with high memory efficiency.
 Python concatenate list stringsMay 14, 2025 am 12:08 AM
Python concatenate list stringsMay 14, 2025 am 12:08 AMUsing the join() method is the most efficient way to connect strings from lists in Python. 1) Use the join() method to be efficient and easy to read. 2) The cycle uses operators inefficiently for large lists. 3) The combination of list comprehension and join() is suitable for scenarios that require conversion. 4) The reduce() method is suitable for other types of reductions, but is inefficient for string concatenation. The complete sentence ends.
 Python execution, what is that?May 14, 2025 am 12:06 AM
Python execution, what is that?May 14, 2025 am 12:06 AMPythonexecutionistheprocessoftransformingPythoncodeintoexecutableinstructions.1)Theinterpreterreadsthecode,convertingitintobytecode,whichthePythonVirtualMachine(PVM)executes.2)TheGlobalInterpreterLock(GIL)managesthreadexecution,potentiallylimitingmul
 Python: what are the key featuresMay 14, 2025 am 12:02 AM
Python: what are the key featuresMay 14, 2025 am 12:02 AMKey features of Python include: 1. The syntax is concise and easy to understand, suitable for beginners; 2. Dynamic type system, improving development speed; 3. Rich standard library, supporting multiple tasks; 4. Strong community and ecosystem, providing extensive support; 5. Interpretation, suitable for scripting and rapid prototyping; 6. Multi-paradigm support, suitable for various programming styles.
 Python: compiler or Interpreter?May 13, 2025 am 12:10 AM
Python: compiler or Interpreter?May 13, 2025 am 12:10 AMPython is an interpreted language, but it also includes the compilation process. 1) Python code is first compiled into bytecode. 2) Bytecode is interpreted and executed by Python virtual machine. 3) This hybrid mechanism makes Python both flexible and efficient, but not as fast as a fully compiled language.
 Python For Loop vs While Loop: When to Use Which?May 13, 2025 am 12:07 AM
Python For Loop vs While Loop: When to Use Which?May 13, 2025 am 12:07 AMUseaforloopwheniteratingoverasequenceorforaspecificnumberoftimes;useawhileloopwhencontinuinguntilaconditionismet.Forloopsareidealforknownsequences,whilewhileloopssuitsituationswithundeterminediterations.
 Python loops: The most common errorsMay 13, 2025 am 12:07 AM
Python loops: The most common errorsMay 13, 2025 am 12:07 AMPythonloopscanleadtoerrorslikeinfiniteloops,modifyinglistsduringiteration,off-by-oneerrors,zero-indexingissues,andnestedloopinefficiencies.Toavoidthese:1)Use'i


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Notepad++7.3.1
Easy-to-use and free code editor

WebStorm Mac version
Useful JavaScript development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

