Lightning Attention-2 is a new linear attention mechanism that makes the training and inference costs of long sequences consistent with those of 1K sequence length.
The limitation of the sequence length of large language models has greatly restricted its application in the field of artificial intelligence, such as multi-turn dialogue, long text understanding, Processing and generation of multimodal data, etc. The fundamental reason for this limitation is that the Transformer architecture used in current large language models has quadratic computational complexity relative to the sequence length. This means that as the sequence length increases, the required computing resources increase exponentially. How to efficiently process long sequences has always been one of the challenges of large language models. Previous methods often focused on how to adapt large language models to longer sequences during the inference stage. For example, Alibi or similar relative position coding methods can be used to allow the model to adapt to different input sequence lengths, or similar relative position coding methods such as RoPE can be used to perform differences, and further training can be performed on the model that has completed training. Short-term fine-tuning is performed to achieve the purpose of amplifying the sequence length. These methods only allow large models to have certain long sequence modeling capabilities, but the actual training and inference overhead has not been reduced. #The OpenNLPLab team tries to solve the long sequence problem of large language models once and for all. They proposed and open sourced Lightning Attention-2, a new linear attention mechanism that makes the training and inference costs of long sequences consistent with those of 1K sequence length. Before encountering a memory bottleneck, increasing the sequence length indefinitely will not have a negative impact on the model training speed. This makes pre-training of unlimited length possible. At the same time, the inference cost of very long text is also consistent with or even less than the cost of 1K Tokens, which will greatly reduce the inference cost of current large language models. As shown in the figure below, under the model sizes of 400M, 1B, and 3B, as the sequence length increases, the training speed of LLaMA supported by FlashAttention2 begins to decrease rapidly, but the speed of TansNormerLLM supported by Lightning Attention-2 has almost no change.  figure 1
figure 1
- Paper: Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
- ##Paper address: https://arxiv.org /pdf/2401.04658.pdf
- Open source address: https://github.com/OpenNLPLab/lightning-attention
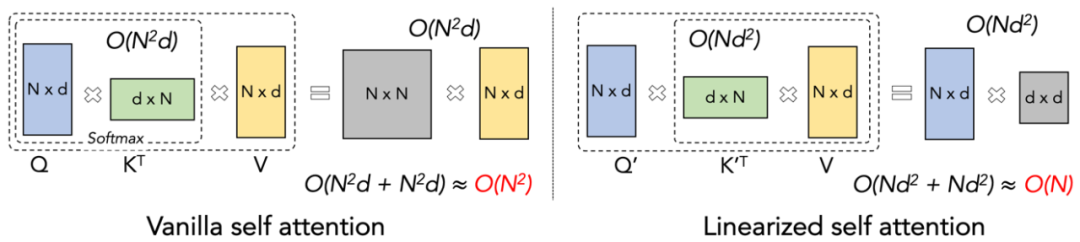
Lightning Attention-2 Introduction Keep the pre-training speed of large models consistent across different sequence lengths, which is what it sounds like An impossible mission. In fact, this can be achieved if the computational complexity of an attention mechanism remains linear with respect to sequence length. Since the emergence of linear attention [https://arxiv.org/abs/2006.16236] in 2020, researchers have been working hard to make the actual efficiency of linear attention consistent with its theoretical linear computational complexity. Prior to 2023, most work on linear attention focused on aligning their accuracy with Transformers. Finally in mid-2023, the improved linear attention mechanism [https://arxiv.org/abs/2307.14995] can be aligned with the state-of-the-art Transformer architecture in accuracy. However, the most critical "left multiplication to right multiplication" calculation trick (shown in the figure below) that changes the computational complexity to linear in linear attention (as shown in the figure below) is much slower than the direct left multiplication algorithm in actual implementation. The reason is that the implementation of right multiplication requires the use of cumulative summation (cumsum) containing a large number of loop operations. The large number of IO operations makes the efficiency of right multiplication much lower than that of left multiplication.
To better understand Lightning With the idea of Attention-2, let us first review the calculation formula of traditional softmax attention: O=softmax ((QK^T)⊙M_) V, where Q, K, V, M, and O are query, key, value, respectively. mask and output matrix, M here is a lower triangular all-1 matrix in one-way tasks (such as GPT), but can be ignored in two-way tasks (such as Bert), that is, there is no mask matrix for two-way tasks.
The author summarizes the overall idea of Lightning Attention-2 into the following three points for explanation:
1. Linear One of the core ideas of Attention is to remove the computationally expensive softmax operator, so that the calculation formula of Attention can be written as O=((QK^T)⊙M_) V. However, due to the existence of the mask matrix M in the one-way task, this form can still only perform left multiplication calculations, so the complexity of O (N) cannot be obtained. But for bidirectional tasks, since there is no mask matrix, the calculation formula of Linear Attention can be further simplified to O=(QK^T) V. The subtlety of Linear Attention is that by simply using the associative law of matrix multiplication, its calculation formula can be further transformed into: O=Q (K^T V). This calculation form is called right multiplication, and the corresponding former is Take the left. From Figure 2, we can intuitively understand that Linear Attention can achieve an attractive O (N) complexity in bidirectional tasks!
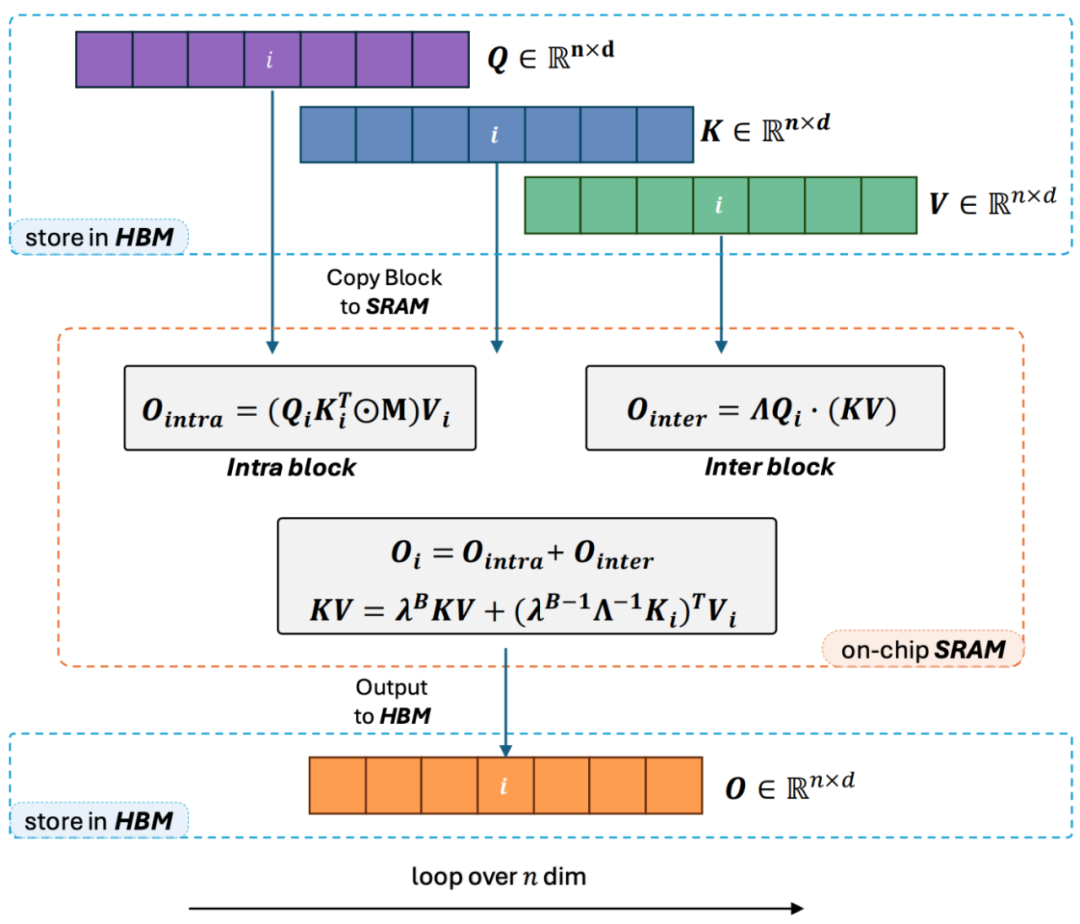
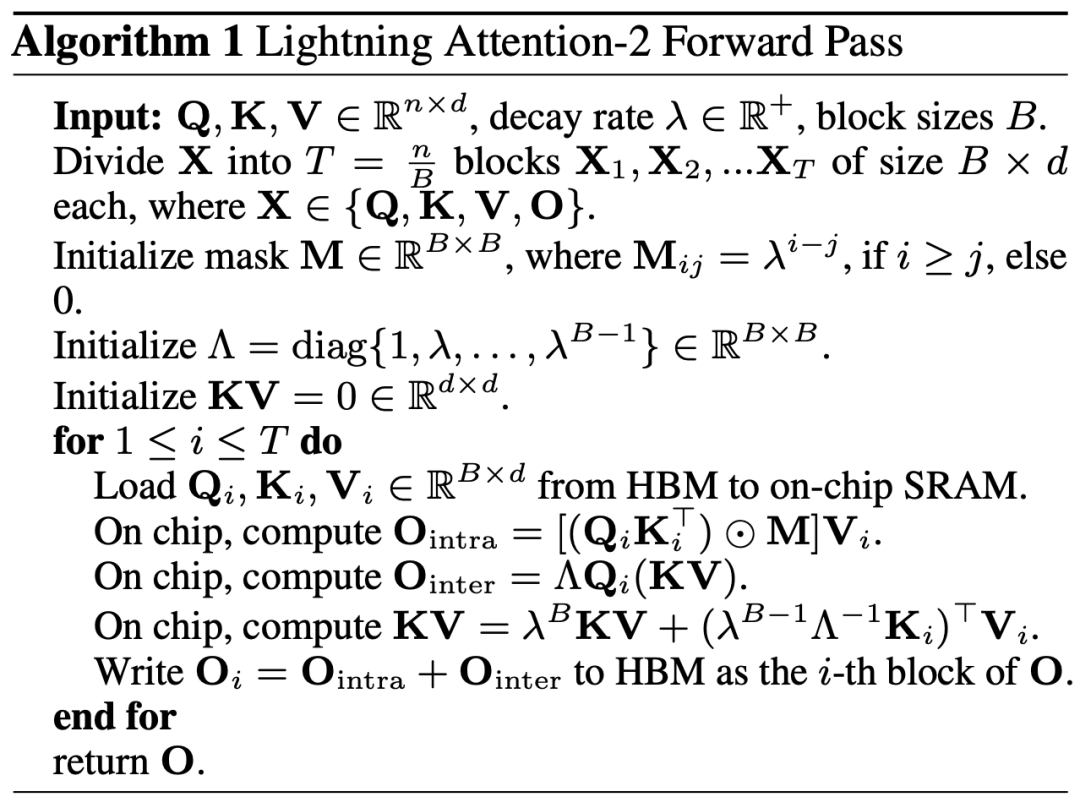
2. However, as the decoder-only GPT model gradually becomes the de facto standard of LLM, how to use the right multiplication feature of Linear Attention to accelerate one-way tasks has become an urgent need. Solved puzzle. In order to solve this problem, the author of this article proposed to use the idea of "divide and conquer" to divide the calculation of the attention matrix into two forms: diagonal matrix and non-diagonal matrix, and use different ways to calculate them. As shown in Figure 3, Linear Attention-2 uses the Tiling idea commonly used in the computer field to divide the Q, K, and V matrices into the same number of blocks. Among them, the calculation of the block itself (intra-block) still retains the left multiplication calculation method due to the existence of the mask matrix, with a complexity of O (N^2); while the calculation of the block (inter-block) does not have the mask matrix. With the existence of , you can use the right multiplication calculation method to enjoy the complexity of O (N). After the two are calculated separately, they can be directly added to obtain the Linear Attention output Oi corresponding to the i-th block. At the same time, the state of KV is accumulated through cumsum for use in the calculation of the next block. In this way, the algorithm complexity of the entire Lightning Attention-2 is O (N^2) for intra-block and O (N) for inter-block Trade-off. How to obtain better trade-off is determined by Tiling's block size.
3. Careful readers will find that the above process is only the algorithm part of Lightning Attention-2. The reason why it is named Lightning is that the author fully considered the algorithm process in Efficiency issues in GPU hardware execution. Inspired by the FlashAttention series of work, when actually performing calculations on the GPU, the author moved the split Q_i, K_i, V_i tensors from the slower HBM with larger capacity inside the GPU to the faster SRAM with smaller capacity. Computation is performed on the system, thereby reducing a large amount of memory IO overhead.After the block completes the calculation of Linear Attention, its output result O_i will be moved back to HBM. Repeat this process until all blocks have been processed.
Readers who want to know more details can carefully read Algorithm 1 and Algorithm 2 in this article, as well as the detailed derivation process in the paper. Both the Algorithm and the derivation process distinguish between the forward and reverse processes of Lightning Attention-2, which can help readers have a deeper understanding.
image 3
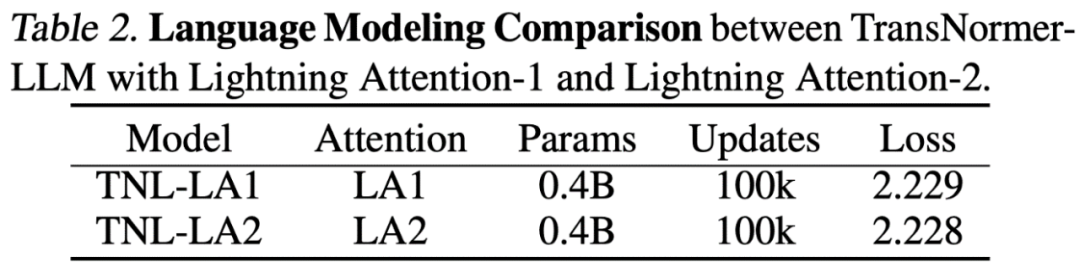
Lightning Attention-2 Accuracy ComparisonThe researchers first compared the accuracy difference between Lightning Attention-2 and Lightning Attention-1 on a small-scale (400M) parameter model , as shown in the figure below, there is almost no difference between the two.
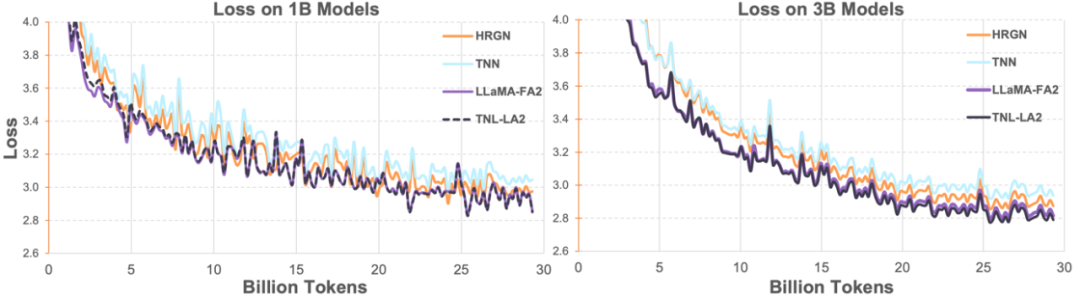
The researchers then combined TransNormerLLM (TNL-LA2) supported by Lightning Attention-2 with other advanced non-Transformer architecture networks and LLaMA supported by FlashAttention2 on 1B and 3B. Comparisons were made under the same corpus. As shown in the figure below, TNL-LA2 and LLaMA maintain a similar trend, and the loss performance is better. This experiment shows that Lightning Attention-2 has an accuracy performance that is not inferior to the state-of-the-art Transformer architecture in language modeling.
In the large language model task, the researchers compared the results of TNL-LA2 15B and Pythia on common benchmarks for large models of similar size. As shown in the table below, under the condition of eating the same tokens, TNL-LA2 is slightly higher than the Pythia model based on Softmax attention in common sense reasoning and multiple choice comprehensive capabilities.
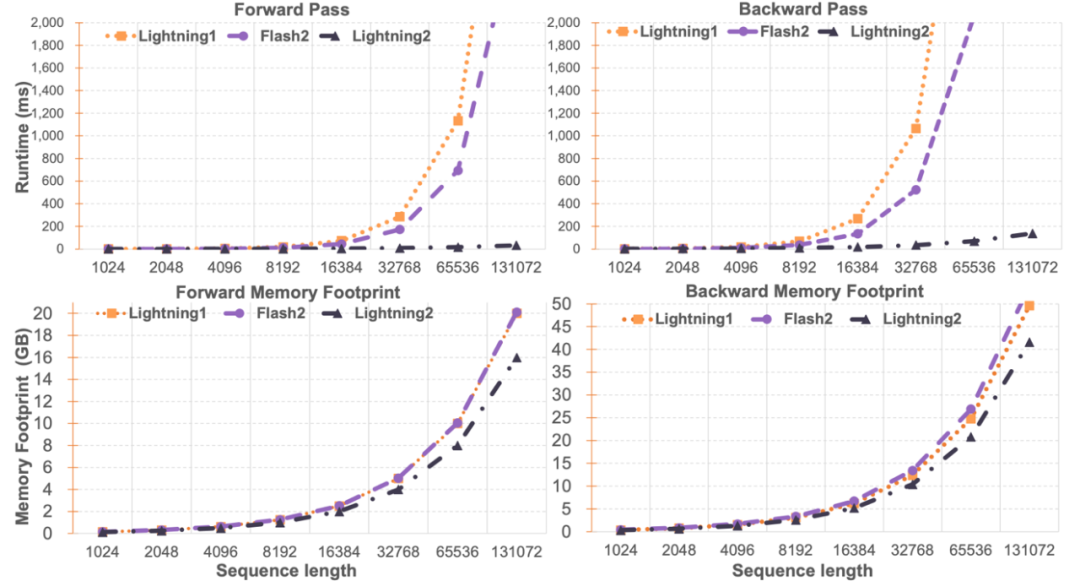
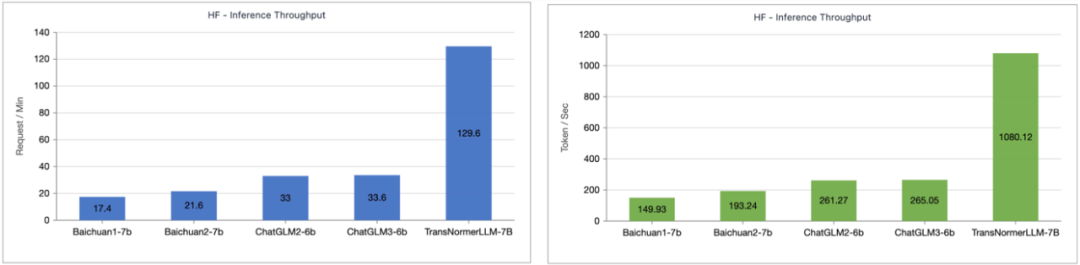
Lightning Attention-2 Speed ComparisonResearchers compare Lightning Attention-2 and FlashAttention2 compared single module speed and memory usage. As shown in the figure below, compared to Lightning Attention-1 and FlashAttention2, Lightning Attention-2 shows a strict linear increase in speed compared to the sequence length. In terms of memory usage, all three show similar trends, but Lightning Attention-2 has a smaller memory footprint. The reason for this is that the memory usage of FlashAttention2 and Lightning Attention-1 is also approximately linear. The author noticed that the main focus of this article is on solving the training speed of linear attention network, and achieving the training of long sequences of any length similar to 1K sequences speed. In terms of inference speed, there is not much introduction. This is because linear attention can be losslessly converted to RNN mode during reasoning, thereby achieving a similar effect, that is, the speed of reasoning for a single token is constant. For Transformer, the inference speed of the current token is related to the number of tokens before it. The author tested the comparison of the inference speed between TransNormerLLM-7B supported by Lightning Attention-1 and the common 7B model. As shown in the figure below, under the approximate parameter size, the throughput speed of Lightning Attention-1 is 4 times that of Baichuan and more than 3.5 times that of ChatGLM, showing an excellent inference speed advantage.
Lightning Attention-2 represents a major advancement in linear attention mechanisms, making it perfect in both accuracy and speed The replacement of traditional Softmax attention provides sustainable scalability for larger and larger models in the future, and provides a way to process infinitely long sequences with higher efficiency. The OpenNLPLab team will study sequential parallel algorithms based on linear attention mechanisms in the future to solve the currently encountered memory barrier problem. The above is the detailed content of Lightning Attention-2: A new generation of attention mechanism that achieves infinite sequence length, constant computing power cost and higher modeling accuracy. For more information, please follow other related articles on the PHP Chinese website!


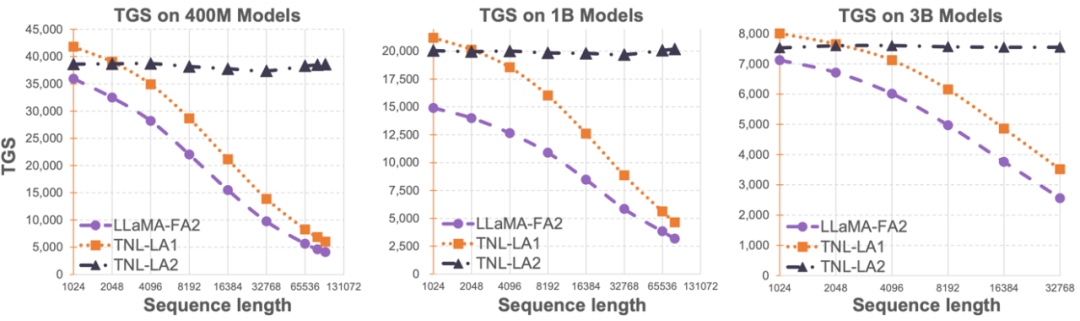 figure 1
figure 1