

 Technology peripheralsAIIntroducing a large domestic open source MoE model, its performance is comparable to Llama 2-7B, while the calculation amount is reduced by 60%
Technology peripheralsAIIntroducing a large domestic open source MoE model, its performance is comparable to Llama 2-7B, while the calculation amount is reduced by 60%Introducing a large domestic open source MoE model, its performance is comparable to Llama 2-7B, while the calculation amount is reduced by 60%

The open source MoE model finally welcomes its first domestic player!
Its performance is not inferior to the dense Llama 2-7B model, but the calculation amount is only 40%.
This model can be called a 19-sided warrior, especially in terms of math and coding capabilities, crushing Llama.
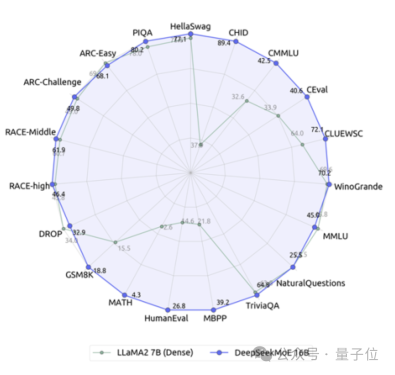
It is the Deep Search team’s latest open source 16 billion parameter expert model DeepSeek MoE.
In addition to its excellent performance, DeepSeek MoE's main focus is to save computing power.
In this performance-activation parameter diagram, it "singles out" and occupies a large blank area in the upper left corner.

Only one day after its release, the DeepSeek team’s tweet on X received a large number of retweets and attention.
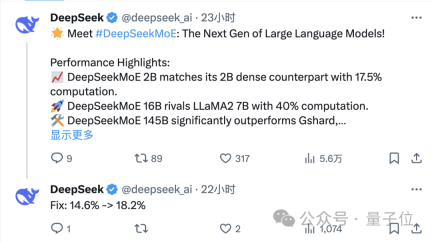
Maxime Labonne, a machine learning engineer at JP Morgan, also said after testing that the chat version of DeepSeek MoE performs slightly better than Microsoft's "small model" Phi-2.
At the same time, DeepSeek MoE also received 300 stars on GitHub and appeared on the homepage of the Hugging Face text generation model rankings.
So, what is the specific performance of DeepSeek MoE?
The amount of calculation is reduced by 60%
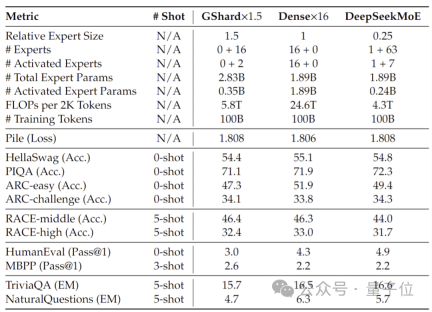
The current version of DeepSeek MoE has 16 billion parameters, and the actual number of activated parameters is about 2.8 billion.
Compared with its own 7B dense model, the performance of the two on the 19 data sets has different advantages and disadvantages, but the overall performance is relatively close.
Compared with Llama 2-7B, which is also a dense model, DeepSeek MoE also shows obvious advantages in mathematics, code, etc.
But the calculation amount of both dense models exceeds 180TFLOPs per 4k tokens, while DeepSeek MoE only has 74.4TFLOPs, which is only 40% of the two.

Performance tests conducted at 2 billion parameters show that DeepSeek MoE can also achieve the performance of the same MoE model with 1.5 times the number of parameters with less calculation. GShard 2.8B has comparable or even better results.
In addition, the Deep Seek team also fine-tuned the Chat version of DeepSeek MoE based on SFT, and its performance was also close to its own intensive version and Llama 2-7B.
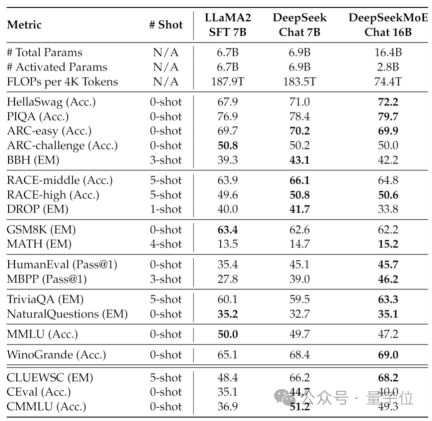
In addition, the DeepSeek team also revealed that a 145B version of the DeepSeek MoE model is under development.
Phased preliminary tests show that the 145B DeepSeek MoE has a huge lead over the GShard 137B, and can achieve equivalent performance to the dense version of the DeepSeek 67B model with 28.5% of the calculation amount.
After the research and development is completed, the team will also open source the 145B version.
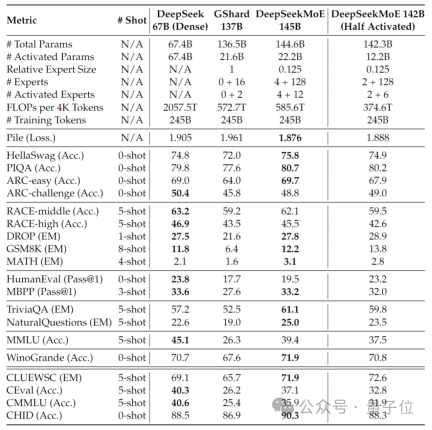
Behind the performance of these models is DeepSeek’s new self-developed MoE architecture.
Self-developed MoE new architecture
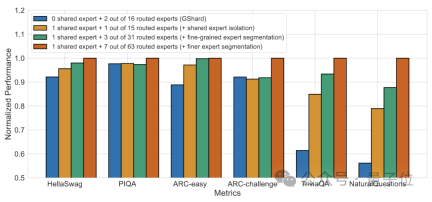
First of all, compared to the traditional MoE architecture, DeepSeek has a more fine-grained expert division.
When the total number of parameters is fixed, the traditional model can classify N experts, while DeepSeek may classify 2N experts.
At the same time, the number of experts selected each time a task is performed is twice that of the traditional model, so the overall number of parameters used remains the same, but the degree of freedom of selection increases.
This segmentation strategy allows for a more flexible and adaptive combination of activation experts, thereby improving the accuracy of the model on different tasks and the pertinence of knowledge acquisition.

In addition to the differences in expert division, DeepSeek also innovatively introduces the "shared expert" setting.
These shared experts activate tokens for all inputs and are not affected by the routing module. The purpose is to capture and integrate common knowledge that is needed in different contexts.
By compressing these shared knowledge into shared experts, parameter redundancy among other experts can be reduced, thereby improving the parameter efficiency of the model.
The setting of shared experts helps other experts focus more on their unique knowledge areas, thereby improving the overall level of expert specialization.
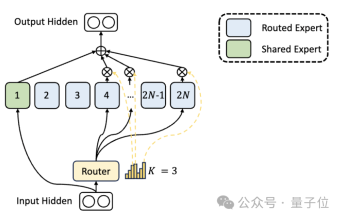
#Ablation experiment results show that both solutions play an important role in the "cost reduction and efficiency increase" of DeepSeek MoE.
Paper address: https://arxiv.org/abs/2401.06066.
Reference link: https://mp.weixin.qq.com/s/T9-EGxYuHcGQgXArLXGbgg.
The above is the detailed content of Introducing a large domestic open source MoE model, its performance is comparable to Llama 2-7B, while the calculation amount is reduced by 60%. For more information, please follow other related articles on the PHP Chinese website!

 AI Therapists Are Here: 14 Groundbreaking Mental Health Tools You Need To KnowApr 30, 2025 am 11:17 AM
AI Therapists Are Here: 14 Groundbreaking Mental Health Tools You Need To KnowApr 30, 2025 am 11:17 AMWhile it can’t provide the human connection and intuition of a trained therapist, research has shown that many people are comfortable sharing their worries and concerns with relatively faceless and anonymous AI bots. Whether this is always a good i
 Calling AI To The Grocery AisleApr 30, 2025 am 11:16 AM
Calling AI To The Grocery AisleApr 30, 2025 am 11:16 AMArtificial intelligence (AI), a technology decades in the making, is revolutionizing the food retail industry. From large-scale efficiency gains and cost reductions to streamlined processes across various business functions, AI's impact is undeniabl
 Getting Pep Talks From Generative AI To Lift Your SpiritApr 30, 2025 am 11:15 AM
Getting Pep Talks From Generative AI To Lift Your SpiritApr 30, 2025 am 11:15 AMLet’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI including identifying and explaining various impactful AI complexities (see the link here). In addition, for my comp
 Why AI-Powered Hyper-Personalization Is A Must For All BusinessesApr 30, 2025 am 11:14 AM
Why AI-Powered Hyper-Personalization Is A Must For All BusinessesApr 30, 2025 am 11:14 AMMaintaining a professional image requires occasional wardrobe updates. While online shopping is convenient, it lacks the certainty of in-person try-ons. My solution? AI-powered personalization. I envision an AI assistant curating clothing selecti
 Forget Duolingo: Google Translate's New AI Feature Teaches LanguagesApr 30, 2025 am 11:13 AM
Forget Duolingo: Google Translate's New AI Feature Teaches LanguagesApr 30, 2025 am 11:13 AMGoogle Translate adds language learning function According to Android Authority, app expert AssembleDebug has found that the latest version of the Google Translate app contains a new "practice" mode of testing code designed to help users improve their language skills through personalized activities. This feature is currently invisible to users, but AssembleDebug is able to partially activate it and view some of its new user interface elements. When activated, the feature adds a new Graduation Cap icon at the bottom of the screen marked with a "Beta" badge indicating that the "Practice" feature will be released initially in experimental form. The related pop-up prompt shows "Practice the activities tailored for you!", which means Google will generate customized
 They're Making TCP/IP For AI, And It's Called NANDAApr 30, 2025 am 11:12 AM
They're Making TCP/IP For AI, And It's Called NANDAApr 30, 2025 am 11:12 AMMIT researchers are developing NANDA, a groundbreaking web protocol designed for AI agents. Short for Networked Agents and Decentralized AI, NANDA builds upon Anthropic's Model Context Protocol (MCP) by adding internet capabilities, enabling AI agen
 The Prompt: Deepfake Detection Is A Booming BusinessApr 30, 2025 am 11:11 AM
The Prompt: Deepfake Detection Is A Booming BusinessApr 30, 2025 am 11:11 AMMeta's Latest Venture: An AI App to Rival ChatGPT Meta, the parent company of Facebook, Instagram, WhatsApp, and Threads, is launching a new AI-powered application. This standalone app, Meta AI, aims to compete directly with OpenAI's ChatGPT. Lever
 The Next Two Years In AI Cybersecurity For Business LeadersApr 30, 2025 am 11:10 AM
The Next Two Years In AI Cybersecurity For Business LeadersApr 30, 2025 am 11:10 AMNavigating the Rising Tide of AI Cyber Attacks Recently, Jason Clinton, CISO for Anthropic, underscored the emerging risks tied to non-human identities—as machine-to-machine communication proliferates, safeguarding these "identities" become


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

