
Home >Technology peripherals >AI >The University of Science and Technology of China develops the 'State Sequence Frequency Domain Prediction' method, which improves performance by 20% and maximizes sample efficiency.
The University of Science and Technology of China develops the 'State Sequence Frequency Domain Prediction' method, which improves performance by 20% and maximizes sample efficiency.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-01-15 21:21:17893browse
The training process of reinforcement learning algorithm (Reinforcement Learning, RL) usually requires a large amount of sample data interacting with the environment to support it. However, in the real world, it is often very expensive to collect a large number of interaction samples, or the safety of the sampling process cannot be ensured, such as UAV air combat training and autonomous driving training. This problem limits the scope of reinforcement learning in many practical applications. Therefore, researchers have been working hard to explore how to strike a balance between sample efficiency and safety to solve this problem. One possible solution is to use simulators or virtual environments to generate large amounts of sample data, thus avoiding the cost and security risks of real-world situations. In addition, in order to improve the sample efficiency of reinforcement learning algorithms during the training process, some researchers have used representation learning technology to design auxiliary tasks for predicting future state signals. In this way, the algorithm can extract and encode features relevant to future decisions from the original environmental state. The purpose of this approach is to improve the performance of reinforcement learning algorithms by learning more information about the environment and providing a better basis for decision-making. In this way, the algorithm can use sample data more efficiently during the training process, accelerate the learning process, and improve the accuracy and efficiency of decision-making.
Based on this idea, this work designed an auxiliary task to predict the state sequence frequency domain distribution
for multiple steps in the future to capture longer-term future decision-making characteristics. , thereby improving the sample efficiency of the algorithm.This work is titled State Sequences Prediction via Fourier Transform for Representation Learning, published in NeurIPS 2023, and accepted as Spotlight.
Author list: Ye Mingxuan, Kuang Yufei, Wang Jie*, Yang Rui, Zhou Wengang, Li Houqiang, Wu Feng
Paper link: https://openreview.net/forum?id=MvoMDD6emT
Code link: https://github.com/MIRALab-USTC/RL-SPF /
Research background and motivation
Deep reinforcement learning algorithm is used in robot control [1], game intelligence [2], and combinatorial optimization [3 ] and other fields have achieved great success. However, the current reinforcement learning algorithm still suffers from the problem of "low sample efficiency", that is, the robot needs a large amount of data interacting with the environment to train a strategy with excellent performance.
In order to improve sample efficiency, researchers have begun to pay attention to representation learning, hoping that the representations obtained through training can extract rich and useful feature information from the original state of the environment, thereby improving the performance of robots. Exploration efficiency in state space.
Reinforcement learning algorithm framework based on representation learning
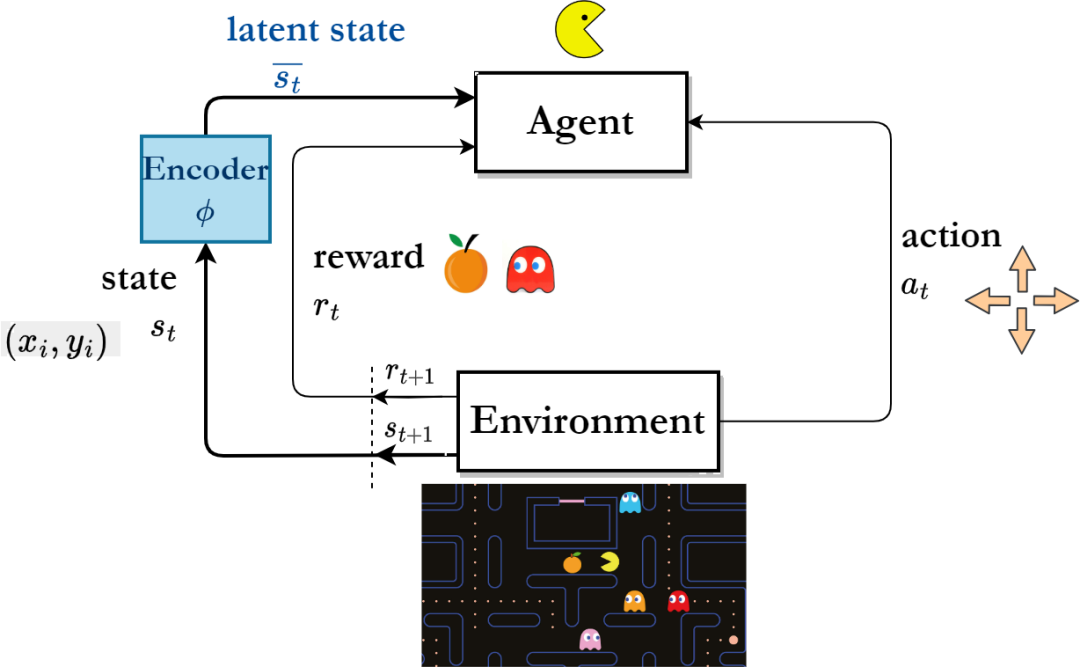
"Long-term sequence signal"Contains more future information that is beneficial to long-term decision-making than single-step signals. Inspired by this point of view, some researchers have proposed to assist representation learning by predicting multi-step state sequence signals in the future [4,5]. However, it is very difficult to directly predict the state sequence to assist representation learning.
Among the two existing methods, one method gradually generates the future state of a single moment by learning the single-step probability transfer model to indirectly predict multiple Step status sequence [6,7]. However, this type of method requires high accuracy of the trained probability transfer model, because the prediction error at each step will accumulate as the length of the prediction sequence increases.
Another type of method assists representation learning [8] by directly predicting the state sequence of multiple steps in the future, but this type of method needs to store the true state of multiple steps Sequences, as labels for prediction tasks, consume a large amount of storage. Therefore, how to effectively extract future information that is beneficial to long-term decision-making from the state sequence of the environment and thereby improve the sample efficiency during continuous control robot training is a problem that needs to be solved.
In order to solve the above problems, we propose a representation learning method based on frequency domain prediction of state sequences (State Sequences P
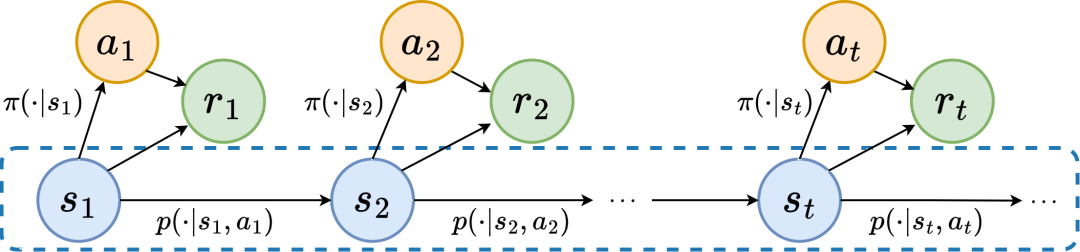
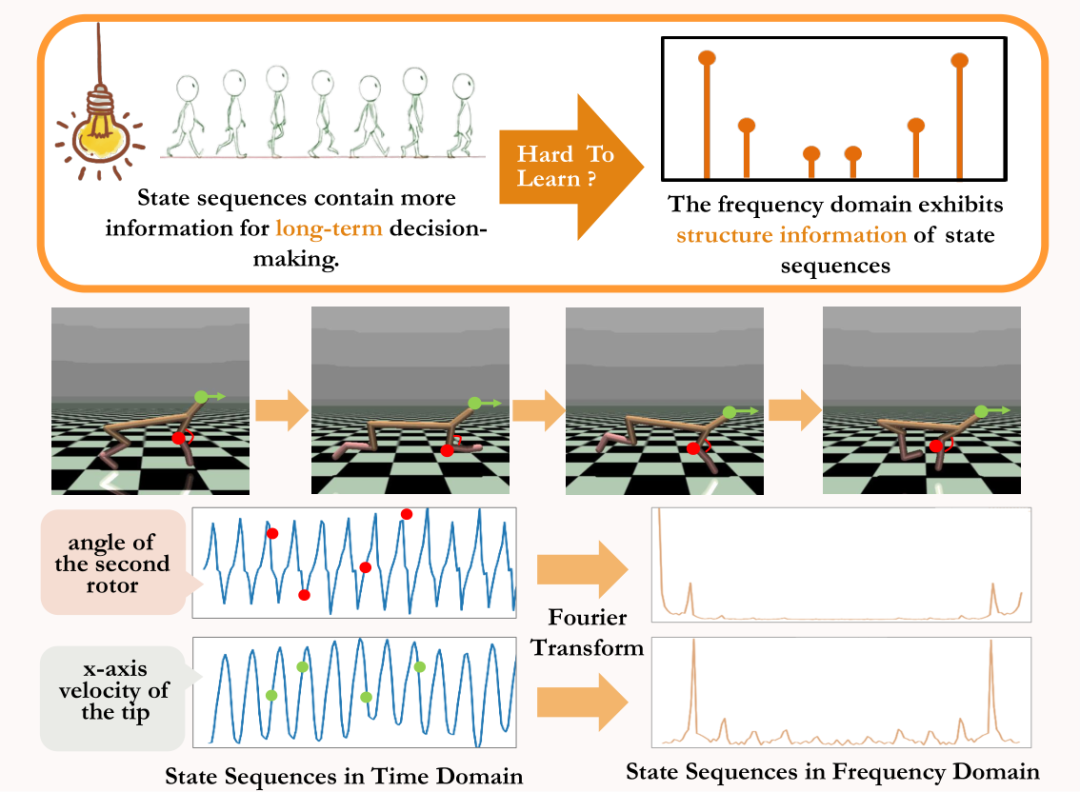
rediction viaFourier Transform, SPF), the idea is to use "frequency domain distribution of state sequence" to explicitly extract trends and patterns in state sequence data information, thereby assisting representation to efficiently extract long-term future information. We have theoretically proven that there are "two kinds of structural information" in state sequence, one One is the trend information related to strategy performance, and the other is the regular information related to state periodicity. Before analyzing the two structural information in detail, we first introduce the Markov decision that generates the state sequence. Related definitions of processes (Markov Decision Processes, MDP). We consider the classic Markov decision process in a continuous control problem, which can be represented by a five-tuple. Among them, is the corresponding state and action space, is the reward function, is the state transition function of the environment, is the initial distribution of the state, and is the discount factor. In addition, we use to represent the action distribution of the policy in the state . We record the state of the agent at time as , and the selected action as . After the agent makes an action, the environment moves to the next state and is fed back to the intelligence Body rewards. We record the trajectory corresponding to the state and action obtained during the interaction between the agent and the environment as , and the trajectory obeys the distribution . The goal of the reinforcement learning algorithm is to maximize the expected cumulative return in the future. We use to represent the average cumulative return under the current strategy and environment model , and abbreviate as , which is defined as follows: Shows the performance of the current strategy. Now we introduce the "first structural characteristic" of the state sequence, which involves The dependence between the state sequence and the corresponding reward sequence can show the performance trend of the current strategy. In reinforcement learning tasks, the future state sequence largely determines the action sequence taken by the agent in the future, and further determines the corresponding reward sequence. Therefore, the future state sequence not only contains information about the probability transition function inherent in the environment, but can also assist in capturing the trend of the current strategy. Inspired by the above structure, we prove the following theorem to further prove the existence of this structural dependency: Theorem 1: If the reward function is only related to the state, then for any two strategies and , their performance difference can be controlled by the difference in the state sequence distribution generated by these two strategies: In the above formula, represents the probability distribution of the state sequence under the specified policy and transition probability function, and represents the norm. The above theorem shows that the greater the performance difference between the two strategies, the greater the distribution difference between the two corresponding state sequences. This means that a good strategy and a bad strategy will produce two quite different state sequences, which further illustrates that the long-term structural information contained in the state sequence can potentially affect the efficiency of the search strategy with excellent performance. On the other hand, under certain conditions, the difference in frequency domain distribution of state sequences can also provide an upper bound for the corresponding policy performance difference, as shown in the following theorem: Theorem 2: If the state space is finite-dimensional and the reward function is an n-degree polynomial related to the state, then for any two strategies and , their performance difference can be expressed by Controlled by the difference in frequency domain distribution of the state sequences generated by the two strategies: In the above formula, represents the Fourier function of the power sequence of the state sequence generated by the strategy, Represents the component of the Fourier function. This theorem shows that the frequency domain distribution of the state sequence still contains features related to the performance of the current strategy. Now we introduce the "second structural characteristic" that exists in the state sequence, It involves the time dependence between state signals, that is, the regular pattern displayed by the state sequence over a long period of time. In many real-scenario tasks, agents will also show periodic behavior because the state transition function of their environment itself is periodic. Take an industrial assembly robot as an example. The robot is trained to assemble parts together to create a final product. When the strategy training reaches stability, it performs a periodic action sequence that enables it to efficiently assemble parts in Together. Inspired by the above example, we provide some theoretical analysis to prove that in the finite state space, when the transition probability matrix satisfies certain assumptions, the corresponding state sequence reaches stability in the agent. The strategy may show "asymptotic periodicity". The specific theorem is as follows: ##Theorem 3: For a finite state transition matrix of Dimensional state space , assuming that there are cycle classes, the corresponding state transition submatrix is . Assume that the number of eigenvalues with modulus 1 of this matrix is , then for the initial distribution of any state , the state distribution shows asymptotic periodicity with period . In the MuJoCo task, when the strategy training reaches stability, the agent will also show periodic movements. The figure below gives an example of the state sequence of the HalfCheetah agent in the MuJoCo task over a period of time, and obvious periodicity can be observed. (For more examples of periodic state sequences in the MuJoCo task, please refer to Section E in the appendix of this paper) HalfCheetah agent in the MuJoCo task The periodicity shown by the state within a period of time The information presented by the time series in the time domain is relatively scattered, but in the frequency domain, the regular information in the sequence is more concentrated. form presentation. By analyzing the frequency components in the frequency domain, we can explicitly capture the periodic characteristics present in the state sequence. In the previous part, we theoretically proved that the frequency domain distribution of the state sequence can reflect the performance of the strategy, and By analyzing the frequency components in the frequency domain we can explicitly capture the periodic features in the state sequence. Inspired by the above analysis, we designed the auxiliary task of "Predicting the Fourier transform of the infinite-step future state sequence" to encourage the representation of the structure in the extracted state sequence sexual information. The following introduces our modeling of this auxiliary task. Given the current state and action, we define the expected future state sequence as follows: Our auxiliary task trains the representation to predict the expected state sequence above Discrete-time Fourier transform (DTFT), that is, The above Fourier transform formula can be rewritten as the following recursion Format:
Inspired by the TD-error loss function [9] that optimizes Q-value networks in Q-learning, we designed the following loss function:
Among them, and are the neural network parameters of the representation encoder (encoder) and Fourier function predictor (predictor) respectively for which the loss function needs to be optimized, and are the experience pool for storing sample data. Further, we can prove that the above recursive formula can be expressed as a compression map: Theorem 4: Let represent the function family , and define the norm on as: ##where represents the row vector of the matrix . If we define the mapping as , we can prove that it is a compression mapping. According to the principle of compression mapping, we can use operators iteratively to approximate the frequency domain distribution of the real state sequence, and have convergence guarantee in tabular setting. In addition, the loss function we designed only depends on the state of the current moment and the next moment, so there is no need to store the state data of multiple steps in the future as prediction labels, which has The advantages of simple implementation and low storage capacity.
Algorithm framework diagram of the representation learning method (SPF) based on state sequence frequency domain prediction We optimize and update the representation encoder and Fourier function predictor by minimizing the loss function, so that the output of the predictor can approximate the Fourier transform of the real state sequence, thus encouraging The representation encoder extracts features that contain structural information about future long-term state sequences. We input the original state and action into the representation encoder, use the obtained features as input to the actor network and critic network in the reinforcement learning algorithm, and optimize the actor network with the classic reinforcement learning algorithm and critic network. Experimental results (Note: This section only selects part of the experimental results. For more detailed results, please refer to Section 6 and the appendix of the original paper. .) Algorithm performance comparison
The above figure shows the performance curves of our proposed SPF method (red line and orange line) and other comparison methods in 6 MuJoCo tasks. The results show that our proposed method can achieve a performance improvement of 19.5% compared to other methods. We conducted an ablation experiment on each module of the SPF method, comparing this method with the one that does not use the projector module (noproj) , compare the performance when not using the target network module (notarg), changing the prediction loss (nofreqloss), and changing the feature encoder network structure (mlp, mlp_cat). Ablation experimental result diagram of the SPF method applied to the SAC algorithm, tested on the HalfCheetah task We use the SPF methodThe trained predictoroutputs the Fourier function of the state sequence, and passes the inverse Fourier transformCompare the restored 200-step status sequence with the real 200-step status sequence. The results show that even if a longer state is used as input, the recovered state sequence is very similar to the real state sequence, which shows that the representation learned by the SPF method can be effectively encoded Structural information contained in the state sequence. Analysis of structural information in state sequence
Markov Decision Process
Trend information
Regular information
Method introduction
SPF method loss function
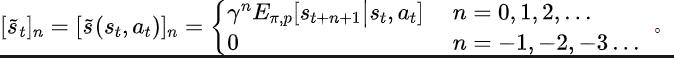
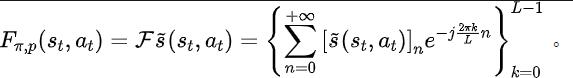
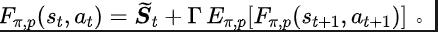
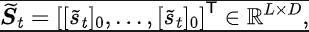
 ## Among them, is the dimension of the state space, and is the number of discretization points of the predicted state sequence Fourier function.
## Among them, is the dimension of the state space, and is the number of discretization points of the predicted state sequence Fourier function. 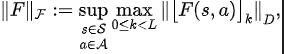
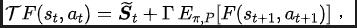
Now we introduce the algorithm framework of this paper’s method (SPF).
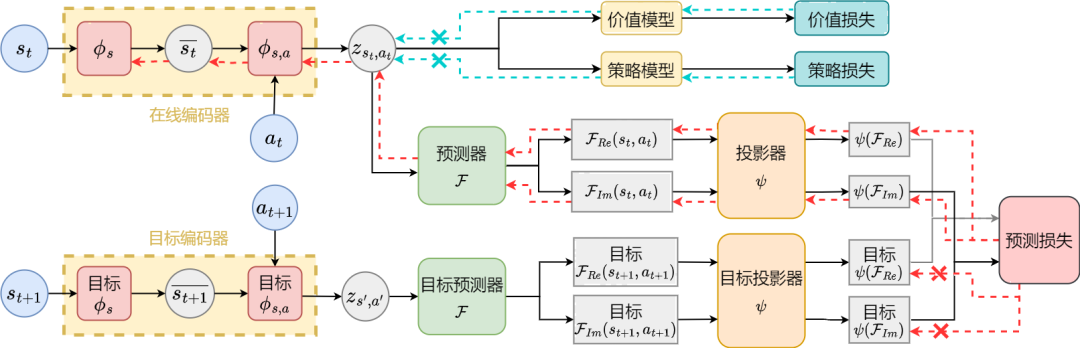
We tested the SPF method on the MuJoCo simulation robot control environment and compared the following 6 methods:
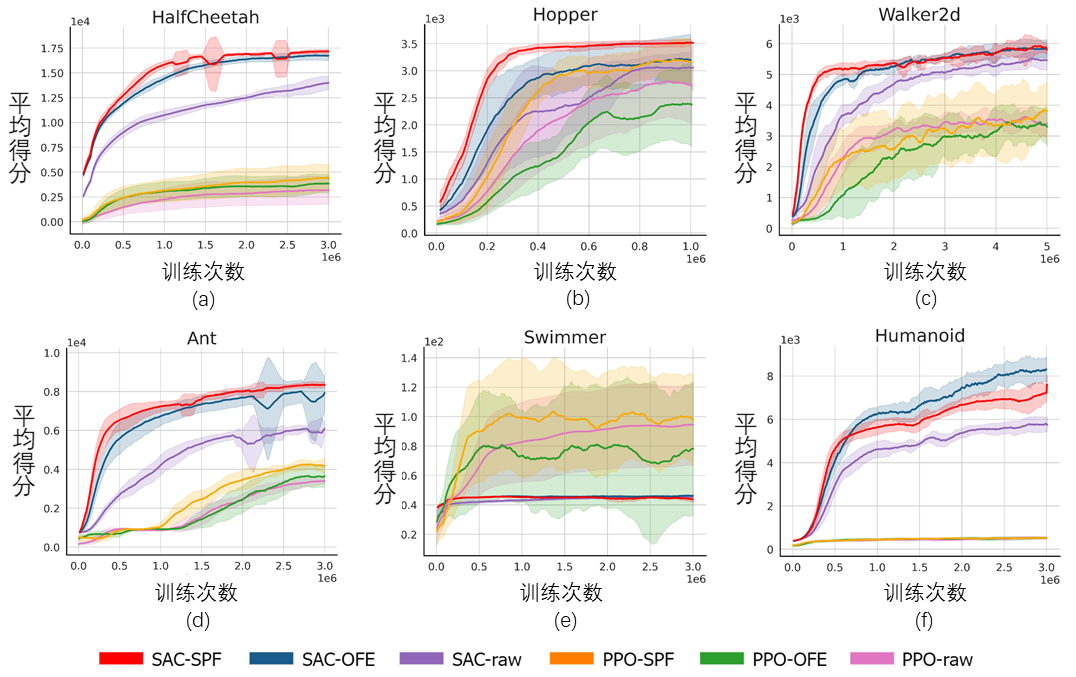
Ablation experiment
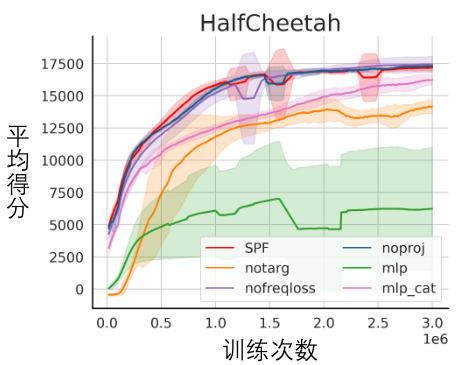
Visualization Experiment
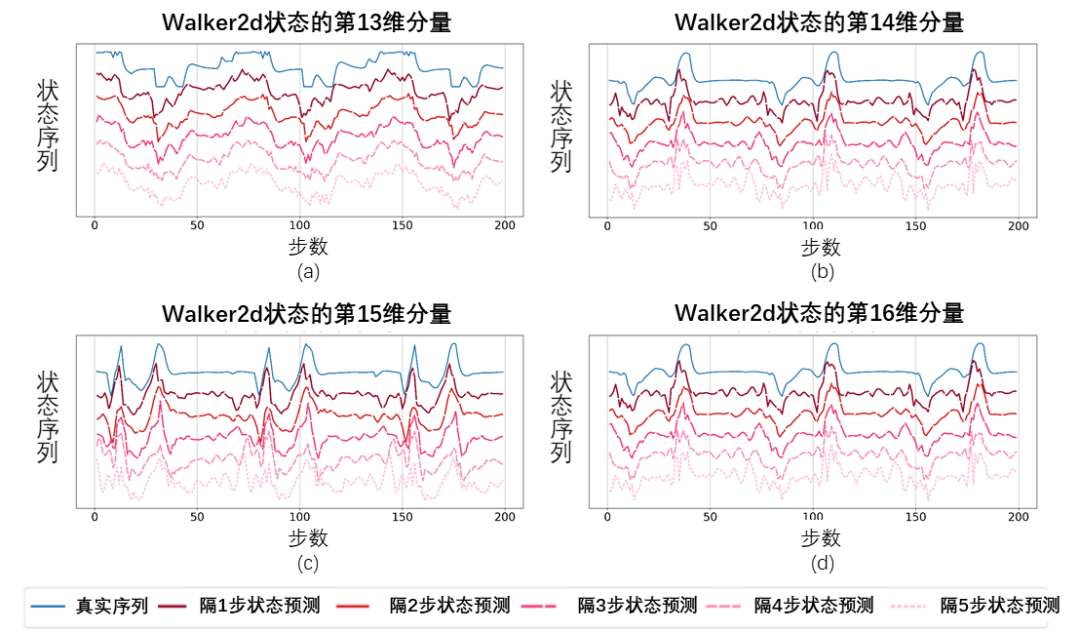 Schematic diagram of the state sequence recovered based on the predicted value of the Fourier function, tested on the Walker2d task. Among them, the blue line is a schematic diagram of the real state sequence, and the five red lines are a schematic diagram of the restored state sequence. The lower and lighter red lines represent the state sequence restored by using the longer historical state.
Schematic diagram of the state sequence recovered based on the predicted value of the Fourier function, tested on the Walker2d task. Among them, the blue line is a schematic diagram of the real state sequence, and the five red lines are a schematic diagram of the restored state sequence. The lower and lighter red lines represent the state sequence restored by using the longer historical state.
The above is the detailed content of The University of Science and Technology of China develops the 'State Sequence Frequency Domain Prediction' method, which improves performance by 20% and maximizes sample efficiency.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- The difference between has and with in Laravel association model (detailed introduction)
- How to build a mathematical model using python
- In the ISO/OSI reference model, what are the main functions of the network layer?
- Will the data stored in RAM be lost after a power outage?
- What are the steps to connect to the database using jdbc?