
Home >Technology peripherals >AI >Small but mighty models are on the rise: TinyLlama and LiteLlama become popular choices
Small but mighty models are on the rise: TinyLlama and LiteLlama become popular choices

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-01-14 12:27:151489browse
Currently, researchers are beginning to focus on compact and high-performance small models, although everyone is studying large models with parameter sizes reaching tens of billions or even hundreds of billions.
Small models are widely used in edge devices, such as smartphones, IoT devices, and embedded systems. These devices often have limited computing power and storage space and cannot efficiently run large language models. Therefore, studying small models becomes particularly important.
The two studies we are going to introduce next may meet your needs for small models.
TinyLlama-1.1B
Researchers at the Singapore University of Technology and Design (SUTD) recently released TinyLlama, a 1.1 billion-parameter The language model is pre-trained on approximately 3 trillion tokens.

- Paper address: https://arxiv.org/pdf/2401.02385.pdf
- Project address: https://github.com/jzhang38/TinyLlama/blob/main/README_zh-CN.md
TinyLlama is based on the Llama 2 architecture and tokenizer, which allows it to be easily integrated with many open source projects using Llama. In addition, TinyLlama has only 1.1 billion parameters and is small in size, making it ideal for applications that require limited computation and memory footprint.
The study shows that only 16 A100-40G GPUs can complete the training of TinyLlama in 90 days.

The project has continued to receive attention since its launch, and the current number of stars has reached 4.7K.
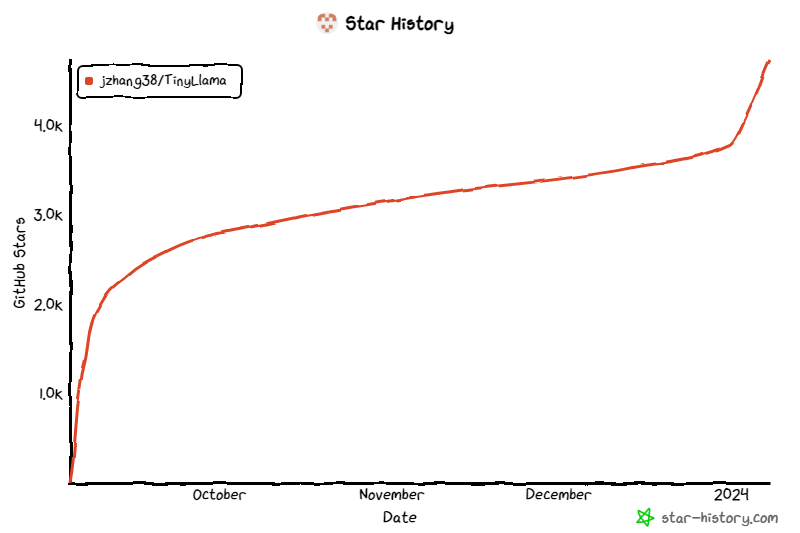
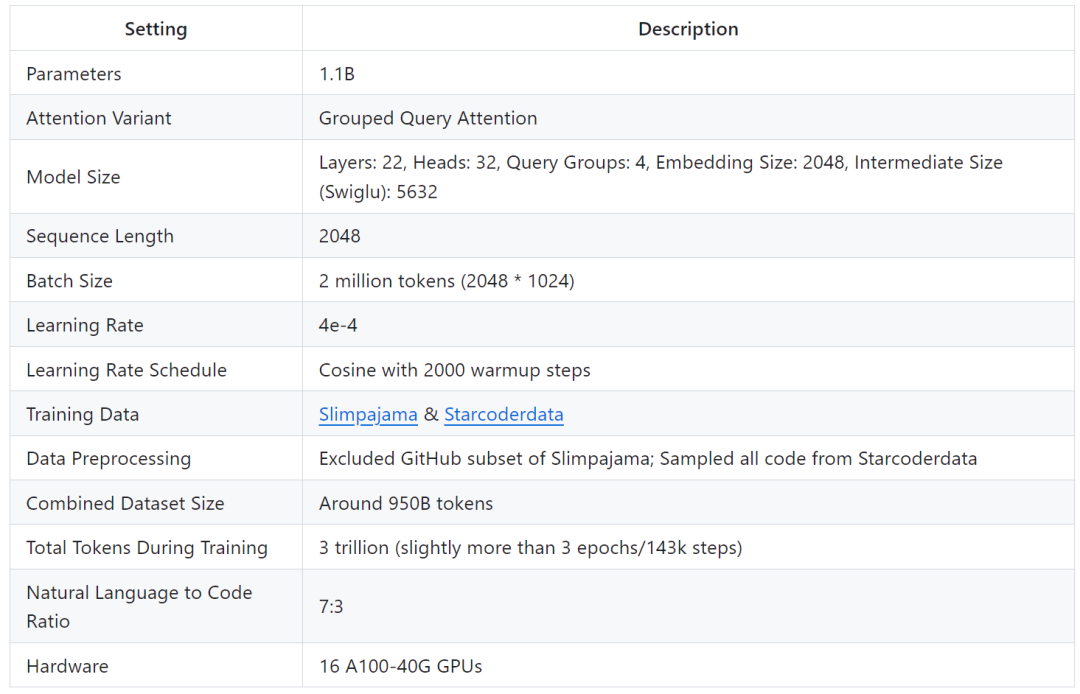
TinyLlama model architecture details are as follows:

Training details are as follows:
The researcher stated that this study aims to mine the use of larger data sets to train smaller model potential. They focused on exploring the behavior of smaller models when trained with a much larger number of tokens than recommended by the scaling law.
Specifically, the study used approximately 3 trillion tokens to train a Transformer (decoder only) model with 1.1B parameters. To our knowledge, this is the first attempt to use such a large amount of data to train a model with 1B parameters.
Despite its relatively small size, TinyLlama performs quite well on a range of downstream tasks, significantly outperforming existing open source language models of similar size. Specifically, TinyLlama outperforms OPT-1.3B and Pythia1.4B on various downstream tasks.
In addition, TinyLlama also uses various optimization methods, such as flash attention 2, FSDP (Fully Sharded Data Parallel), xFormers, etc.
With the support of these technologies, TinyLlama training throughput reaches 24,000 tokens per second per A100-40G GPU. For example, the TinyLlama-1.1B model requires only 3,456 A100 GPU hours for 300B tokens, compared to 4,830 hours for Pythia and 7,920 hours for MPT. This shows the effectiveness of this study's optimization and the potential to save significant time and resources in large-scale model training.
TinyLlama achieves a training speed of 24k tokens/second/A100. This speed is like the user can train a chinchilla with 1.1 billion parameters and 22 billion tokens on 8 A100s in 32 hours. -optimal model. At the same time, these optimizations also greatly reduce the memory usage. Users can stuff a 1.1 billion parameter model into a 40GB GPU while maintaining a per-gpu batch size of 16k tokens. Just change the batch size a little smaller, and you can train TinyLlama on RTX 3090/4090.

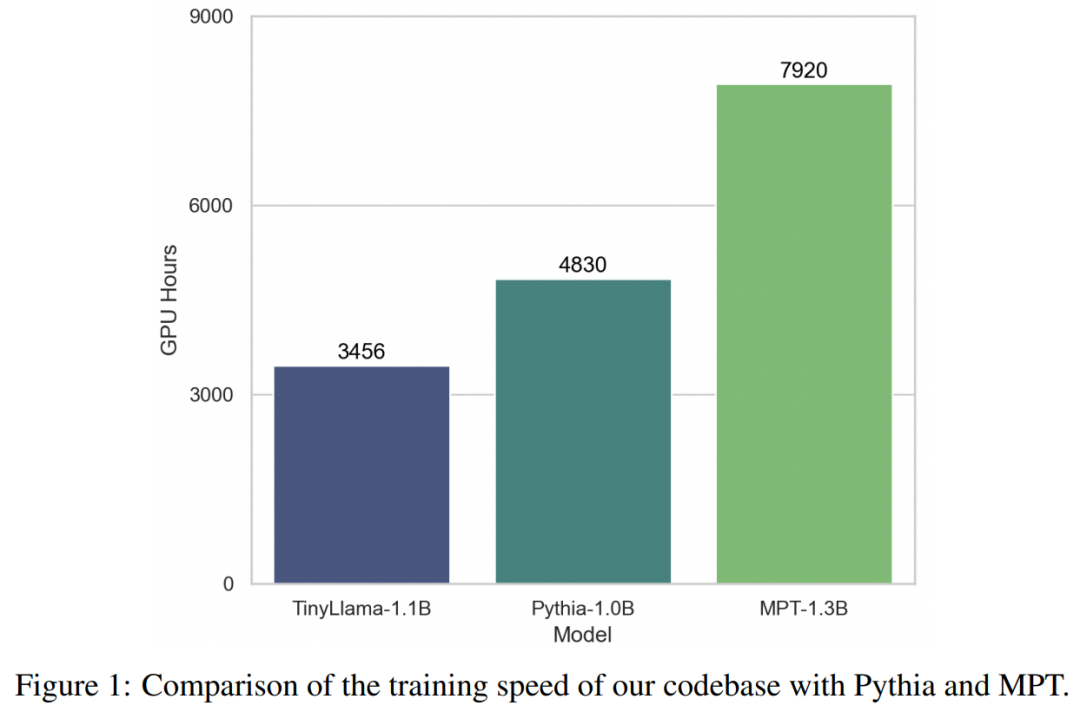
In the experiments, this research focuses on languages with pure decoder architectures model, containing approximately 1 billion parameters. Specifically, the study compared TinyLlama to OPT-1.3B, Pythia-1.0B, and Pythia-1.4B.
The performance of TinyLlama on common sense reasoning tasks is shown below. It can be seen that TinyLlama outperforms the baseline on many tasks and achieves the highest average score.

In addition, the researchers tracked the accuracy of TinyLlama on the common sense reasoning benchmark during pre-training, as shown in Figure 2, the performance of TinyLlama Improves with increasing computing resources, exceeding the accuracy of Pythia-1.4B in most benchmarks.
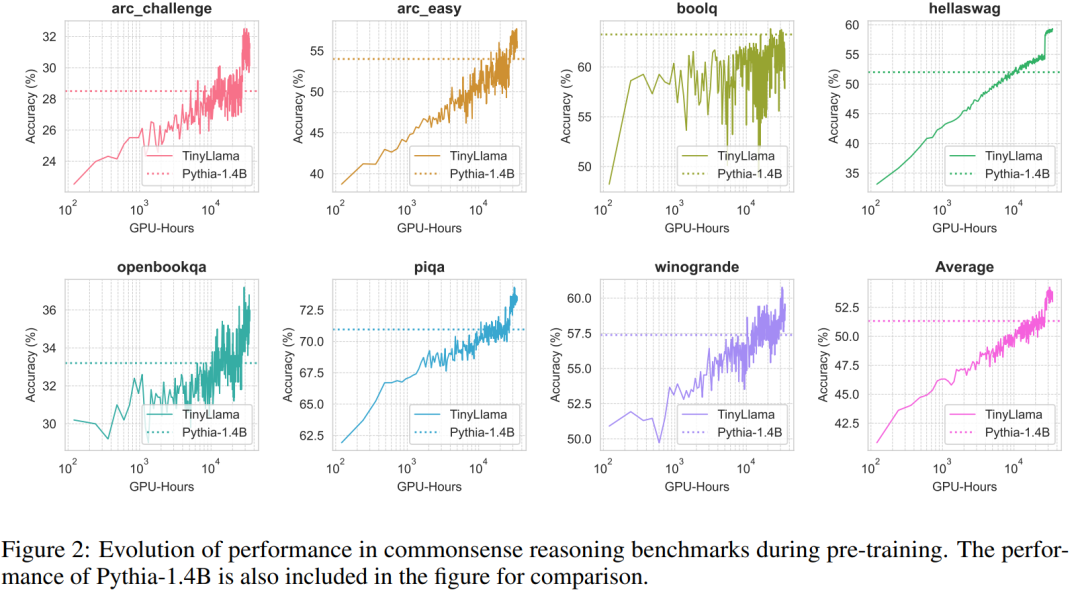
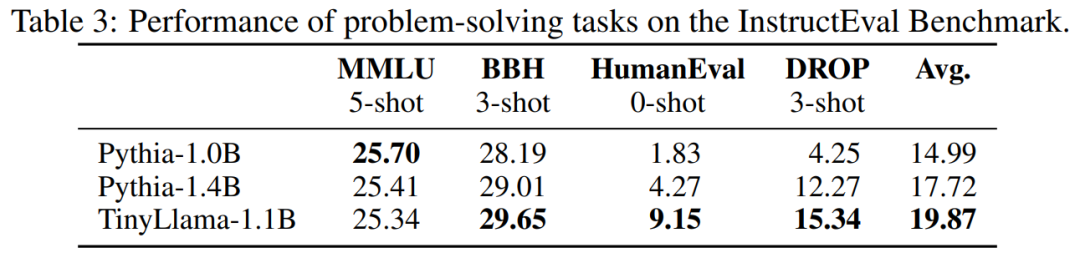
Table 3 shows that TinyLlama exhibits better problem-solving capabilities compared to existing models.
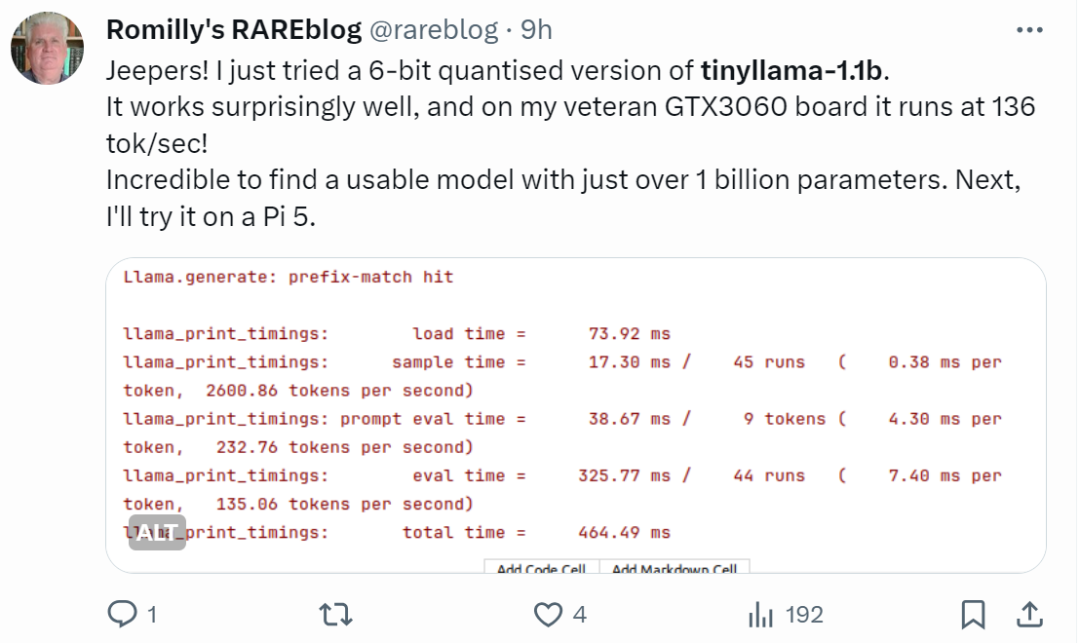
Netizens with fast hands have already started to get started: the running effect is surprisingly good, running on GTX3060, it can run at a speed of 136 tok/second .
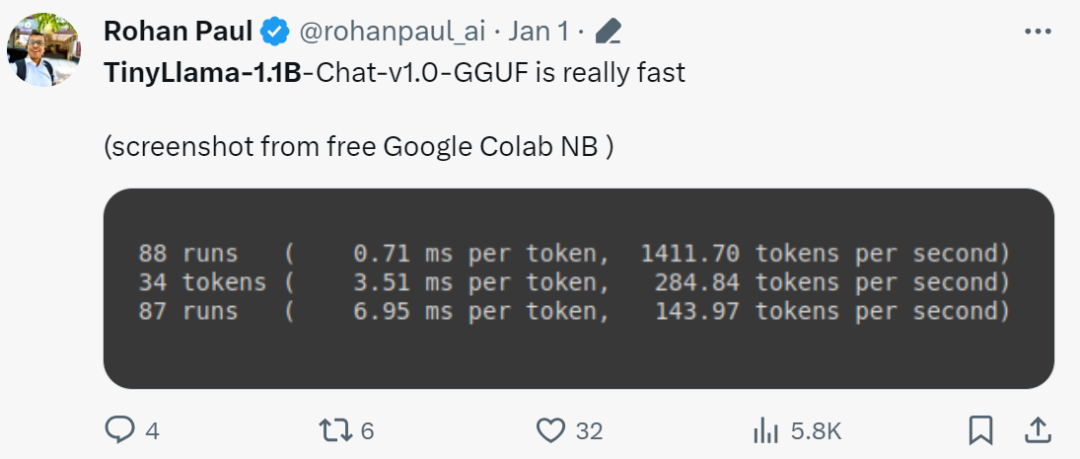
"It's really fast!"
##Small Model LiteLlama
Due to the release of TinyLlama, SLM (Small Language Model) began to attract widespread attention. Xiaotian Han of Texas Tech and A&M University released SLM-LiteLlama. It has 460M parameters and is trained with 1T tokens. This is an open source fork of Meta AI’s LLaMa 2, but with a significantly smaller model size.
Project address: https://huggingface.co/ahxt/LiteLlama-460M-1T
LiteLlama-460M-1T is trained on the RedPajama dataset and uses GPT2Tokenizer to tokenize text. The author evaluated the model on the MMLU task, and the results are shown in the figure below. Even with a significantly reduced number of parameters, LiteLlama-460M-1T can still achieve results that are comparable to or better than other models.
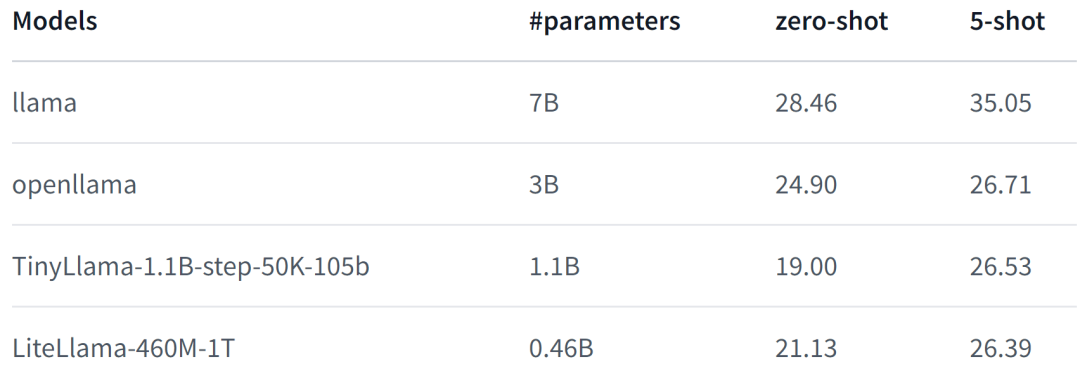
The following is the performance of the model. For more details, please refer to:
https://www.php.cn/link/05ec1d748d9e3bbc975a057f7cd02fb6

The above is the detailed content of Small but mighty models are on the rise: TinyLlama and LiteLlama become popular choices. For more information, please follow other related articles on the PHP Chinese website!