
 Technology peripheralsAIMeta launches audio-to-image AI framework for generating dubbing of character dialogue scenes
Technology peripheralsAIMeta launches audio-to-image AI framework for generating dubbing of character dialogue scenes
IT House News on January 9th, Meta recently announced an AI framework called audio2photoreal, which can generate a series of realistic NPC character models and automatically "lip-sync" the character models with the help of existing dubbing files. ” “Swing motion”.


▲ Picture source Meta research report (the same below)
IT House learned from the official research report that after receiving the dubbing file, the Audio2photoreal framework first generates a series of NPC models, and then uses quantization technology and diffusion algorithm to generate model actions. The quantification technology provides action samples for the framework. The reference,diffusion algorithm is used to improve the character,action effects generated by the frame.
The researchers mentioned that the framework can generate "high-quality action samples" at 30 FPS, and can also simulate involuntary "habitual actions" such as "pointing fingers," "turning wrists," or "shrugs" during conversations. ".


The researchers cited the results of their own experiments. In the controlled experiment, 43% of the evaluators were "strongly satisfied" with the character dialogue scenes generated by the framework. Therefore, the researchers believe that the Audio2photoreal framework can generate "more dynamic" compared to competing products in the industry. and expressive” actions.

It is reported that the research team has now disclosed the relevant code and data sets on GitHub. Interested partners can click here to access.
The above is the detailed content of Meta launches audio-to-image AI framework for generating dubbing of character dialogue scenes. For more information, please follow other related articles on the PHP Chinese website!

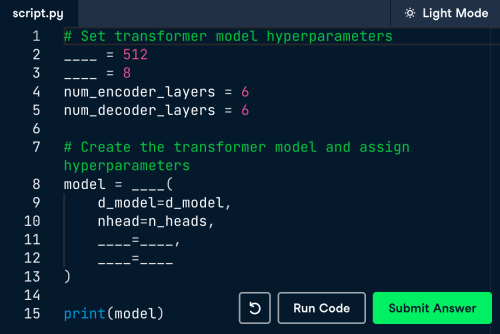
 What is Model Context Protocol (MCP)?Mar 03, 2025 pm 07:09 PM
What is Model Context Protocol (MCP)?Mar 03, 2025 pm 07:09 PMThe Model Context Protocol (MCP): A Universal Connector for AI and Data We're all familiar with AI's role in daily coding. Replit, GitHub Copilot, Black Box AI, and Cursor IDE are just a few examples of how AI streamlines our workflows. But imagine
 Building a Local Vision Agent using OmniParser V2 and OmniToolMar 03, 2025 pm 07:08 PM
Building a Local Vision Agent using OmniParser V2 and OmniToolMar 03, 2025 pm 07:08 PMMicrosoft's OmniParser V2 and OmniTool: Revolutionizing GUI Automation with AI Imagine AI that not only understands but also interacts with your Windows 11 interface like a seasoned professional. Microsoft's OmniParser V2 and OmniTool make this a re
 Replit Agent: A Guide With Practical ExamplesMar 04, 2025 am 10:52 AM
Replit Agent: A Guide With Practical ExamplesMar 04, 2025 am 10:52 AMRevolutionizing App Development: A Deep Dive into Replit Agent Tired of wrestling with complex development environments and obscure configuration files? Replit Agent aims to simplify the process of transforming ideas into functional apps. This AI-p
 I Tried Vibe Coding with Cursor AI and It's Amazing!Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!Mar 20, 2025 pm 03:34 PMVibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Runway Act-One Guide: I Filmed Myself to Test ItMar 03, 2025 am 09:42 AM
Runway Act-One Guide: I Filmed Myself to Test ItMar 03, 2025 am 09:42 AMThis blog post shares my experience testing Runway ML's new Act-One animation tool, covering both its web interface and Python API. While promising, my results were less impressive than expected. Want to explore Generative AI? Learn to use LLMs in P
 How to Use YOLO v12 for Object Detection?Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?Mar 22, 2025 am 11:07 AMYOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
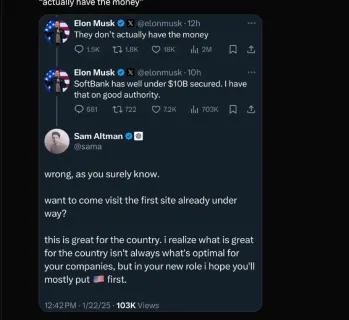 Elon Musk & Sam Altman Clash over $500 Billion Stargate ProjectMar 08, 2025 am 11:15 AM
Elon Musk & Sam Altman Clash over $500 Billion Stargate ProjectMar 08, 2025 am 11:15 AMThe $500 billion Stargate AI project, backed by tech giants like OpenAI, SoftBank, Oracle, and Nvidia, and supported by the U.S. government, aims to solidify American AI leadership. This ambitious undertaking promises a future shaped by AI advanceme
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!Mar 22, 2025 am 10:58 AMFebruary 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

WebStorm Mac version
Useful JavaScript development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SublimeText3 Chinese version
Chinese version, very easy to use

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Dreamweaver Mac version
Visual web development tools

