

 Technology peripheralsAILet the robot sense your 'Here you are', the Tsinghua team uses millions of scenarios to create universal human-machine handover
Technology peripheralsAILet the robot sense your 'Here you are', the Tsinghua team uses millions of scenarios to create universal human-machine handoverLet the robot sense your 'Here you are', the Tsinghua team uses millions of scenarios to create universal human-machine handover

Researchers from the Interdisciplinary Information Institute of Tsinghua University proposed a framework called "GenH2R", which aims to allow robots to learn a universal vision-based human-machine handover strategy. This strategy allows the robot to more reliably catch various objects with diverse shapes and complex motion trajectories, bringing new possibilities for human-computer interaction. This research provides an important breakthrough for the development of the field of artificial intelligence and brings greater flexibility and adaptability to the application of robots in real-life scenarios.

With the advent of the era of embodied intelligence (Embodied AI), we expect intelligent bodies to actively interact with the environment. In this process, it has become crucial to integrate robots into the human living environment and interact with humans (Human Robot Interaction). We need to think about how to understand human behavior and intentions, meet their needs in a way that best meets human expectations, and put humans at the center of embodied intelligence (Human-Centered Embodied AI). One of the key skills is Generalizable Human-to-Robot Handover, which enables robots to better cooperate with humans to complete a variety of common daily tasks, such as cooking, home organization, and furniture assembly. .
The explosive development of large models indicates that large-scale learning from massive high-quality data is a possible way to move towards general intelligence. So, can general intelligence be obtained through massive robot data and large-scale strategy imitation? Human-machine handover skills? However, if you consider that large-scale interactive learning between robots and humans in the real world is dangerous and expensive, the machines are likely to harm humans:

Train in a simulation environment, and use character simulation and dynamic grasping motion planning to automatically provide a large amount of diverse robot learning data, and then apply these data to real robots. This learning-based method is called " Sim-to-Real Transfer", which can significantly improve the collaborative interaction capabilities between robots and humans and has higher reliability.

Therefore, the "GenH2R" framework was proposed, starting from three perspectives: Simulation, Demonstration, and Imitation. ,Let the robot learn universal handover for any grasping method, any handover trajectory, and any object geometry for the first time based on an end-to-end approach: 1) Provides millions of levels in the "GenH2R-Sim" environment Various complex simulation handover scenarios that are easy to generate, 2) introduce a set of automated expert demonstrations (Expert Demonstrations) generation process based on vision-action collaboration, 3) use imitation learning based on 4D information and prediction assistance (point cloud time) (Imitation Learning) method.
Compared with the SOTA method (CVPR2023 Highlight), the average success rate of GenH2R's method on various test sets is increased by 14%, the time is shortened by 13%, and on real machines The performance is more robust in experiments.

- ##Paper address: https://arxiv.org/abs/2401.00929
- Paper homepage: https://GenH2R.github.io
- Paper video: https://youtu.be/BbphK5QlS1Y
Method introduction
#In order to help players who have not yet passed the level, let us learn about the details of "Simulation Environment (GenH2R-Sim)" How to solve the puzzle.
To generate high-quality, large-scale human hand-object datasets, the GenH2R-Sim environment models the scene in terms of both grasping poses and motion trajectories.
In terms of grasping postures, GenH2R-Sim introduces rich 3D object models from ShapeNet, selects 3266 daily objects suitable for handover, and uses the generation method of dexterous grasping (DexGraspNet), a total of 1 million scenes of human hands grasping objects were generated. In terms of motion trajectories, GenH2R-Sim uses several control points to generate multiple smooth Bézier curves, and introduces the rotation of human hands and objects to simulate various complex motion trajectories of hand-delivered objects.
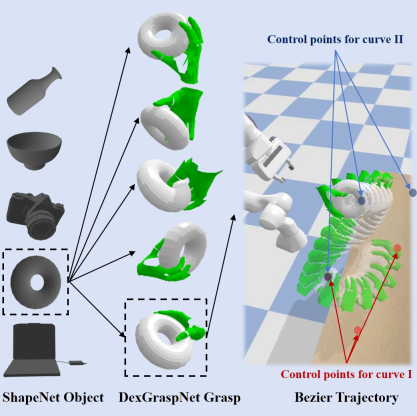
In the 1 million scenes of GenH2R-Sim, it far exceeds the latest work not only in terms of motion trajectories (1,000 vs 1 million) and number of objects (20 vs 3266) , In addition, it also introduces interactive information that is close to the real situation (such as when the robot arm is close enough to the object, the human will stop the movement and wait for the handover to be completed), rather than simple trajectory playback. Although the data generated by simulation is not completely realistic, experimental results show that large-scale simulation data is more conducive to learning than small-scale real data.
B. Large-scale generation of expert examples that are beneficial to distillation
Based on large-scale human hand and object motion trajectory data ,GenH2R automatically generates a large number of expert ,examples. The "experts" GenH2R seeks are improved Motion Planners (such as OMG Planner). These methods are non-learning, control-optimized, and do not rely on visual point clouds. They often require some scene states (such as the target grabbing position of the object). ). In order to ensure that the subsequent visual policy network can distill information beneficial to learning, the key is to ensure that the examples provided by the “experts” have vision-action correlation. If the final landing point is known during planning, the robotic arm can ignore vision and directly plan to the final position to "wait and wait". This may cause the robot's camera to be unable to see the object. This example does not help the downstream visual strategy network; If the robot arm is frequently replanned based on the position of the object, it may cause the robot arm to move discontinuously and appear in strange shapes, making it impossible to complete reasonable grasping.
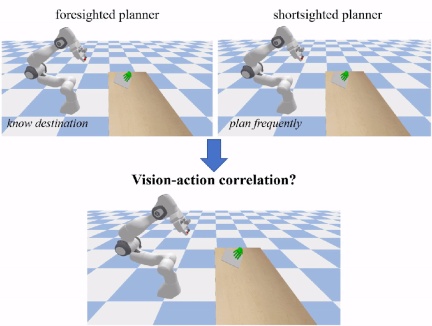
To generate Distillation-friendly expert examples, GenH2R introduces Landmark Planning. The movement trajectory of the human hand will be divided into multiple segments according to the smoothness and distance of the trajectory, with Landmark as the segmentation mark. In each segment, the human hand trajectory is smooth and the expert method plans towards the Landmark points. This approach ensures both visual-action correlation and action continuity.
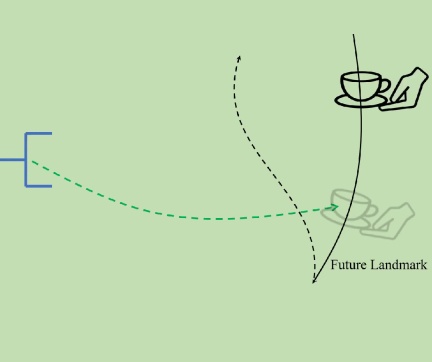
C. Prediction-assisted 4D imitation learning network
Based on large-scale expert examples, GenH2R uses imitation learning methods to build a 4D policy network to decompose the observed time series point cloud information into geometry and motion. For each frame point cloud, the pose transformation between the point cloud of the previous frame and the iterative closest point algorithm is calculated to estimate the flow information of each point, so that the point cloud of each frame All have movement characteristics. Then, PointNet is used to encode each frame of point cloud, and finally not only decodes the final required 6D egocentric action, but also outputs a prediction of the future pose of the object, enhancing the policy network's ability to predict future hand and object movements.
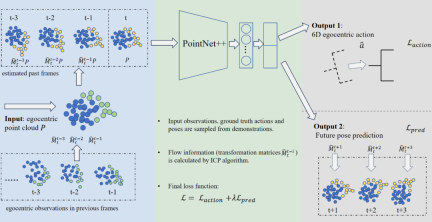
Different from more complex 4D Backbone (such as Transformer-based), this network architecture has fast reasoning speed and is more suitable for handing over objects This kind of human-computer interaction scenario requires low latency. At the same time, it can also effectively utilize timing information, achieving a balance between simplicity and effectiveness.
Experiment
A. Simulation environment experiment
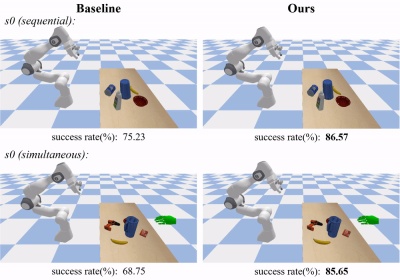
GenH2R and The SOTA method was compared under various settings. Compared with the method of using small-scale real data for training, the method of using large-scale simulation data for training in GenH2R-Sim can achieve significant advantages (in various test sets The success rate is increased by 14% on average and the time is shortened by 13%).
In the real data test set s0, the GenH2R method can successfully hand over more complex objects, and can adjust the posture in advance to avoid frequent posture adjustments when the gripper is close to the object:
In the simulation data test set t0 (introduced by GenH2R-sim), GenH2R's method can predict the future posture of the object to achieve a more reasonable approach trajectory:
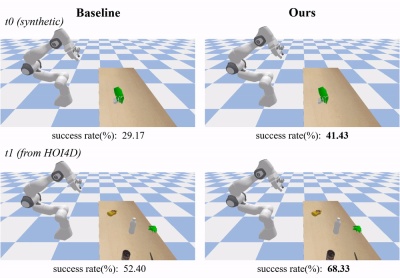
In the real data test set t1 (GenH2R-sim was introduced from HOI4D, which is about 7 times larger than the s0 test set in previous work), GenH2R's method can be generalized to unseen, Real world objects with different geometric shapes.
B. Real machine experiment
GenH2R simultaneously deploys the learned strategy to a real-world robotic arm Go up and complete the "sim-to-real" jump.
For more complex motion trajectories (such as rotation), GenH2R's strategy shows stronger adaptability; for more complex geometries, GenH2R's method can show stronger adaptability. Generalizability:

GenH2R has completed real-machine testing and user research on various handover objects, demonstrating strong robustness.

For more information on experiments and methods, please refer to the paper homepage.
Team introduction
The paper comes from Tsinghua University 3DVICI Lab, Shanghai Artificial Intelligence Laboratory and Shanghai Qizhi Research Institute. The author of the paper is Tsinghua University students Wang Zifan (co-author), Chen Junyu (co-author), Chen Ziqing and Xie Pengwei, the instructors are Yi Li and Chen Rui.
Tsinghua University’s Three-Dimensional Vision Computing and Machine Intelligence Laboratory (3DVICI Lab for short) is an artificial intelligence laboratory under the Institute of Interdisciplinary Information at Tsinghua University. It was established and directed by Professor Yi Li. 3DVICI Lab aims at the most cutting-edge issues of general three-dimensional vision and intelligent robot interaction in artificial intelligence. Its research directions cover embodied perception, interaction planning and generation, human-machine collaboration, etc., and are closely related to application fields such as robotics, virtual reality, and autonomous driving. The team's research goal is to enable intelligent agents to understand and interact with the three-dimensional world. The results have been published in major top computer conferences and journals.
The above is the detailed content of Let the robot sense your 'Here you are', the Tsinghua team uses millions of scenarios to create universal human-machine handover. For more information, please follow other related articles on the PHP Chinese website!

 How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AM
How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AMRunning large language models at home with ease: LM Studio User Guide In recent years, advances in software and hardware have made it possible to run large language models (LLMs) on personal computers. LM Studio is an excellent tool to make this process easy and convenient. This article will dive into how to run LLM locally using LM Studio, covering key steps, potential challenges, and the benefits of having LLM locally. Whether you are a tech enthusiast or are curious about the latest AI technologies, this guide will provide valuable insights and practical tips. Let's get started! Overview Understand the basic requirements for running LLM locally. Set up LM Studi on your computer
 Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AM
Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AMGuy Peri is McCormick’s Chief Information and Digital Officer. Though only seven months into his role, Peri is rapidly advancing a comprehensive transformation of the company’s digital capabilities. His career-long focus on data and analytics informs
 What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AM
What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AMIntroduction Artificial intelligence (AI) is evolving to understand not just words, but also emotions, responding with a human touch. This sophisticated interaction is crucial in the rapidly advancing field of AI and natural language processing. Th
 12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AM
12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AMIntroduction In today's data-centric world, leveraging advanced AI technologies is crucial for businesses seeking a competitive edge and enhanced efficiency. A range of powerful tools empowers data scientists, analysts, and developers to build, depl
 AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AM
AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AMThis week's AI landscape exploded with groundbreaking releases from industry giants like OpenAI, Mistral AI, NVIDIA, DeepSeek, and Hugging Face. These new models promise increased power, affordability, and accessibility, fueled by advancements in tr
 Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AM
Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AMBut the company’s Android app, which offers not only search capabilities but also acts as an AI assistant, is riddled with a host of security issues that could expose its users to data theft, account takeovers and impersonation attacks from malicious
 Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AM
Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AMYou can look at what’s happening in conferences and at trade shows. You can ask engineers what they’re doing, or consult with a CEO. Everywhere you look, things are changing at breakneck speed. Engineers, and Non-Engineers What’s the difference be
 Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AM
Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AMSimulate Rocket Launches with RocketPy: A Comprehensive Guide This article guides you through simulating high-power rocket launches using RocketPy, a powerful Python library. We'll cover everything from defining rocket components to analyzing simula


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SublimeText3 Chinese version
Chinese version, very easy to use

WebStorm Mac version
Useful JavaScript development tools

