
Home >Technology peripherals >AI >The first universal 3D graphics and text model system for furniture and home appliances that requires no guidance and can be used in generalized visualization models
The first universal 3D graphics and text model system for furniture and home appliances that requires no guidance and can be used in generalized visualization models

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-01-09 19:30:25870browse
These days, all housework is being done by robots.
The robot from Stanford that can use pots has just appeared, and the robot that can use coffee machines has just arrived, Figure-01.

#Figure-01 Just watch the demonstration video and conduct 10 hours of training to be able to operate the coffee machine proficiently. From inserting the coffee capsule to pressing the start button, it’s all done in one go.
However, it is a difficult problem to enable robots to independently learn to use various furniture and home appliances without the need for demonstration videos when encountering them. This requires the robot to have strong visual perception and decision-making planning capabilities, as well as precise manipulation skills.

Paper link: https://arxiv.org/abs/2312.01307
Project homepage: https://geometry.stanford.edu/projects/ sage/
Code: https://github.com/geng-haoran/SAGE
Overview of Research Problem

Figure 1: According to human instructions, the robotic arm can use various household appliances without any instruction.
Recently, PaLM-E and GPT-4V have promoted the application of large graphic models in robot task planning, and generalized robot control guided by visual language has become a popular research field.
The common method in the past was to build a two-layer system. The upper-layer large graphic model does planning and skill scheduling, and the lower-layer control skill strategy model is responsible for physically executing actions. But when robots face a variety of household appliances that they have never seen before and require multi-step operations in housework, both the upper and lower layers of the existing methods will be helpless.
Take the most advanced graphic model GPT-4V as an example. Although it can describe a single picture with text, when it comes to the detection, counting, positioning and status estimation of operable parts, it still has full of mistakes. The red highlights in Figure 2 are the various errors GPT-4V made when describing pictures of chests of drawers, ovens, and standing cabinets. Based on the wrong description, the robot's skill scheduling is obviously unreliable.

Figure 2: GPT-4V does not handle counting, detection,## very well #Positioning, state estimation and other tasks focused on generalized control.
The lower-level control skill strategy model is responsible for executing the tasks given by the upper-level graphic and text model in various actual situations. Most of the existing research results rigidly encode the grasping points and operation methods of some known objects based on rules, and cannot generally deal with new object categories that have not been seen before. However, end-to-end operation models (such as RT-1, RT-2, etc.) only use RGB modality, lack accurate perception of distance, and have poor generalization to changes in new environments such as height. Inspired by Professor Wang He’s team’s previous CVPR Highlight work GAPartNet [1], the research team focused on common parts (GAParts) in various categories of household appliances. Although household appliances are ever-changing, there are always a few parts that are indispensable. There are similar geometries and interaction patterns between each household appliance and these common parts. As a result, the research team introduced the concept of GAPart in the paper GAPartNet [1]. GAPart refers to a generalizable and interactive component. GAPart appears on different categories of hinged objects. For example, hinged doors can be found in safes, wardrobes, and refrigerators. As shown in Figure 3, GAPartNet [1] annotates the semantics and pose of GAPart on various types of objects.
Figure 3: GAPart: a generalizable and interactive component [1].
Based on previous research, the research team creatively introduced GAPart based on three-dimensional vision into the robot's object manipulation system SAGE. SAGE will provide information for VLM and LLM through generalizable 3D part detection and accurate pose estimation. At the decision-making level, the new method solves the problem of insufficient precise calculation and reasoning capabilities of the two-dimensional graphic model; at the execution level, the new method achieves generalized operations on each part through a robust physical operation API based on GAPart poses.
SAGE constitutes the first three-dimensional embodied graphic and text large-scale model system, providing new ideas for the entire link of robots from perception, physical interaction to feedback, and enabling robots to intelligently and universally control furniture and home appliances, etc. Complex objects explore a possible path.
System Introduction
Figure 4 shows the basic process of SAGE. First, an instruction interpretation module capable of interpreting context will parse the instructions input to the robot and its observations, and convert these parses into the next robot action program and its related semantic parts. Next, SAGE maps the semantic part (such as the container) to the part that needs to be operated (such as the slider button), and generates actions (such as the "press" action of the button) to complete the task.

Figure 4: Overview of the method.
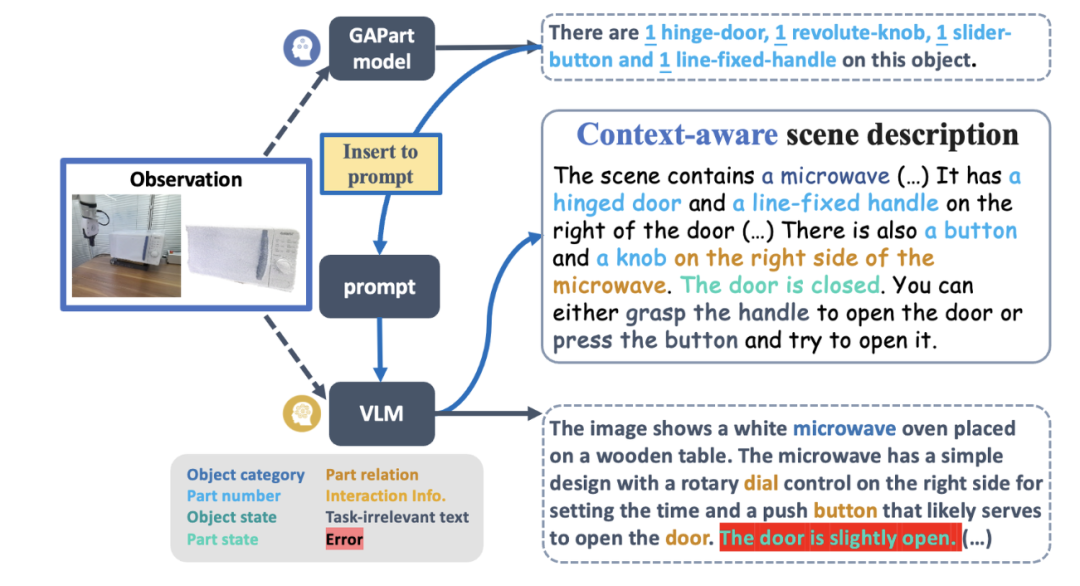
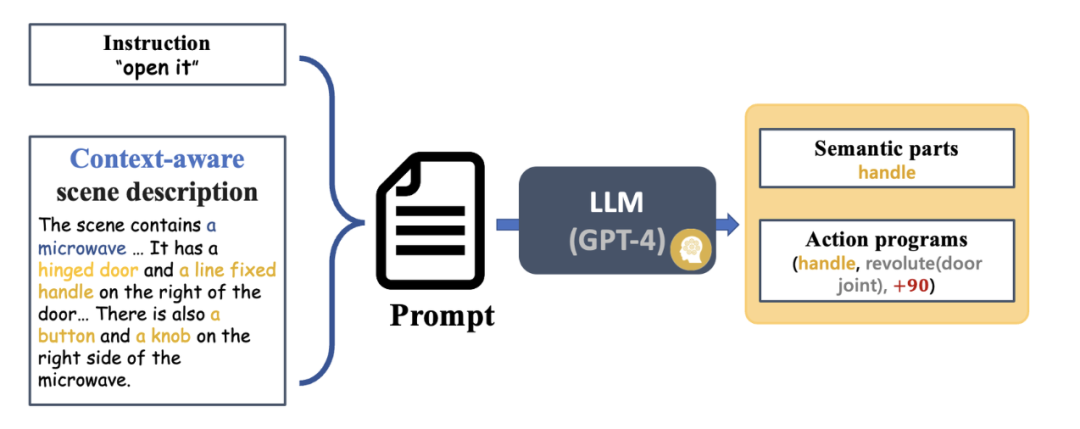
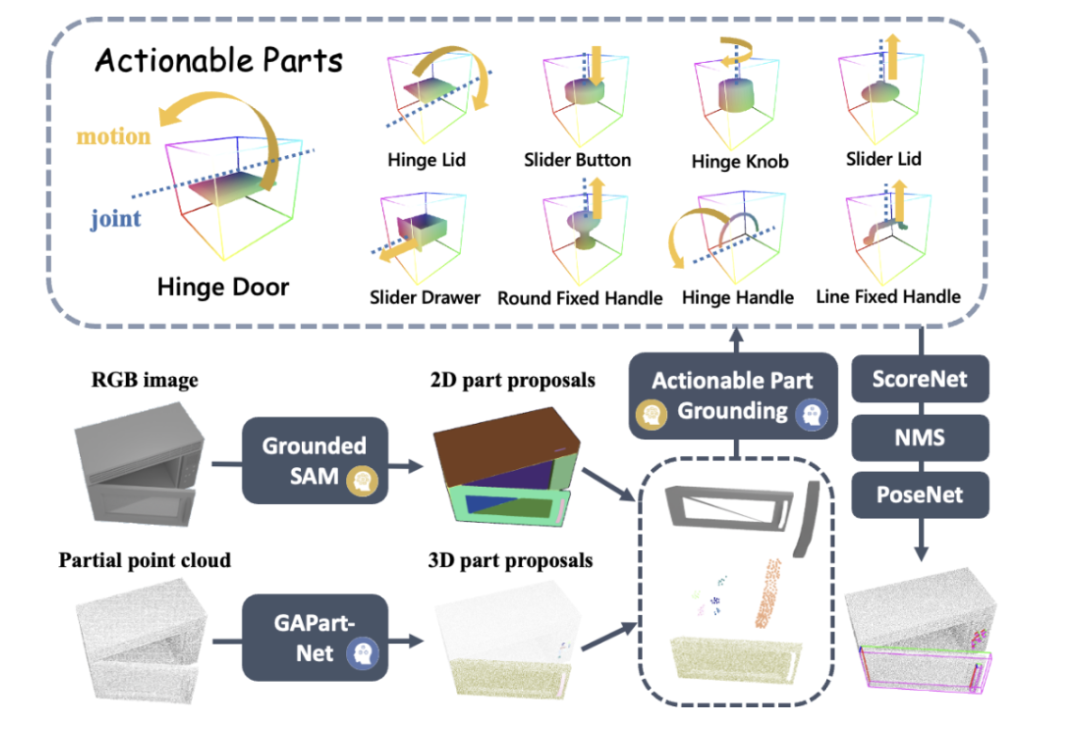



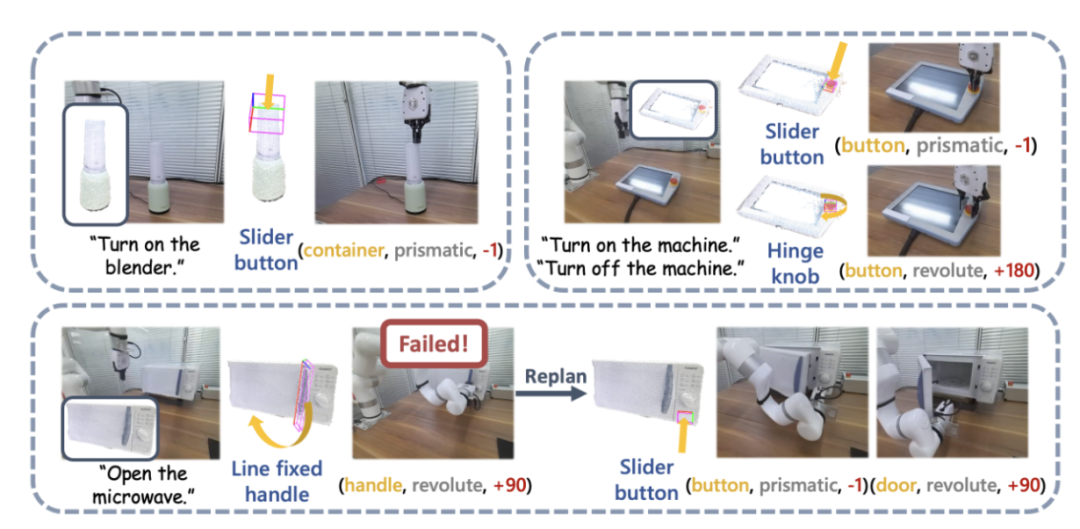
Figure 12: Real machine demonstration.
The research team also conducted large-scale real-world experiments using UFACTORY xArm 6 and a variety of different articulated objects. The upper left part of the image above shows an example of starting a blender. The top of the blender is perceived as a container for juice, but its actual function requires the push of a button to activate. SAGE's framework effectively bridges its semantic and action understanding and successfully performs the task.
The upper right part of the picture above shows the robot, which needs to press (down) the emergency stop button to stop operation and rotate (up) to restart. A robotic arm guided by SAGE accomplished both tasks with auxiliary input from a user manual. The image at the bottom of the image above shows more detail in the task of turning on a microwave.

Figure 13: More examples of real machine demonstration and command interpretation.
Summary
Team Introduction
SAGE This research result comes from the laboratory of Professor Leonidas Guibas of Stanford University, the Embodied Perception and Interaction (EPIC Lab) of Professor Wang He of Peking University, and the Intelligent Intelligence Laboratory. Source Artificial Intelligence Research Institute. The authors of the paper are Peking University student and Stanford University visiting scholar Geng Haoran (co-author), Peking University doctoral student Wei Songlin (co-author), Stanford University doctoral students Deng Congyue and Shen Bokui, and the supervisors are Professor Leonidas Guibas and Professor Wang He .
References:
[1] Haoran Geng, Helin Xu, Chengyang Zhao, Chao Xu, Li Yi , Siyuan Huang, and He Wang. Gapartnet: Cross-category domaingeneralizable object perception and manipulation via generalizable and actionable parts. arXiv preprint arXiv:2211.05272, 2022.
[2] Kirillov, Alexander, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao et al. "Segment anything." arXiv preprint arXiv:2304.02643 (2023).
[3] Zhang, Hao, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, and Heung-Yeung Shum. "Dino: Detr with improved denoising anchor boxes for end-to-end object detection." arXiv preprint arXiv:2203.03605 (2022).
[4] Xiang , Fanbo, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu et al. "Sapien: A simulated part-based interactive environment." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11097-11107.2020.
The above is the detailed content of The first universal 3D graphics and text model system for furniture and home appliances that requires no guidance and can be used in generalized visualization models. For more information, please follow other related articles on the PHP Chinese website!