
 Technology peripheralsAIGoogle Deepmind envisions a future that reinvents robots, bringing embodied intelligence to large models
Technology peripheralsAIGoogle Deepmind envisions a future that reinvents robots, bringing embodied intelligence to large models
In the past year, a succession of large-scale models have made breakthroughs that are reshaping the field of robotics research.
With the most advanced large models becoming the "brains" of robots, robots are evolving faster than imagined.
In July, Google DeepMind announcedthe launch of RT-2: the world's first vision-language-action (VLA) model to control robots.
Just give the command like a dialogue, and it will be able to identify Swift among a bunch of pictures and give her a jar of "happy water."

#It can even think actively, completing a multi-stage reasoning leap from "selecting an animal for extinction" to grabbing a plastic dinosaur on the table.

After RT-2, Google DeepMind proposed Q-Transformer, and the robotics world also has its own Transformer. Q-Transformer enables robots to break through their reliance on high-quality demonstration data and become better at accumulating experience by relying on independent "thinking".
Just two months after its release, RT-2 is having another ImageNet moment for robots. Google DeepMind and other institutions launched the Open A new idea for training universal robots.
Imagine simply asking your robot assistants to complete these tasks, such as "clean the house" or "make a delicious and healthy meal." For humans, these tasks may be simple, but for robots, they require a deep understanding of the world, which is not easy. Based on years of research in the field of robot Transformers, Google recently announced a series of robot research progress: AutoRT, SARA-RT and RT-Trajectory, which can help robots make decisions faster and more efficiently. Better understand the environment they are in and better guide themselves to complete tasks. Google believes that with the launch of research results such as AutoRT, SARA-RT and RT-Trajectory, it can bring improvements to the data collection, speed and generalization capabilities of real-world robots. Next, let us review these important studies.AutoRT: Leverage large models to better train robots
AutoRT combines large base models such as large language models (LLM) or visual language models (VLM) and robot control models (RT-1 or RT-2), creating a system that can deploy robots in new environments to collect training data. AutoRT can simultaneously guide multiple robots equipped with video cameras and end effectors to perform diverse tasks in a variety of environments. Specifically, each robot will use a visual language model (VLM) to "look around" and understand its environment and objects within its line of sight, based on AutoRT. Next, the large language model will propose a series of creative tasks for it, such as "put snacks on the table," and play the role of decision-maker, choosing the tasks for the robot to perform. Researchers conducted an extensive seven-month evaluation of AutoRT in real-world settings. Experiments have proven that the AutoRT system can safely coordinate up to 20 robots at the same time, and a maximum of 52 robots in total. By guiding the robots to perform a variety of tasks within a variety of office buildings, the researchers collected a diverse dataset spanning 77,000 robot trials with 6,650 unique tasks.
While AutoRT is just a data collection system now, think of it as the early stages of autonomous robots in the real world. It features safety guardrails, one of which is a set of safety-focused cue words that provide ground rules to follow when the robot makes LLM-based decisions.
These rules are inspired in part by Isaac Asimov's Three Laws of Robotics, the most important of which is that robots "must not harm humans." Safety rules also require robots not to attempt tasks involving humans, animals, sharp objects or electrical appliances.
Only working on prompt words cannot fully guarantee the safety of robots in practical applications. Therefore, the AutoRT system also includes a layer of practical safety measures that is a classic design of robotics. For example, collaborative robots are programmed to automatically stop if the forces on their joints exceed a given threshold, and all autonomously controlled robots are able to be restricted to the line of sight of a human supervisor via a physical deactivation switch.
SARA-RT: Make the robot Transformer (RT) faster and more streamlined
Another achievement, SARA-RT, can transform the robot Transformer (RT) The model is converted to a more efficient version.
The RT neural network architecture developed by the Google team has been used in the latest robot control systems, including the RT-2 model. The best SARA-RT-2 model is 10.6% more accurate and 14% faster than the RT-2 model when given a brief image history. Google says it's the first scalable attention mechanism that increases computing power without compromising quality.
While Transformers are powerful, they can be limited by computational requirements, slowing decision-making. Transformer mainly relies on the attention module of quadratic complexity. This means that if the input to the RT model is doubled (e.g., providing the robot with more or higher-resolution sensors), the computational resources required to process that input increase fourfold, resulting in slower decision-making.
SARA-RT adopts a novel model fine-tuning method (called "up-training") to improve the efficiency of the model. Uptraining converts quadratic complexity into purely linear complexity, significantly reducing computational requirements. This conversion not only improves the speed of the original model, but also maintains its quality.
Google hopes that many researchers and practitioners will apply this practical system to robotics and other fields. Because SARA provides a general approach to speeding up Transformers without the need for computationally expensive pre-training, this approach has the potential to scale Transformer technology at scale. SARA-RT does not require any additional coding as various open source linear variants are available.
When SARA-RT is applied to the SOTA RT-2 model with billions of parameters, it enables faster decision-making and better performance in a variety of robotic tasks:

SARA-RT-2 model for manipulation tasks. The robot's movements are conditioned on images and textual instructions.
With its solid theoretical foundation, SARA-RT can be applied to various Transformer models. For example, applying SARA-RT to the Point Cloud Transformer, which processes spatial data from a robot's depth camera, can more than double the speed.
RT-Trajectory: Helping Robots Generalize
Humans can intuitively understand and learn how to clean tables, but robots need many possible ways to translate instructions into actual physical action.
Traditionally, training of robotic arms relies on mapping abstract natural language (wipe the table) to concrete actions (close gripper, move left, move right), which makes the model difficult to generalize to a new task. In contrast, the RT-Trajectory Model enables the RT model to understand "how" a task is accomplished by interpreting specific robot actions (such as those in a video or sketch).
RT-Trajectory model can automatically add visual contours to describe the robot's movements in the training video. RT-Trajectory overlays each video in the training dataset with a 2D trajectory sketch of the gripper as the robot arm performs a task. These trajectories, in the form of RGB images, provide low-level, practical visual cues for the model to learn robot control strategies.
When tested on 41 tasks not seen in the training data, the performance of the robot arm controlled by RT-Trajectory was more than double that of the existing SOTA RT model: the task success rate reached 63% , while the success rate of RT-2 is only 29%.
The system is so versatile that RT-Trajectory can also create trajectories by watching human demonstrations of the required tasks, and even accepts hand-drawn sketches. Moreover, it can adapt to different robot platforms at any time.
 Left picture: The robot controlled by the RT model trained only using the natural language data set was frustrated when performing the new task of wiping the table, while the robot controlled by the RT trajectory model was After training on the same dataset augmented with 2D trajectories, the wiping trajectory was successfully planned and executed. Right: A trained RT trajectory model, given a new task (wiping the table), can create 2D trajectories in a variety of ways, with human assistance or on its own using a visual language model.
Left picture: The robot controlled by the RT model trained only using the natural language data set was frustrated when performing the new task of wiping the table, while the robot controlled by the RT trajectory model was After training on the same dataset augmented with 2D trajectories, the wiping trajectory was successfully planned and executed. Right: A trained RT trajectory model, given a new task (wiping the table), can create 2D trajectories in a variety of ways, with human assistance or on its own using a visual language model.
RT trajectories exploit the rich robot motion information that is present in all robot datasets but is currently underutilized. RT-Trajectory not only represents another step on the path to creating robots that move efficiently and accurately for new tasks, but also enables the discovery of knowledge from existing data sets.
The above is the detailed content of Google Deepmind envisions a future that reinvents robots, bringing embodied intelligence to large models. For more information, please follow other related articles on the PHP Chinese website!

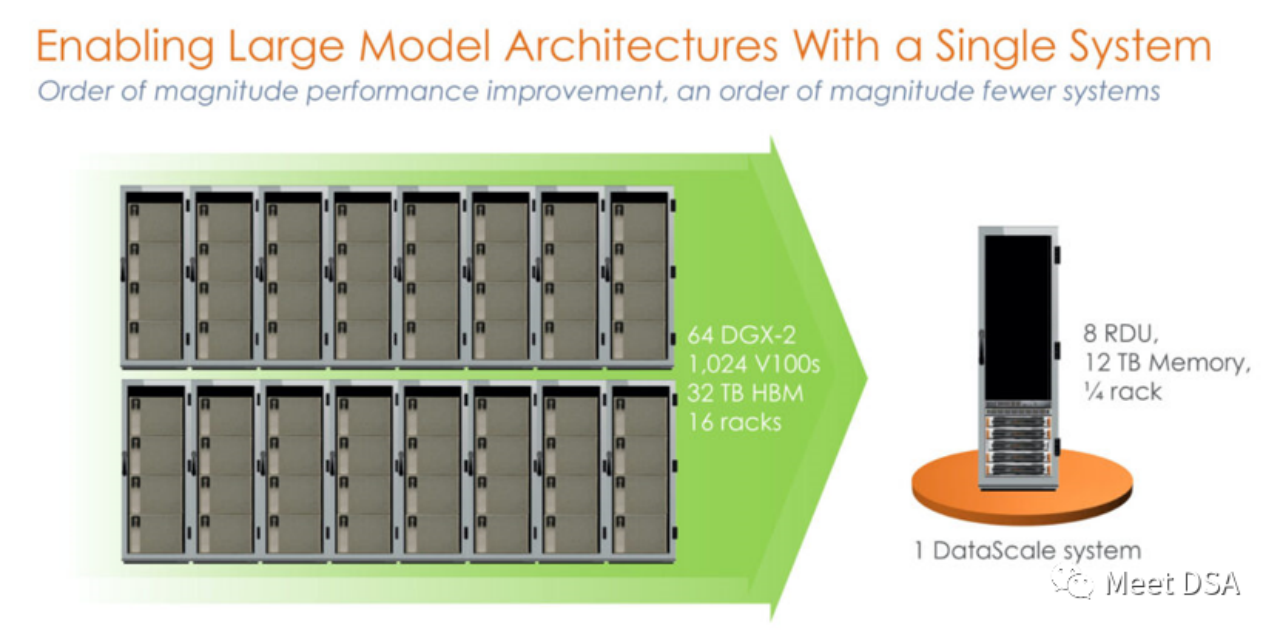 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
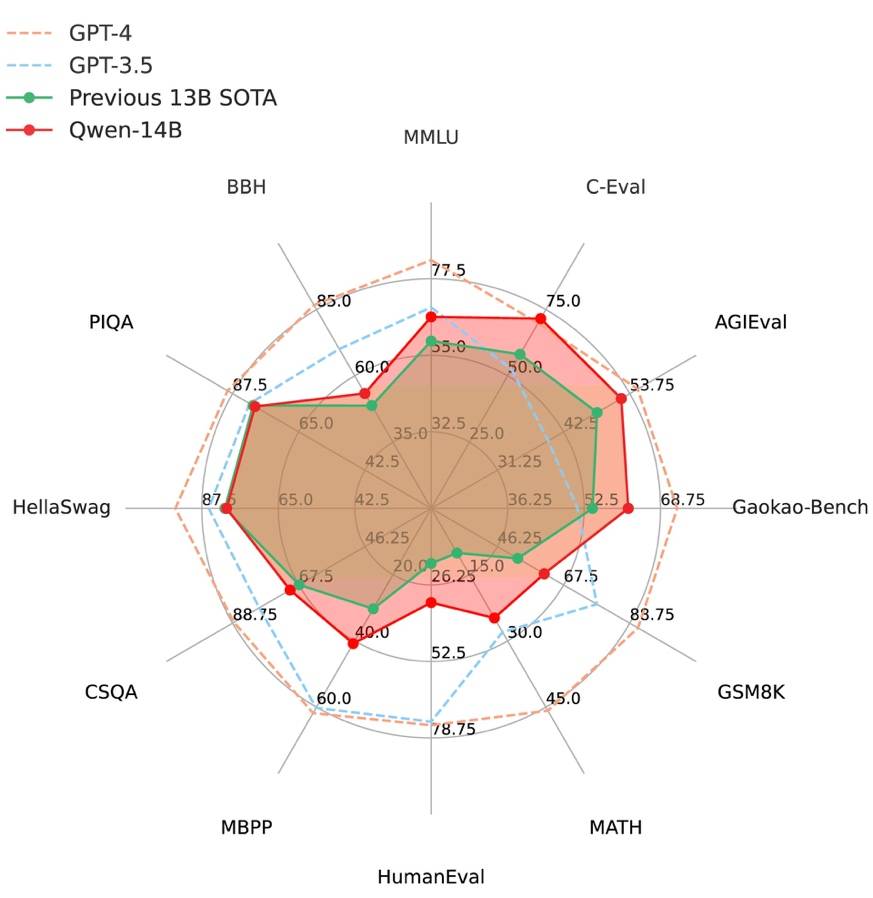 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
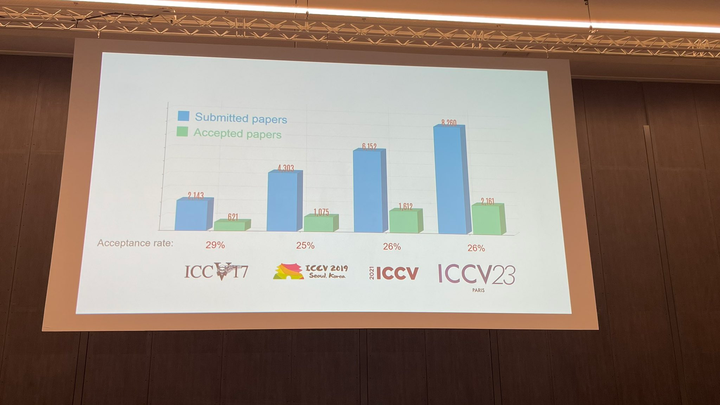 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
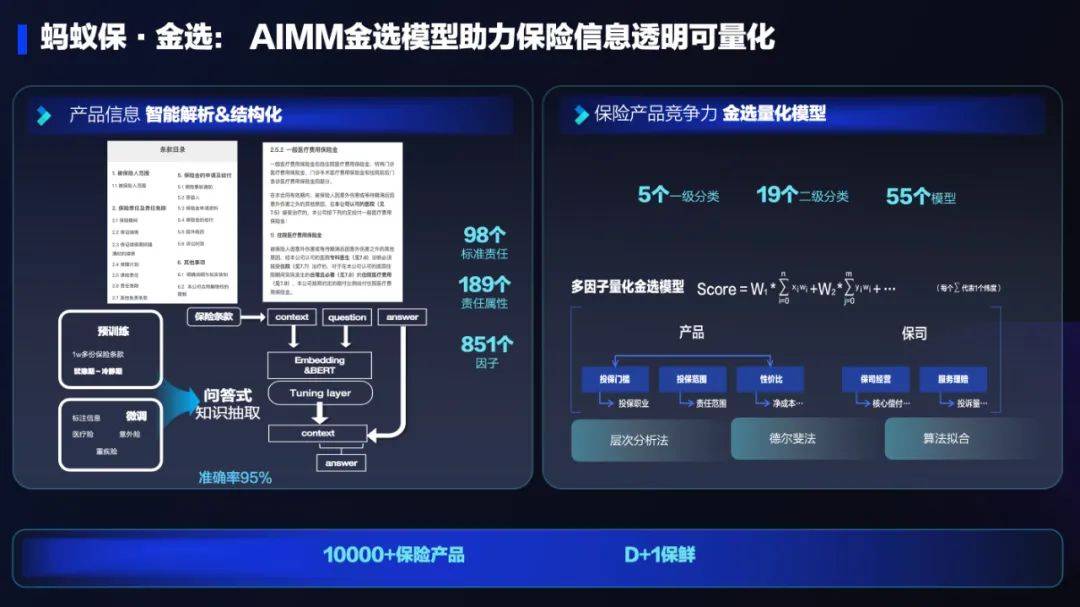 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM
快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM杭州第19届亚运会不仅是国际顶级体育盛会,更是一场精彩绝伦的中国科技盛宴。本届亚运会中,快手StreamLake与杭州电信深度合作,联合打造智慧观赛新体验,在击剑赛事的转播中,全面应用了快手StreamLake六自由度技术,其中“子弹时间”也是首次应用于击剑项目国际顶级赛事。中国电信杭州分公司智能亚运专班组长芮杰表示,依托快手StreamLake自研的4K3D虚拟运镜视频技术和中国电信5G/全光网,通过赛场内部署的4K专业摄像机阵列实时采集的高清竞赛视频,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Notepad++7.3.1
Easy-to-use and free code editor

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

