
Home >Technology peripherals >AI >Go all out to close the loop! DriveMLM: Perfectly combine LLM with autonomous driving behavior planning!
Go all out to close the loop! DriveMLM: Perfectly combine LLM with autonomous driving behavior planning!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-01-05 09:50:191408browse
Written in front&The author’s personal understanding
Large-scale language models have opened up a new pattern for intelligent driving, giving them human-like thinking and cognitive abilities. This article takes an in-depth look at the potential of large language models (LLMs) in autonomous driving (AD). Then DriveMLM is proposed, which is an AD framework based on LLM that can realize closed-loop autonomous driving in the simulation environment. Specifically, there are the following points:
- (1) This article bridges the gap between language decision-making and vehicle control commands by standardizing decision-making states based on ready-made motion planning modules;
- (2) Multimodal LLM (MLLM) is used to model the behavior planning module of a modular AD system that uses driving rules, user commands, and inputs from various sensors (such as cameras, lidar) as input, And make driving decisions and provide explanations; the model can be plugged into existing AD systems (such as Apollo) for closed-loop driving;
- (3) An effective data engine is designed to collect data sets. Sets include decision states and corresponding interpretable annotations for model training and evaluation.
Finally we conducted extensive experiments on DriveMLM, and the results showed that DriveMLM achieved a driving score of 76.1 on CARLA Town05 Long and exceeded the Apollo baseline by 4.7 points under the same settings, proving that DriveMLM effectiveness. We hope this work can serve as a baseline for LLM autonomous driving.
Related introduction to DriveMLM
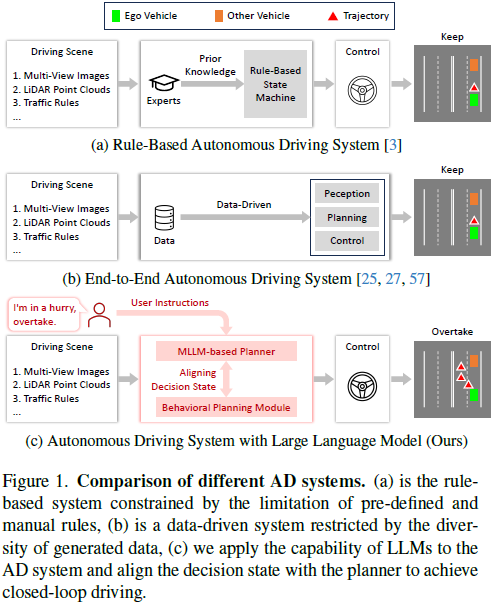
In recent years, autonomous driving (AD) has made significant progress, as shown in Figure 1b. Traditional rule-based systems, which rely on predefined rule sets provided by prior knowledge (see Figure 1a), evolve into data-driven end-to-end systems. Despite the progress of these systems, they still encounter limitations due to limitations in expert knowledge or the diversity of training data. This makes it difficult for them to handle corner situations, although human drivers may find handling these situations intuitive. Compared with these traditional rule-based or data-driven AD planners, large language models (LLMs) trained using web-scale text corpora have extensive world knowledge, robust logical reasoning, and advanced cognitive capabilities. These capabilities position them as potential planners in AD systems, providing a human-like approach to autonomous driving.
Some recent research has integrated LLM into AD systems, focusing on generating language-based decisions for driving scenarios. However, these methods have limitations when it comes to performing closed-loop driving in real-world environments or real simulations. This is because the output of LLM is mainly language and concepts and cannot be used for vehicle control. In traditional modular AD systems, the gap between high-level strategic goals and low-level control behaviors is connected through the behavior planning module, and the decision-making state of this module can be easily converted into vehicle control signals through subsequent motion planning and control. This motivates us to align the LLM with the decision-making state of the behavior planning module and further design an LLM-based closed-loop AD system by using the aligned LLM for behavior planning, which can run on a real-world environment or a realistic simulation environment.
Based on this, we proposed DriveMLM, the first LLM-based AD framework that can achieve closed-loop autonomous driving in a realistic simulation environment. To achieve this, we have three key designs: (1) We study the decision-making states of the behavior planning module of the Apollo system and transform them into a form that LLM can easily process. (2) A multimodal LLM (MLLM) planner is developed that can accept current multimodal inputs, including multi-view images, lidar point clouds, traffic rules, system messages and user instructions, and predict Decision state; (3) In order to obtain sufficient training data for behavior planning-state alignment, we manually collected 280 hours of driving data on CARLA and converted it into decision states and corresponding explanation annotations through an efficient data engine. Through these designs, we can obtain an MLLM planner that can make decisions based on driving scenarios and user needs, and its decisions can be easily converted into vehicle control signals for closed-loop driving.
DriveMLM has the following advantages: (1) Thanks to the consistent decision-making state, DriveMLM can be easily integrated with existing modular AD systems (such as Apollo) to achieve closed-loop driving without any major Change or modification. (2) By taking language instructions as input, our model can handle user needs (e.g., overtaking the car) and high-level system messages (e.g., defining basic driving logic). This makes DriveMLM more flexible and able to adapt to different driving situations and curves. (3) It can provide interpretability and explain different decisions. This enhances the transparency and trustworthiness of our model, as it can explain its actions and choices to users.
In summary, the main contributions of DriveMLM are as follows:
- Proposes an AD framework based on LLM, bridging LLM and The gap between closed loop driving.
- To implement this framework, we customized a set of decision states in a form that can be easily processed by LLM, designed an MLLM planner for decision prediction, and developed a data engine that can efficiently Decision states and corresponding explanation annotations are automatically generated for model training and evaluation.
- To verify the effectiveness of DriveMLM, we not only evaluate our method based on closed-loop driving metrics including driving score (DS) and miles per intervention (MPI), but also use understanding metrics including accuracy, F1 index of decision state, BLEU-4, CIDEr and METEOR of decision explanation) to evaluate the driving understanding ability of the model. It is worth noting that our method obtains 76.1 DS, 0.955 MPI results on CARLA Town05 Long, which is 4.7 points and 1.25 times higher than Apollo. Furthermore, we can change the MLLM planner's decision-making by describing special requirements with language instructions, as shown in Figure 2, such as making way for ambulances or traffic regulations

Detailed introduction to the DriveMLM method
Overview
The DriveMLM framework integrates the world knowledge and reasoning capabilities of large language models (LLM) into autonomous driving ( AD) system, realizing closed-loop driving in a realistic simulation environment. As shown in Figure 3, this framework has three key designs: (1) Behavior planning state alignment. This part aligns the language decision output of LLM with the behavior planning module of mature modular AD systems such as Apollo. In this way, the output of the LLM can be easily converted into vehicle control signals. (2) MLLM planner. It is a combination of a multimodal marker and a multimodal LLM (MLLM) decoder. The multimodal tagger converts different inputs (such as multi-view images, lidar, traffic rules and user requirements) into unified tags, and the MLLM decoder makes decisions based on the unified tags. (3) Efficient data collection strategy. It introduces a tailored data collection method for LLM-based autonomous driving, ensuring a comprehensive data set including decision status, decision explanations and user commands.
During the inference process, the DriveMLM framework utilizes multi-modal data to make driving decisions. These data include: surround images and point clouds. System messages are a collection of task definitions, traffic rules, and decision status definitions. These tokens are input to the MLLM decoder, which generates decision state tokens along with corresponding explanations. Finally, the decision state is input to the motion planning and control module. This module calculates the final trajectory of the vehicle control.
Behavioral Planning States Alignment
Translating language selections from large language models (LLMs) into actionable control signals is critical for vehicle control. To achieve this, we aligned the output of the LLM with the decision phase of the behavioral planning module in the popular Apollo system. Based on common approaches, we divide the decision-making process into two categories: speed decision-making and path decision-making. Specifically, the speed decision status includes (maintain, accelerate, decelerate, stop), and the path decision status includes (FOLLOW, LEFT CHANGE, RIGHT CHANGE, LEFT BORROW, RIGHT BORROW).
To enable the language model to make accurate predictions between these states, we establish a comprehensive connection between the language description and the decision state, as shown in the system information in Table 1. This correlation is used as part of the system messages and integrated into the MLLM planner. Therefore, once the LLM describes certain situations, the predictions will converge into clear decisions within the decision space. Each time, a speed decision and a path decision are inferred from each other and sent to the motion planning framework. A more detailed definition of decision states can be found in the supplementary material.

MLLM Planner
DriveMLM’s MLLM planner consists of two components: the multimodal tokenizer and the MLLM decoder. The two modules work closely together, processing various inputs to accurately determine driving decisions and provide explanations for those decisions.
Multimodal tokenizer. This tokenizer is designed to handle various forms of input efficiently: For temporal lookaround images: Use a temporal QFormer to process the lookaround image from timestamp −T to 0 (the current timestamp). For lidar data, we first input the point cloud as input to the Sparse Pyramid Transformer (SPT) backbone to extract lidar features. For system messages and user instructions, we simply treat them as ordinary text data and use LLM’s token embedding layer to extract their embeddings.
MLLM decoder. The decoder is the core of converting tokenized input into decision states and decision interpretations. To this end, we designed a system message template for LLM-based AD, as shown in Table 1. As can be seen, the system message contains a description of the AD task, traffic rules, definition of decision states, and placeholders indicating where each modal information is merged. This approach ensures seamless integration of inputs from various modalities and sources.
The output is formatted to provide decision status (see Q2 in Table 1) and decision explanation (see Q3 in Table 1), thereby providing transparency and clarity in the decision-making process. Regarding supervised methods, our framework follows common practice of using cross-entropy loss in next token prediction. In this way, MLLM planners can develop a detailed understanding and processing of data from different sensors and sources and translate it into appropriate decisions and interpretations.
Efficient Data Engine
We propose a data generation paradigm that can create decision states and explanation annotations from various scenarios in the CARLA simulator. This pipeline can address the limitations of existing driving data, which lack decision states and detailed explanations for training LLM-based AD systems. Our pipeline consists of two main components: data collection and data annotation.
Data collection is designed to increase diversity in decision-making while remaining realistic. First, various challenging scenarios are constructed in a simulation environment. Safe driving requires complex driving behaviors. Experts, whether experienced human drivers or agents, are then asked to safely drive through these scenarios, which are triggered at one of its many accessible locations. Notably, interaction data is generated when experts randomly propose driving demands and drive accordingly. Once the expert safely drives to the destination, the data is recorded.
Data annotation mainly focuses on decision-making and interpretation. First, speed and path decision states are automatically annotated based on expert driving trajectories by using hand-crafted rules. Second, explanation annotations are first generated based on the scene, dynamically defined by nearby current elements. Third, the generated explanation annotations are refined by manual annotations and their diversity is expanded by GPT-3.5. In addition, the interaction content is also refined by human annotators, including the execution or rejection of human requests. In this way, we avoid expensive frame-by-frame decision state annotation, as well as expensive manual writing of explanation annotations from scratch, greatly speeding up our data annotation process.
Experiment
Data Analysis
We collected 280 hours of driving data for training. The data includes 50 kilometers of routes and 30 driving scenarios with different weather and lighting conditions collected on CARLA's 8 maps (Town01, Town02, Town03, Town04, Town06, Town07, Town10HD, Town12). On average, each scene has about 200 trigger points on each map that are triggered randomly. Each situation is a common or rare safety-critical situation in driving. Details of these scenarios are provided in the Supplementary Notes. For each frame, we collect images from four cameras, front, rear, left, and right, as well as point clouds from a lidar sensor added at the center of the ego vehicle. All the data we collect has corresponding interpretations and accurate decisions that successfully drive the scenario forward.
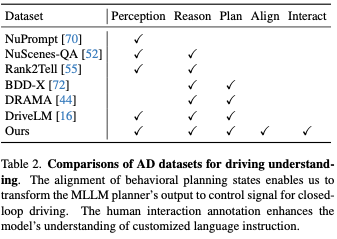
Table 2 shows a comparison with previous datasets designed for driving understanding using natural language. Our data have two unique characteristics. The first is the consistency of behavioral planning states. This allows us to convert the output of the MLLM planner into control signals so that our framework can control the vehicle in closed-loop driving. The second is interpersonal interaction annotation. It is characterized by natural language instructions given by humans and the corresponding decisions and interpretations. The goal is to improve the ability to understand human commands and respond accordingly.
Closed-loop autonomous driving evaluation
We evaluate closed-loop driving in CARLA, the most widely used and realistic publicly available simulation benchmark. State-of-the-art methods capable of performing closed-loop driving in CARLA are included for performance comparison. The open source Apollo was also evaluated in CARLA as a baseline. Apart from our approach, no other LLM-based approach has shown readiness for deployment and evaluation. All methods are evaluated on the Town05 long-term benchmark.
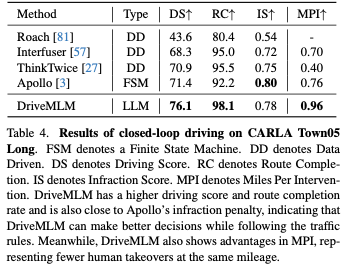
Table 4 lists driving scores, route completion and violation scores. Note that although Apollo is a rule-based approach, its performance is almost on par with recent end-to-end approaches. DriveMLM significantly outperforms all other methods in driving scores. This suggests that DriveMLM is better suited to handle state transitions to pass through the hard drive safely. The last column in Table 4 shows the results of the MPI evaluation. This metric shows a more comprehensive driving performance because agents are required to complete all routes. In other words, all situations on all routes will be encountered by the agent under test. Thinktwice implements better DS than Interfuser, but has lower MPI due to frequent crossing of stop lines. However, CARLA's penalties for this behavior are minimal. In contrast, MPI treats every traffic violation as a takeover. DriveMLM also achieves the highest MPI among all other methods, indicating that it is able to avoid more situations, resulting in a safer driving experience.
Driving Knowledge Assessment
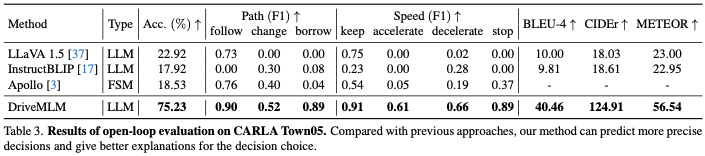
We use open-loop assessment to assess driving knowledge, including decision-making prediction and explanation prediction tasks. Table 3 shows the accuracy of the predicted decision pairs, the F1 score for each decision type predicted by the decision, and the BLEU-4, CIDEr, and METEOR explained by the prediction. For Apollo, manually collected scenes on Town05 will be played back as input to the model in Table 3. The corresponding model state and output at each timestamp of the replay are saved as predictions for metric calculations. For other methods, we give them corresponding images as input and appropriate prompts. By comparing model predictions to our manually collected ground truth, accuracy reveals the correctness of decisions and similarity to human behavior, and F1 scores demonstrate decision-making ability for each path and speed decision. DriveMLM achieved the highest accuracy overall, surpassing LLaVA with an accuracy of 40.97%. Compared to the Apollo baseline, DriveMLM achieves a higher F1 score, indicating that it outperforms rule-based state machines more effectively in solving various road situations. LLaVA, InstructionBLIP, and our proposed DriveMLM can output decision explanations in the form of questions and answers. In terms of BLEU-4, CIDEr and METEOR, DriveMLM can achieve the highest performance, indicating that DriveMLM can make the most reasonable explanation for decisions.
Ablation experiment
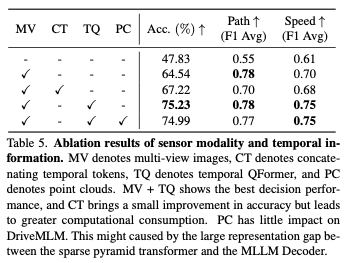
Sensor modality: Table 5 shows the impact of input sensor modality on DriveMLM The results of different impacts. Multi-view (MV) images bring significant performance improvements in both path and speed F1 scores, with an accuracy increase of 18.19%. Compared to directly connecting temporal tokens, Temporal QFormer achieves a 7.4% greater improvement while ensuring multimodal decision-making capabilities, resulting in an average F1 score improvement of 0.05 for speed decisions. Point clouds do not show the ability to enhance performance.
Case Study and Visualization
Human-computer interaction: Figure 4 provides how to achieve it through human instructions Example of vehicle control. The control process includes analyzing road conditions, making decision choices and providing explanatory statements. When given the same "overtaking" command, DriveMLM showed different responses based on its analysis of the current traffic situation. In situations where the right lane is occupied and the left lane is available, the system chooses to overtake from the left. However, in situations where a given instruction could pose a hazard, such as when all lanes are occupied, DriveMLM will choose not to perform an overtaking maneuver and react appropriately. In this case, DriveMLM is the interface for human-vehicle interaction, which evaluates the reasonableness of instructions based on traffic dynamics and ensures that they comply with predefined rules before finally selecting a course of action.

Performance in real scenarios: We apply DriveMLM on the nuScenes dataset to test the zero-shot performance of the developed driving system. We annotated 6019 frames on the validation set and achieved a zero-shot performance of 0.395 for decision accuracy. Figure 5 shows the results of two real driving scenarios, demonstrating the versatility of DriveMLM.

Conclusion
In this work, we propose DriveMLM, a new framework that utilizes large language models (LLM) for autonomous driving (AD). DriveMLM can implement closed-loop AD in a realistic simulation environment by modeling the behavioral planning module of a modular AD system using multimodal LLM (MLLM). DriveMLM can also generate natural language explanations for its driving decisions, which can increase the transparency and trustworthiness of AD systems. We have shown that DriveMLM outperforms the Apollo benchmark on the CARLA Town05 Long benchmark. We believe that our work can inspire more research on the integration of LLM and AD.
Open source link: https://github.com/OpenGVLab/DriveMLM

Original link: https://mp.weixin.qq.com/s/tQeERCbpD9H8oY8EvpZsDA
The above is the detailed content of Go all out to close the loop! DriveMLM: Perfectly combine LLM with autonomous driving behavior planning!. For more information, please follow other related articles on the PHP Chinese website!