
Home >Technology peripherals >AI >Introducing a new GIF framework: Following the example of humans, a new paradigm for data set amplification has arrived
Introducing a new GIF framework: Following the example of humans, a new paradigm for data set amplification has arrived

- PHPzforward
- 2023-12-14 21:49:271315browse

- ## Paper link: https://browse.arxiv.org/pdf/2211.13976.pdf
- GitHub: https://github.com/Vanint/DatasetExpansion
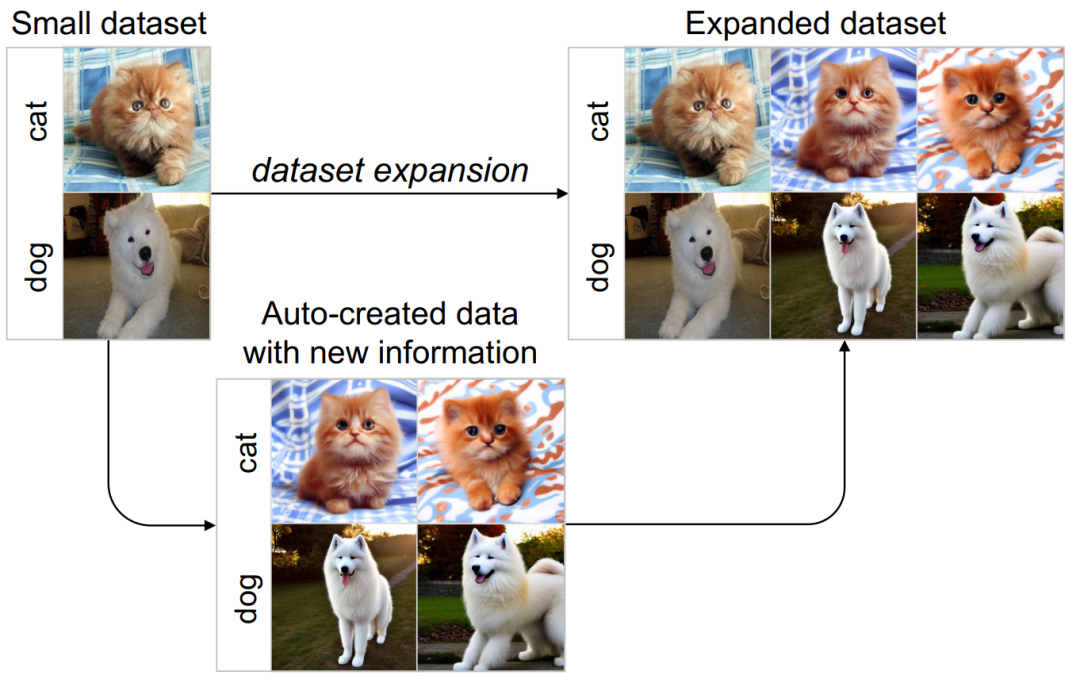
As we all know, the performance of deep neural networks depends heavily on training data The quantity and quality make it difficult for deep learning to be widely applied to small data tasks. For example, in small data application scenarios in medical and other fields, manually collecting and labeling large-scale data sets is often time-consuming and laborious. To address this data scarcity problem and minimize data collection costs, this paper explores a new paradigm of data set augmentation, which aims to automatically generate new data to expand the small data set of the target task into a larger and more informative one. Big data sets. These augmented datasets are dedicated to improving the performance and generalization capabilities of the model and can be used to train different network structures
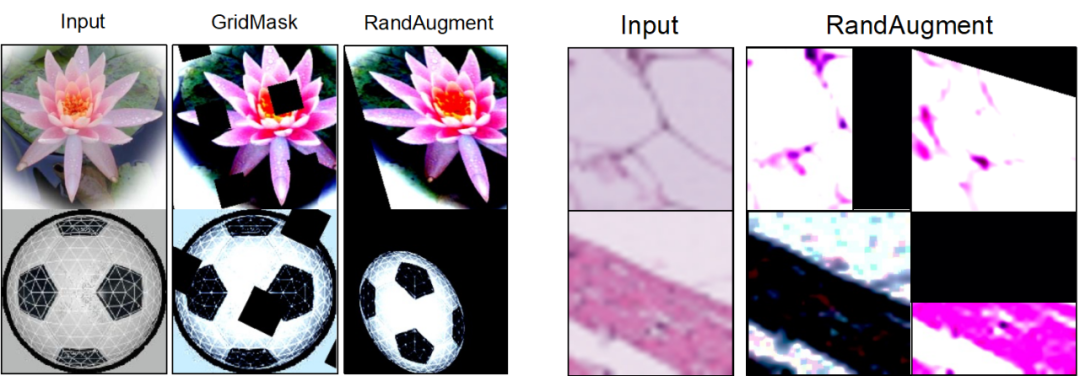
This work It was found that simply using existing methods cannot expand the data set well. (1) Random data enhancement mainly changes the surface visual characteristics of the picture, but cannot create pictures with new object content (the lotus in the picture below is still the same, no new lotus is generated), so the amount of information introduced is limited. What's more serious is that random data enhancement may crop the lesion (change) position of the medical image, resulting in the reduction of important information of the sample and even the generation of noisy data. (2) Directly using pre-trained generative (diffusion) models for data set amplification cannot well improve the performance of the model on the target task. This is because the pre-training data of these generative models often have large distribution differences with the target data, which results in a certain distribution and category gap between the data they generate and the target task, and it is impossible to ensure that the generated samples have the correct category. labels and useful for model training.
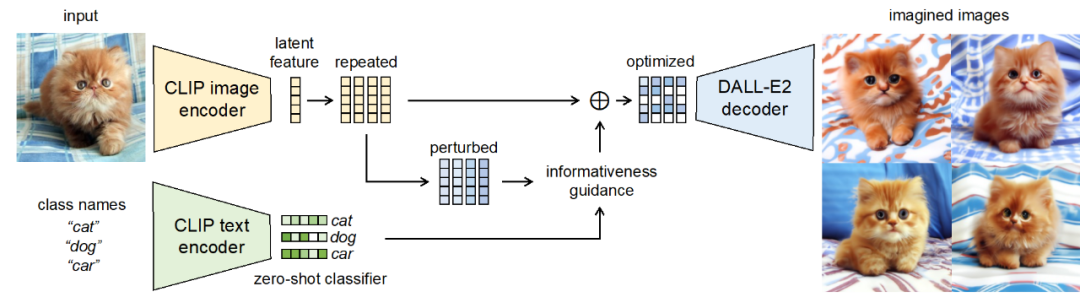
#To achieve more efficient data set augmentation, researchers have explored human associative learning. When humans have prior knowledge of an object, they can easily imagine different variations of the object, such as variations of the dog in different types, colors, shapes, or backgrounds in the picture below. This process of imaginative learning is very instructive for dataset amplification because it goes beyond simply perturbing the appearance of the animals in the picture, but applies rich prior knowledge to create variant pictures with new information.
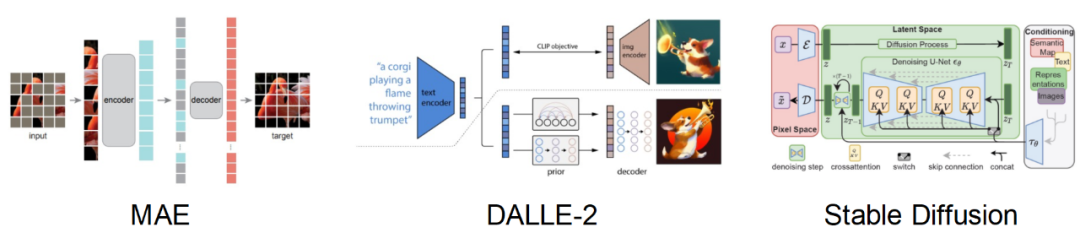
#However, we cannot directly model humans as a priori models for data imagination. Fortunately, recent generative models (such as Stable Diffusion, DALL-E2) have demonstrated a powerful ability to fit the distribution of large-scale data sets, and can generate rich and realistic images. This inspired this paper to use pre-trained generative models as prior models, leveraging their strong prior knowledge to perform efficient data association and amplification on small data sets.
Based on the above ideas, this work proposes a new Guided Imagination Framework (GIF). This method can effectively improve the classification performance and generalization ability of deep neural networks on natural and medical image tasks, and greatly reduce the huge costs caused by manual data collection and annotation. At the same time, the expanded data set also helps promote transfer learning of the model and alleviate the long-tail problem.
Next let’s see how this new paradigm of data set amplification is designed.
Method
Challenges and guiding standards for data set amplification There are two methods for designing data set amplification. Key challenges: (1) How to make the generated samples have the correct category labels? (2) How to ensure that the generated samples contain new information to promote model training? To address these two challenges, this work discovered two amplification guiding criteria through extensive experiments: (1) category-consistent information enhancement; (2) sample diversity improvement.

Methodological Framework Based on the discovered amplification guiding criteria, this work proposes guided imagination Amplified frame (GIF). For each input seed sample x, GIF first uses the feature extractor of the prior generative model to extract the sample feature f, and performs noise perturbation on the feature: 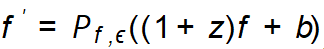 . The simplest way to set the noise (z, b) is to use Gaussian random noise, but it cannot ensure that the generated samples have the correct class label and brings more information. Therefore, for efficient dataset amplification, GIF optimizes noise perturbations based on its discovered amplification guideline, i.e.
. The simplest way to set the noise (z, b) is to use Gaussian random noise, but it cannot ensure that the generated samples have the correct class label and brings more information. Therefore, for efficient dataset amplification, GIF optimizes noise perturbations based on its discovered amplification guideline, i.e. 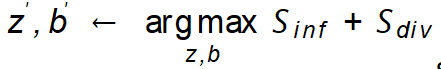 .
.
The amplification guidance standards used are implemented as follows. Class-consistent information quantity index: 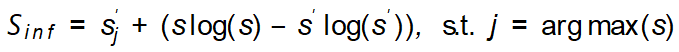 ; sample diversity index:
; sample diversity index: 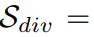
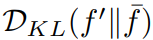 . By maximizing these two indicators, GIF can effectively optimize noise perturbation, thereby generating samples that maintain category consistency and bring greater information content.
. By maximizing these two indicators, GIF can effectively optimize noise perturbation, thereby generating samples that maintain category consistency and bring greater information content.
Experiment
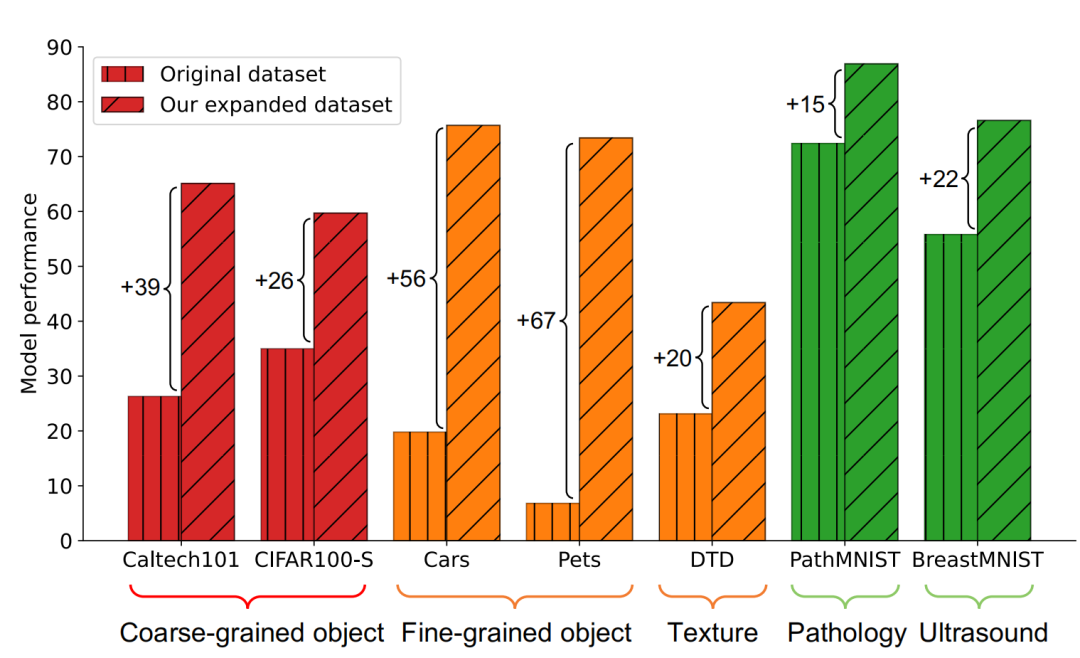
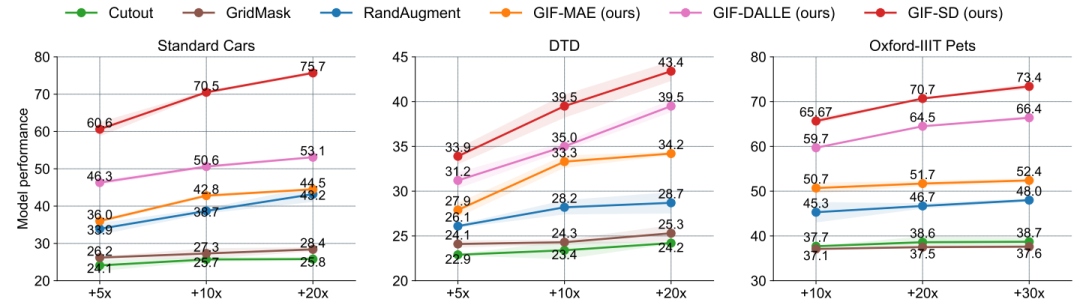
Amplification effectiveness GIF has stronger amplification effectiveness : GIF-SD improves the classification accuracy by an average of 36.9% on 6 natural datasets, and improves the classification accuracy by an average of 13.5% on 3 medical datasets.
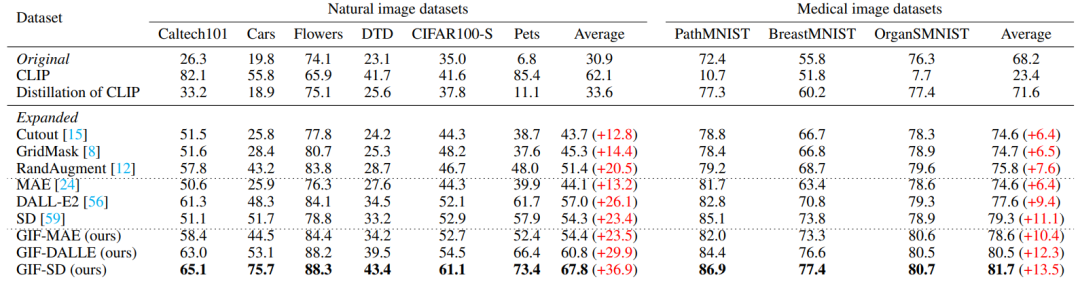
Amplification efficiency GIF has stronger amplification efficiency: in Cars and DTD On the data set, the effect of using GIF-SD for 5-fold amplification even exceeds the effect of using random data augmentation for 20-fold amplification.
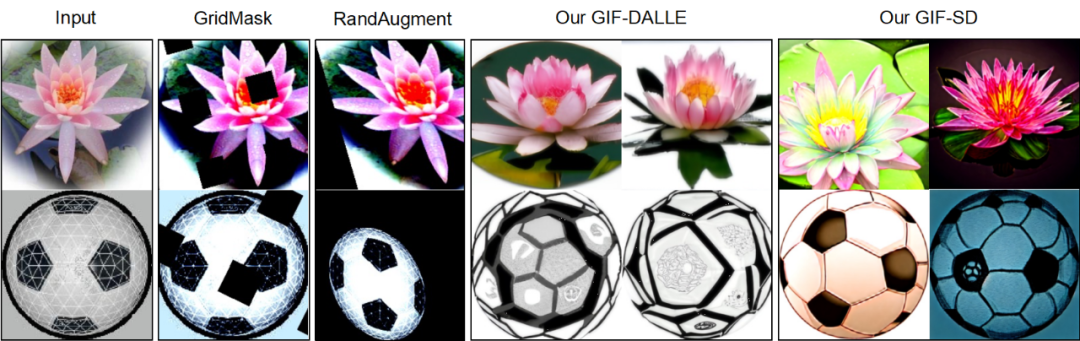
Visualization results Existing data augmentation methods cannot generate new image content, and GIF Can better generate samples with new content.
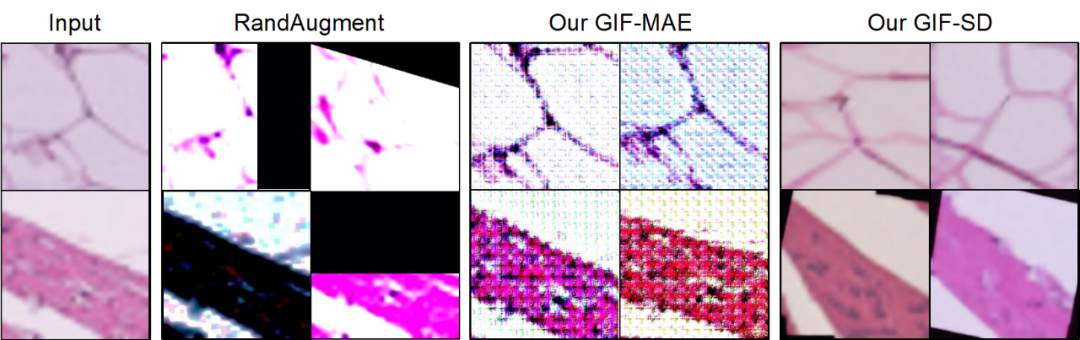
Existing enhancement methods may cut the location of lesions in medical images, resulting in reduced sample information and noise, while GIF can be better preserved Their category semantics
Computation and time cost Compared with manual data collection and annotation, GIFs can significantly reduce the time and cost of data set augmentation.

Versatility of amplified data Once amplified, these data sets can be directly used to train a variety of different Neural network model structure.

Improve model generalization ability GIF helps to improve the model’s out-of-distribution generalization performance (OOD generalization).

Alleviate the long tail problem GIF helps alleviate the long tail problem.

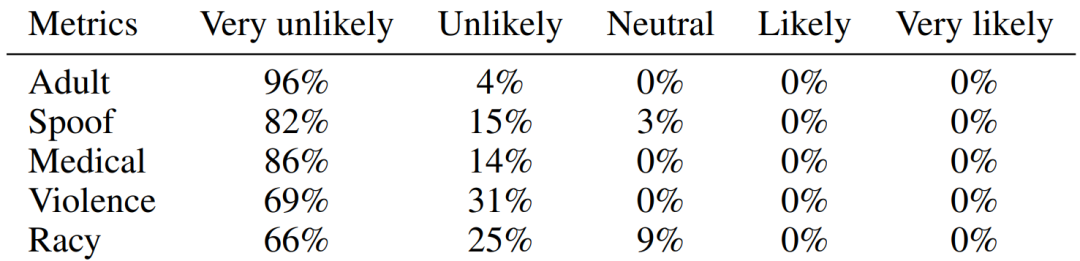
Safety Check The images generated by GIF are safe and harmless.
Based on the above experimental results, we have reason to believe that by simulating human analogy and imagination learning, the method designed in this paper can effectively amplify Small data sets, thereby improving the implementation and application of deep neural networks in small data task scenarios.
The above is the detailed content of Introducing a new GIF framework: Following the example of humans, a new paradigm for data set amplification has arrived. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- The difference between has and with in Laravel association model (detailed introduction)
- How to calculate css box model size
- What data model do most database management systems currently use?
- What does the ieee802 standard divide the local area network hierarchical model into
- There are hidden clues in the GPT-4 paper: GPT-5 may complete training, and OpenAI will approach AGI within two years