

 Technology peripheralsAIComplete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%
Technology peripheralsAIComplete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%
In order to deal with the problem of insufficient visual information extraction in multi-modal large language models, researchers from Harbin Institute of Technology (Shenzhen) proposed a double-layer knowledge-enhanced multi-modal large language model-JiuTian- LION).

The content that needs to be rewritten is: Paper link: https://arxiv.org/abs/2311.11860
GitHub: https://github.com/rshaojimmy/JiuTian
Project homepage: https://rshaojimmy.github.io/Projects/JiuTian-LION
Compared with existing work, Jiutian analyzed the internal conflicts between image-level understanding tasks and regional-level positioning tasks for the first time, and proposed a segmented instruction fine-tuning strategy and a hybrid adapter to achieve both Mutual promotion of tasks.
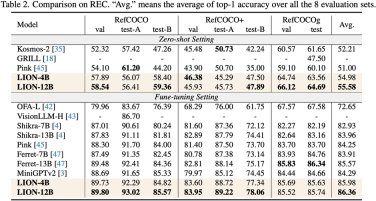
By injecting fine-grained spatial perception and high-level semantic visual knowledge, Jiutian has achieved significant performance improvements in 17 visual language tasks including image description, visual problems, and visual localization. (For example, up to 5% performance improvement on Visual Spatial Reasoning). It has reached the international leading level in 13 of the evaluation tasks. The performance comparison is shown in Figure 1.

Figure 1: Compared with other MLLMs, Jiutian has achieved optimal performance on most tasks.
九天JiuTian-LION
By giving large language models (LLMs) multimodal awareness capabilities, some work has begun to generate multimodal large language models (MLLMs), And has made breakthrough progress in many visual language tasks. However, existing MLLMs mainly use visual encoders pre-trained on image-text pairs, such as CLIP-ViT
. The main task of these visual encoders is to learn coarse-grained images at the image level. Text modalities are aligned, but they lack comprehensive visual perception and information extraction capabilities for fine-grained visual understanding
To a large extent, this visual information extraction and understanding are insufficient Insufficient problems will lead to multiple defects in MLLMs such as visual localization bias, insufficient spatial reasoning, and object hallucination, as shown in Figure 2

##Please Reference Figure 2: JiuTian-LION is a multi-modal large language model enhanced with double-layer visual knowledge
JiuTian-LION is compared with existing multi-modal large language Models (MLLMs), by injecting fine-grained spatial awareness visual knowledge and high-level semantic visual evidence, effectively improve the visual understanding capabilities of MLLMs, generate more accurate text responses, and reduce the hallucination phenomenon of MLLMs
Double-layer visual knowledge enhanced multi-modal large language model-JiuTian-LION
In order to solve the problem of MLLMs in visual information extraction and understanding In order to solve the shortcomings in this aspect, the researchers proposed a two-layer visual knowledge enhanced MLLMs method, called JiuTian-LION. The specific method framework is shown in Figure 3
This method mainly enhances MLLMs from two aspects, progressively integrating fine-grained Spatial-aware Visual knowledge (Progressive Incorporation of Fine-grained Spatial-aware Visual knowledge) and Soft Prompting of High-level Semantic Visual Evidence under soft prompts.
Specifically, the researchers proposed a segmented instruction fine-tuning strategy to resolve the internal conflict between the image-level understanding task and the region-level localization task. They gradually inject fine-grained spatial awareness knowledge into MLLMs. At the same time, they added image labels as high-level semantic visual evidence to MLLMs, and used soft hinting methods to mitigate the possible negative impact of incorrect labels
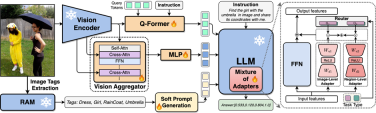
This work uses a segmented training strategy to first learn image-level understanding and regional-level positioning tasks based on Q-Former and Vision Aggregator-MLP branches respectively, and then utilizes a hybrid adapter with a routing mechanism in the final training stage. To dynamically integrate the performance of different branches of knowledge improvement models on two tasks. This work also extracts image tags as high-level semantic visual evidence through RAM, and then proposes a soft prompt method to improve the effect of high-level semantic injection Progressive fusion of fine-grained spatial awareness visual knowledge When directly combining image-level understanding tasks (including image description and visual question answering) with regional-level localization tasks (including instructions Expression understanding, instruction expression generation, etc.) When performing single-stage hybrid training, MLLMs will encounter internal conflicts between the two tasks and thus cannot achieve good overall performance on all tasks. Researchers believe that this internal conflict is mainly caused by two issues. The first problem is the lack of regional-level modal alignment pre-training. Currently, most MLLMs with regional-level positioning capabilities first use a large amount of relevant data for pre-training. Otherwise, it will be difficult to use image-level modal alignment based on limited training resources. Visual feature adaptation to region-level tasks. Another problem is the difference in input and output patterns between image-level understanding tasks and region-level localization tasks. The latter requires the model to additionally understand specific short sentences about object coordinates (started with As shown in Figure 4, the researchers split the single-stage instruction fine-tuning process into three stages: Using ViT, Q-Former and image-level adapters to learn image-level understanding tasks of global visual knowledge; use Vision Aggregator, MLP, and regional-level adapters to learn regional-level positioning tasks of fine-grained space-aware visual knowledge; propose a hybrid adapter with a routing mechanism to dynamically integrate different branches Visual knowledge learned at different granularities. Table 3 shows the performance advantages of the segmented instruction fine-tuning strategy over single-stage training Figure 4: Segmented instruction fine-tuning strategy For high-level semantic visual evidence injected under soft prompts, rewriting is required Researchers propose using image labels as an effective supplement to high-level semantic visual evidence to further enhance the global visual perception understanding ability of MLLMs Specific For example, first extract the image tag through RAM, and then use the specific command template "According to Coupled with the specific phrase "use or partially use" in the template, the soft hint vector can guide the model to mitigate the potential negative impact of incorrect labels. The researchers included image captioning (image captioning), visual question answering (VQA), and directed expression understanding (REC) It was evaluated on 17 task benchmark sets. The experimental results show that Jiutian has reached the international leading level in 13 evaluation sets. In particular, compared with InstructBLIP and Shikra, Jiutian has achieved comprehensive and consistent performance improvements in image-level understanding tasks and region-level positioning tasks respectively, and can achieve up to 5% improvement in Visual Spatial Reasoning (VSR) tasks. As can be seen from Figure 5, there are differences in the abilities of Jiutian and other MLLMs in different visual language multi-modal tasks, indicating that Jiutian performs better in fine-grained visual understanding and visuospatial reasoning capabilities. And be able to output text responses with less illusion The rewritten content is: The fifth picture shows the response to the Nine-day Large Model, InstructBLIP and Qualitative analysis of Shikra’s ability differences Figure 6 shows through sample analysis that the Jiutian model has excellent understanding and recognition capabilities in both image-level and regional-level visual language tasks. The sixth picture: Through the analysis of more examples, the capabilities of the Jiutian large model are demonstrated from the perspective of image and regional level visual understanding (1) This work proposes a new multi-modal large language model-Jiutian: enhanced by double-layer visual knowledge Multimodal large language model. (2) This work was evaluated on 17 visual language task benchmark sets including image description, visual question answering and instructional expression understanding, among which 13 evaluation sets reached the current best performance. (3) This work proposes a segmented instruction fine-tuning strategy to resolve the internal conflict between image-level understanding and region-level localization tasks, and implements two Mutual improvement between tasks (4) This work successfully integrates image-level understanding and regional-level positioning tasks to comprehensively understand visual scenes at multiple levels. This comprehensive approach can be used in the future. Visual understanding capabilities are applied to embodied intelligent scenarios to help robots better and more comprehensively identify and understand the current environment and make effective decisions.  form). In order to solve the above problems, researchers proposed a segmented instruction fine-tuning strategy and a hybrid adapter with a routing mechanism.
form). In order to solve the above problems, researchers proposed a segmented instruction fine-tuning strategy and a hybrid adapter with a routing mechanism. 

Experimental results



Summary
The above is the detailed content of Complete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%. For more information, please follow other related articles on the PHP Chinese website!

 5 Statistical Tests Every Data Scientist Should Know - Analytics VidhyaApr 19, 2025 am 10:27 AM
5 Statistical Tests Every Data Scientist Should Know - Analytics VidhyaApr 19, 2025 am 10:27 AMData Science's Essential Statistical Tests: A Comprehensive Guide Unlocking valuable insights from data is paramount in data science. Mastering statistical tests is fundamental to achieving this. These tests empower data scientists to rigorously val
 How to Perform Computer Vision Tasks with Florence-2 - Analytics VidhyaApr 19, 2025 am 10:21 AM
How to Perform Computer Vision Tasks with Florence-2 - Analytics VidhyaApr 19, 2025 am 10:21 AMIntroduction The introduction of the original transformers paved the way for the current Large Language Models. Similarly, after the introduction of the transformer model, the vision transformer (ViT) was introduced. Like the
 7 Ways to Split Data Using LangChain Text Splitters - Analytics VidhyaApr 19, 2025 am 10:11 AM
7 Ways to Split Data Using LangChain Text Splitters - Analytics VidhyaApr 19, 2025 am 10:11 AMLangChain Text Splitters: Optimizing LLM Input for Efficiency and Accuracy Our previous article covered LangChain's document loaders. However, LLMs have context window size limitations (measured in tokens). Exceeding this limit truncates data, comp
 Free Generative AI Course: Pioneering the Future of InnovationApr 19, 2025 am 10:01 AM
Free Generative AI Course: Pioneering the Future of InnovationApr 19, 2025 am 10:01 AMGenerative AI: Revolutionizing Creativity and Innovation Generative AI is transforming industries by creating text, images, music, and virtual worlds at the touch of a button. Its impact spans video editing, music production, art, entertainment, hea
 Creating a QA Model with Universal Sentence Encoder and WikiQAApr 19, 2025 am 10:00 AM
Creating a QA Model with Universal Sentence Encoder and WikiQAApr 19, 2025 am 10:00 AMHarnessing the Power of Embedding Models for Advanced Question Answering In today's information-rich world, the ability to obtain precise answers instantly is paramount. This article demonstrates building a robust question-answering (QA) model using
 Top 10 Must Read Machine Learning Research PapersApr 19, 2025 am 09:53 AM
Top 10 Must Read Machine Learning Research PapersApr 19, 2025 am 09:53 AMThis article explores ten seminal publications that have revolutionized artificial intelligence (AI) and machine learning (ML). We'll examine recent breakthroughs in neural networks and algorithms, explaining the core concepts driving modern AI. Th
 Top 11 AI Tools to Replace SEO Agencies - Analytics VidhyaApr 19, 2025 am 09:49 AM
Top 11 AI Tools to Replace SEO Agencies - Analytics VidhyaApr 19, 2025 am 09:49 AMAI's Rise in SEO: Top 11 Tools to Outperform SEO Agencies The rapid advancement of AI has profoundly reshaped the SEO landscape. Businesses aiming for top search engine rankings are leveraging AI's power to optimize their online strategies. From au
 Top 10 Free AI Playgrounds For You to Try in 2025 - Analytics VidhyaApr 19, 2025 am 09:45 AM
Top 10 Free AI Playgrounds For You to Try in 2025 - Analytics VidhyaApr 19, 2025 am 09:45 AMExploring the Best Free AI Playgrounds in 2024: A Comprehensive Guide Access to the right tools and platforms is key to learning and innovating in the ever-evolving field of artificial intelligence (AI). AI playgrounds offer a fantastic opportunity


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

Notepad++7.3.1
Easy-to-use and free code editor

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

