


LLM inference on multiple GPUs using the Accelerate library

Large-scale language models (llm) have revolutionized the field of natural language processing. As these models grow in size and complexity, the computational demands of inference also increase significantly. To address this challenge leveraging multiple GPUs becomes critical.

Therefore, this article will perform inference on multiple GPUs simultaneously. The content mainly includes: introducing the Accelerate library, simple methods and working code Examples, and performance benchmarking using multiple GPUs
This article will scale the inference of llama2-7b on multiple GPUs using multiple 3090
Basic Example
We first introduce a simple example to demonstrate multi-GPU "message passing" using Accelerate.
from accelerate import Accelerator from accelerate.utils import gather_object accelerator = Accelerator() # each GPU creates a string message=[ f"Hello this is GPU {accelerator.process_index}" ] # collect the messages from all GPUs messages=gather_object(message) # output the messages only on the main process with accelerator.print() accelerator.print(messages)
The output is as follows:
['Hello this is GPU 0', 'Hello this is GPU 1', 'Hello this is GPU 2', 'Hello this is GPU 3', 'Hello this is GPU 4']
Multi-GPU inference
The following is a simple, Non-batch inference methods. The code is very simple, because the Accelerate library has already done a lot of work for us, we can use it directly:
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:# store output of generations in dictresults=dict(outputs=[], num_tokens=0) # have each GPU do inference, prompt by promptfor prompt in prompts:prompt_tokenized=tokenizer(prompt, return_tensors="pt").to("cuda")output_tokenized = model.generate(**prompt_tokenized, max_new_tokens=100)[0] # remove prompt from output output_tokenized=output_tokenized[len(prompt_tokenized["input_ids"][0]):] # store outputs and number of tokens in result{}results["outputs"].append( tokenizer.decode(output_tokenized) )results["num_tokens"] += len(output_tokenized) results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time {timediff}, total tokens {num_tokens}, total prompts {len(prompts_all)}")
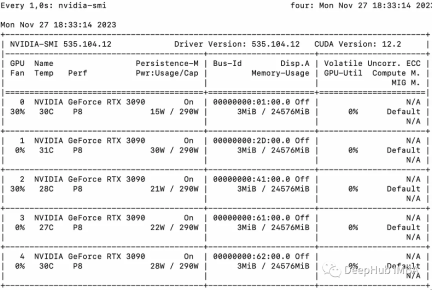
Using multiple GPUs will cause some communication overhead: the performance is at 4 GPUs increases linearly and then levels off in this particular setup. Of course the performance here depends on many parameters like model size and quantization, hint length, number of generated tokens and sampling strategy, so we only discuss the general case
1 GPU: 44 tokens/second, time: 225.5s
2 GPUs: 88 tokens processed per second, total time 112.9 seconds
3 GPU: 128 tokens processed per second, total time 77.6 seconds
4 gpu: 137 tokens/second, time: 72.7s
5 GPUs: 119 tokens processed per second, a total of 83.8 seconds required
Batch processing on multiple GPUs
In the real world, we can use batch inference to speed things up. This reduces communication between GPUs and speeds up inference. We only need to add the prepare_prompts function to input a batch of data into the model instead of a single piece of data:
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() def write_pretty_json(file_path, data):import jsonwith open(file_path, "w") as write_file:json.dump(data, write_file, indent=4) # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) tokenizer.pad_token = tokenizer.eos_token # batch, left pad (for inference), and tokenize def prepare_prompts(prompts, tokenizer, batch_size=16):batches=[prompts[i:i + batch_size] for i in range(0, len(prompts), batch_size)]batches_tok=[]tokenizer.padding_side="left" for prompt_batch in batches:batches_tok.append(tokenizer(prompt_batch, return_tensors="pt", padding='longest', truncatinotallow=False, pad_to_multiple_of=8,add_special_tokens=False).to("cuda") )tokenizer.padding_side="right"return batches_tok # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:results=dict(outputs=[], num_tokens=0) # have each GPU do inference in batchesprompt_batches=prepare_prompts(prompts, tokenizer, batch_size=16) for prompts_tokenized in prompt_batches:outputs_tokenized=model.generate(**prompts_tokenized, max_new_tokens=100) # remove prompt from gen. tokensoutputs_tokenized=[ tok_out[len(tok_in):] for tok_in, tok_out in zip(prompts_tokenized["input_ids"], outputs_tokenized) ] # count and decode gen. tokens num_tokens=sum([ len(t) for t in outputs_tokenized ])outputs=tokenizer.batch_decode(outputs_tokenized) # store in results{} to be gathered by accelerateresults["outputs"].extend(outputs)results["num_tokens"] += num_tokens results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time elapsed: {timediff}, num_tokens {num_tokens}")
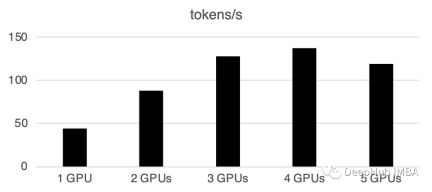
You can see that batch processing will greatly speed up.
What needs to be rewritten is: 1 GPU: 520 tokens/second, time: 19.2 seconds
For two GPUs The computing power is 900 tokens per second, the calculation time is 11.1 seconds
3 gpu: 1205 tokens/second, the time: 8.2s
Four GPUs: 1655 tokens/second, time required: 6.0 seconds
5 GPUs: 1658 tokens/second, time: 6.0 seconds
Summary
As of this article, llama.cpp, ctransformer does not support multi-GPU reasoning, like llama. cpp has a multi-GPU merge in June, but I haven’t seen an official update, so it is determined that multi-GPU is not supported here for the time being. If anyone confirms that it can support multiple GPUs, please leave a message.
huggingface's Accelerate package provides us with a very convenient option for using multiple GPUs. Using multiple GPUs for inference can significantly improve performance, but the cost of communication between GPUs increases with Significantly increases as the number of GPUs increases.
The above is the detailed content of LLM inference on multiple GPUs using the Accelerate library. For more information, please follow other related articles on the PHP Chinese website!

 5 Insights by Satya Nadella and Mark Zuckerberg on Future of AIMay 07, 2025 am 10:35 AM
5 Insights by Satya Nadella and Mark Zuckerberg on Future of AIMay 07, 2025 am 10:35 AMIf you’re an AI enthusiast like me, you have probably had many sleepless nights. It’s challenging to keep up with all AI updates. Last week, a major event took place: Meta’s first-ever LlamaCon. The event started with
 Top 30 AI Agent Interview QuestionsMay 07, 2025 am 10:24 AM
Top 30 AI Agent Interview QuestionsMay 07, 2025 am 10:24 AMAs AI agents become central to modern-day automation and intelligent systems, the demand for professionals who understand their design, deployment, and orchestration is rising rapidly. Whether you’re preparing for a technic
 Cluely.ai: Will This AI Tool Mark the End of Virtual Interviews?May 07, 2025 am 10:11 AM
Cluely.ai: Will This AI Tool Mark the End of Virtual Interviews?May 07, 2025 am 10:11 AMYesterday I saw my roommate preparing for an upcoming interview and she was all over the place – revising topics, practicing codes, and whatnot. Coincidently, I came across an Instagram reel – talking about a tool nam
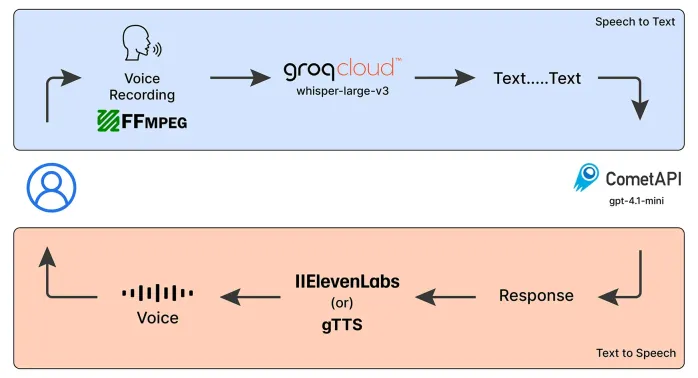 Emergency Operator Voice Chatbot: Empowering AssistanceMay 07, 2025 am 09:48 AM
Emergency Operator Voice Chatbot: Empowering AssistanceMay 07, 2025 am 09:48 AMLanguage models have been rapidly evolving in the world. Now, with Multimodal LLMs taking up the forefront of this Language Models race, it is important to understand how we can leverage the capabilities of these Multimodal model
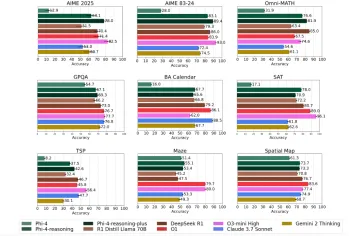 Microsoft's Phi-4 Reasoning Models Explained SimplyMay 07, 2025 am 09:45 AM
Microsoft's Phi-4 Reasoning Models Explained SimplyMay 07, 2025 am 09:45 AMMicrosoft isn’t like OpenAI, Google, and Meta; especially not when it comes to large language models. While other tech giants prefer to launch multiple models almost overwhelming the users with choices; Microsoft launches a few,
 Top 20 Git Commands Every Developer Should Know - Analytics VidhyaMay 07, 2025 am 09:44 AM
Top 20 Git Commands Every Developer Should Know - Analytics VidhyaMay 07, 2025 am 09:44 AMGit can feel like a puzzle until you learn the key moves. In this guide, you’ll find the top 20 Git commands, ordered by how often they are used. Each entry starts with a quick “What it does” summary, followed by an image display
 Git Tutorial for BeginnersMay 07, 2025 am 09:36 AM
Git Tutorial for BeginnersMay 07, 2025 am 09:36 AMIn software development, managing code across multiple contributors can get messy fast. Imagine several people editing the same document at the same time, each adding new ideas, fixing bugs, or tweaking features. Without a struct
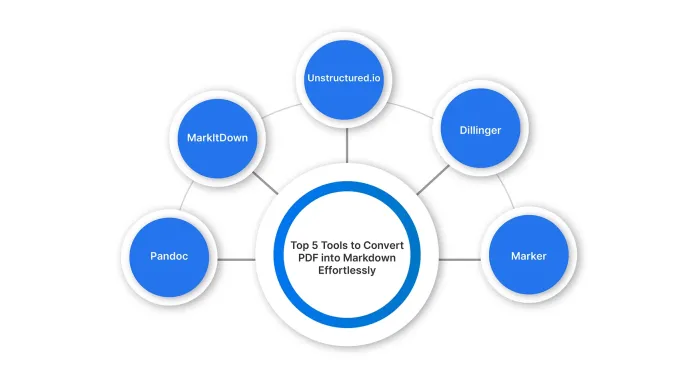 Top 5 PDF to Markdown Converter for Effortless Formatting - Analytics VidhyaMay 07, 2025 am 09:21 AM
Top 5 PDF to Markdown Converter for Effortless Formatting - Analytics VidhyaMay 07, 2025 am 09:21 AMDifferent formats, such as PPTX, DOCX, or PDF, to Markdown converter is an essential tool for content writers, developers, and documentation specialists. Having the right tools makes all the difference when converting any type of


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Dreamweaver CS6
Visual web development tools

Atom editor mac version download
The most popular open source editor

SublimeText3 Mac version
God-level code editing software (SublimeText3)

