
Home >Technology peripherals >AI >There is a 'reversal curse' in large models such as GPT and Llama. How can this bug be alleviated?
There is a 'reversal curse' in large models such as GPT and Llama. How can this bug be alleviated?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-11-18 11:41:41760browse
Researchers from Renmin University of China found that the “reversal curse” encountered by causal language models such as Llama can be attributed to the inherent flaws of next-token prediction causal language models. They also found that the autoregressive fill-in-the-blank training method used by GLM is more robust in dealing with this "reversal curse"
By introducing the bidirectional attention mechanism into the Llama model for fine-tuning, The study achieved relief from Llama's "curse reversal."
The study pointed out that there are many potential problems in the currently popular large-scale model structures and training methods. It is hoped that more researchers can innovate on model structures and pre-training methods to improve the level of intelligence

Paper address: https:/ /arxiv.org/pdf/2311.07468.pdf
Background
In the research of Lukas Berglund et al., it was found that the GPT and Llama models exist A "reversal of the curse." When GPT-4 was asked "Who is Tom Cruise's mother?", GPT-4 was able to give the correct answer "Mary Lee Piffel", but when GPT-4 was asked "Mary Lee "Who is Piffel's son?" When asked, GPT-4 stated that he did not know this person. Perhaps after the alignment, GPT-4 was unwilling to answer such questions due to the protection of the privacy of the characters. However, this kind of "reversal curse" also exists in some knowledge questions and answers that do not involve privacy.
For example, GPT-4 can accurately answer "Yellow Crane is gone and never returns." The next sentence, but as to what is the previous sentence of "White clouds are empty for thousands of years", the model has produced serious illusions

Figure 1: Query What is the next sentence of GPT-4 "Yellow Crane is gone and never returns"? The model correctly answered

Figure 2: Asking GPT-4 "Bai Yunqian" What is the previous sentence of "Zai Kong Youyou"? Model error
Why does the reverse curse come about?
The study by Berglund et al. only tested on Llama and GPT. These two models share common characteristics: (1) they are trained using an unsupervised next token prediction task, and (2) in the decoder-only model, a unidirectional causal attention mechanism (causal attention) is employed
The research perspective on reversing the curse believes that the training objectives of these models have led to the emergence of this problem, and may be a unique problem for models such as Llama and GPT
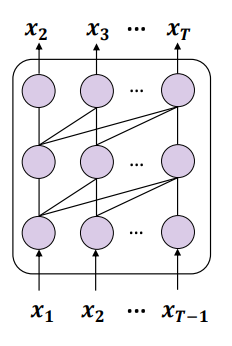
Rewritten content: Figure 3: Schematic diagram showing the use of Next-token prediction (NTP) to train a causal language model
The combination of these two points leads to a problem: if the training data contains entities A and B, and A appears before B, then this model can only optimize the conditional probability p(B|A) of the forward prediction. For the reverse prediction The conditional probability p(A|B) has no guarantees. If the training set is not large enough to fully cover the possible permutations of A and B, the phenomenon of "reversal of the curse" will occur
Of course, there are also many generative language models that do not take the above steps Training paradigm, such as GLM proposed by Tsinghua University, the training method is shown in the following figure:
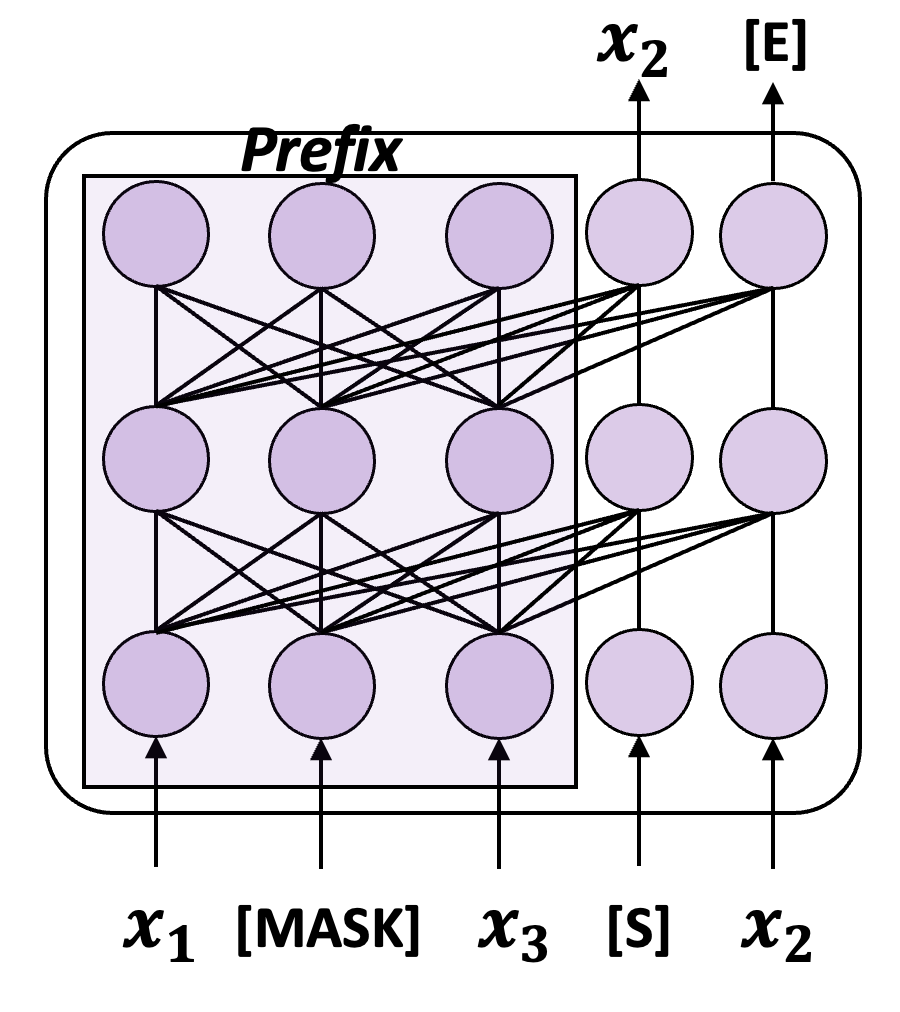
##Figure 4: A simplified version of GLM training diagram
GLM uses the training objective of Autoregressive Blank Infilling (ABI), that is, randomly selects a piece of content from the input to cover, and then autoregressively predicts the piece of content. While the token to be predicted still relies on the "above" via unidirectional attention, the "above" now includes everything before and after that token in the original input, so the ABI implicitly takes into account Reverse dependency
The study conducted an experiment and found that GLM does have the ability to be immune to the "reversal curse" to a certain extent
- This study uses the "Personal Name-Description Question and Answer" data set proposed by Berglund et al. This data set uses GPT-4 to compile several personal names and corresponding descriptions. Both personal names and descriptions are unique. . The data example is shown in the figure below:

The training set is divided into two parts, one part has the name of the person first (NameToDescription), the other part is The description comes first (DescriptionToName), and there are no overlapping names or descriptions in the two parts. The prompt of the test data rewrites the prompt of the training data.
- This data set has four test subtasks:
- NameToDescription (N2D): Pass prompt The name of the person involved in the "NameToDescription" part of the model training set, let the model answer the corresponding description
- DescriptionToName (D2N): By prompting the description involved in the "DescriptionToName" part of the model training set, let The model answers the corresponding person's name
- DescrptionToName-reverse (D2N-reverse): By prompting the person's name involved in the "DescriptionToName" part of the model training set, let the model answer the corresponding description
- NameToDescription-reverse (N2D-reverse): Use the description involved in the "NameToDescription" part of the prompt model training set to let the model answer the corresponding person's name
- This study fine-tuned Llama and GLM on this data set according to their respective pre-training goals (NTP goal for Llama, ABI goal for GLM). After fine-tuning, by testing the accuracy of the model in answering the reversal task, the severity of the “reversal curse” suffered by the model in real scenarios can be qualitatively assessed. Since all names and data are made up, these tasks are largely uninterrupted by the model’s existing knowledge.
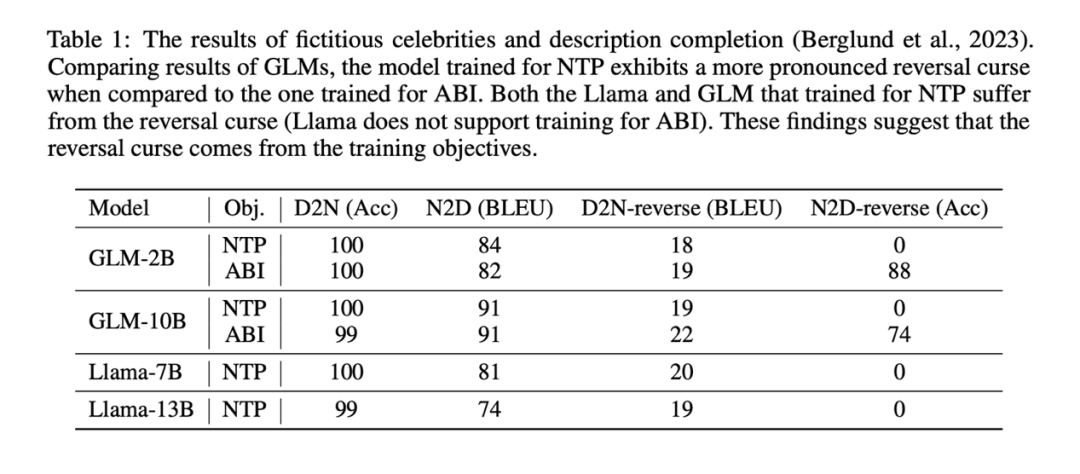 The experimental results show that the Llama model fine-tuned through NTP basically has no ability to answer the reversal task correctly (the accuracy of the NameToDescription-reverse task is 0), while through The ABI fine-tuned GLM model has very high accuracy on the NameToDescrption reversal task.
The experimental results show that the Llama model fine-tuned through NTP basically has no ability to answer the reversal task correctly (the accuracy of the NameToDescription-reverse task is 0), while through The ABI fine-tuned GLM model has very high accuracy on the NameToDescrption reversal task.
For comparison, the study also used the NTP method to fine-tune GLM, and found that the accuracy of GLM in the N2D-reverse task dropped to 0
Perhaps because D2N-reverse (using reverse knowledge to generate a description given a person's name) is much more difficult than N2D-reverse (using reverse knowledge to generate a person's name given a description), GLM-ABI is only A slight improvement.
The main conclusion of the study is not affected: training goals are one cause of the "reversal curse." In causal language models pre-trained with next-token prediction, the "reversal curse" is particularly serious
How to alleviate the reversal curse
Due to The “reversal curse” is an inherent problem caused by the training phase of models such as Llama and GPT. With limited resources, all we can do is to find ways to fine-tune the model on new data and try to avoid the model’s “reversal” on new knowledge as much as possible. Curse” occurs to make fuller use of training data.
Inspired by the GLM training method, this study proposes a training method "Bidirectional Causal language model Optimization" that basically does not introduce new gaps. In this case, Llama can also use the bidirectional attention mechanism for training. In short, there are the following key points:
1. Eliminate the location information of OOD. The RoPE encoding used by Llama adds position information to query and key when calculating attention. The calculation method is as follows:
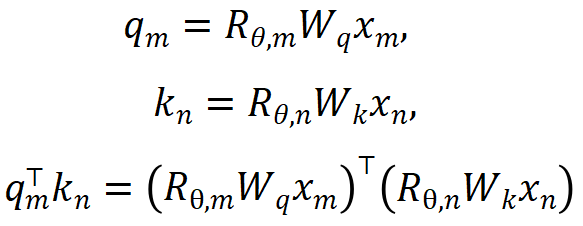
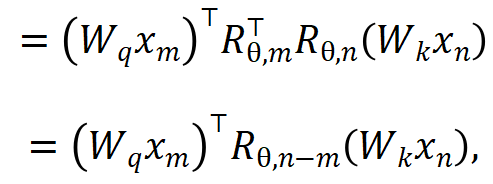 ##
##
where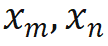 is the input of the m and n positions of the current layer respectively,
is the input of the m and n positions of the current layer respectively, 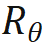 is the rotation matrix used by RoPE, defined as:
is the rotation matrix used by RoPE, defined as:
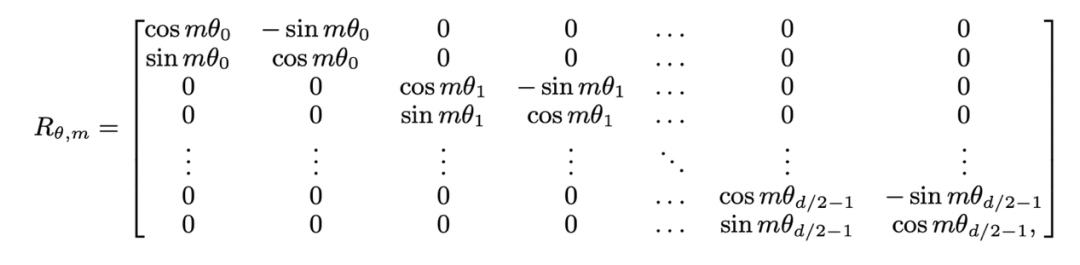
If the causal attention mask of Llama is directly removed, out-of-distribution position information will be introduced. The reason is that during the pre-training process, the query at position m only needs to perform inner product (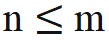 ) with the key at position n. The relative expression of query-key in the inner product calculation of the above formula The distance (n-m) is always non-positive; if the attention mask is removed directly, the query at the m position will do an inner product with the key at the n>m position, causing n-m to become a positive value, which introduces a new model that has not been seen before. location information.
) with the key at position n. The relative expression of query-key in the inner product calculation of the above formula The distance (n-m) is always non-positive; if the attention mask is removed directly, the query at the m position will do an inner product with the key at the n>m position, causing n-m to become a positive value, which introduces a new model that has not been seen before. location information.
The solution proposed by the study is very simple and states:
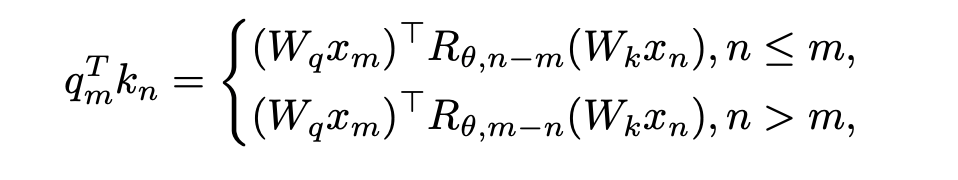
When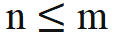 , there is no need to make any modifications to the inner product calculation; when n > m, it is calculated by introducing a new rotation matrix
, there is no need to make any modifications to the inner product calculation; when n > m, it is calculated by introducing a new rotation matrix 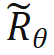 .
. 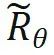 is obtained by taking the inverse of all sin terms in the rotation matrix. In this way, there is
is obtained by taking the inverse of all sin terms in the rotation matrix. In this way, there is 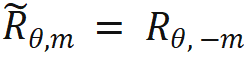 . Then when n > m, there is:
. Then when n > m, there is:
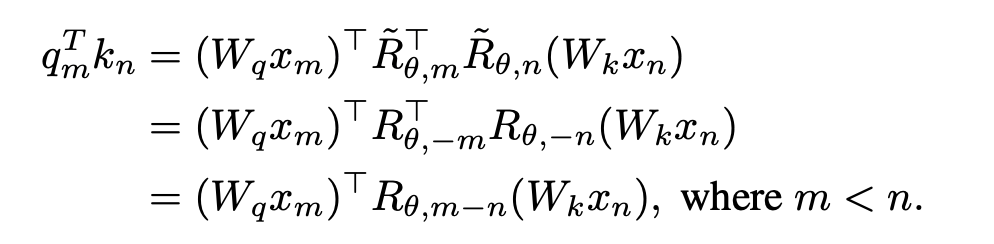
This study divides the calculation of attention score into two parts, and calculates the upper triangle sum according to the above operations. Lower the triangle and finally splice it, thus effectively realizing the attention calculation method specified in this article. The overall operation is shown in the following sub-figure (a):
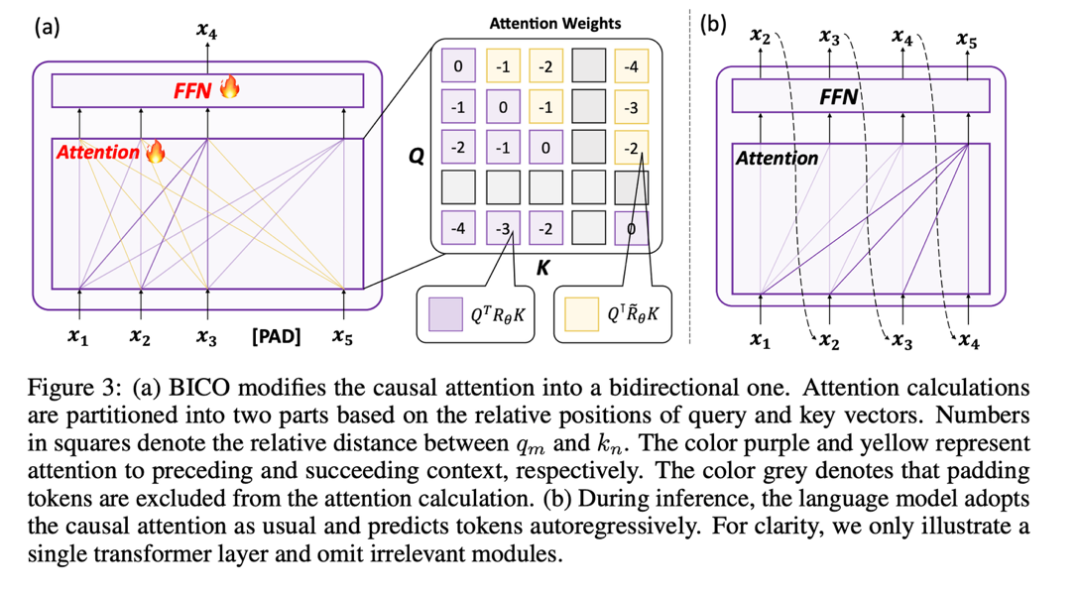
2. Use mask denosing to train
Because the bidirectional attention mechanism is introduced, continuing to use the NTP task for training may cause information leakage, leading to training failure. Therefore, this study uses the method of restoring mask tokens to optimize the model
This study attempts to use BERT to restore the mask token at the i-th position of the input at the i-th position of the output . However, since this prediction method is quite different from the autoregressive prediction used by the model in the testing phase, it did not achieve the expected results
In the end, in order not to introduce a new gap This study uses autoregressive mask denoising, as shown in (a) above: This study restores the mask token input at the i 1th position at the output end.
In addition, since the pre-training vocabulary of the causal language model does not have the [mask] token, if a new token is added during the fine-tuning stage, the model will have to learn this meaningless token, so this study only inputs a placeholder token and ignores the placeholder token in the attention calculation.
When this study fine-tuned Llama, each step randomly selected BICO and ordinary NTP as training targets with equal probability. In the case of the same fine-tuning for ten epochs, on the above-mentioned name description data set, the performance comparison with normal NTP fine-tuning is as follows:
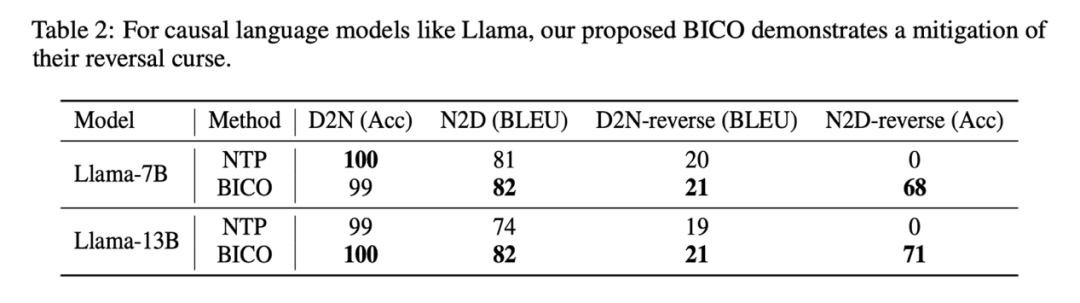
# It can be seen that the method of this study has some relief in reversing the curse. The improvement of the method in this article on D2N-reverse is very small compared with GLM-ABI. The researchers speculate that the reason for this phenomenon is that although the names and corresponding descriptions in the data set are generated by GPT to reduce the interference of pre-training data on the test, the pre-training model has certain common sense understanding capabilities, such as knowing the name of the person. There is usually a one-to-many relationship between the description and the description. Given a person's name, there may be many different descriptions. Therefore, there seems to be some confusion when the model needs to utilize reverse knowledge and generate growth descriptions at the same time
In addition, the focus of this article is to explore the reverse curse phenomenon of the basic model. Further research is still needed to evaluate the model's reversal answering ability in more complex situations, and whether reinforcement learning high-order feedback has an impact on reversing the curse
Some thoughts
Currently, most open source large-scale language models follow the pattern of "causal language model next token prediction". However, there may be more potential issues in this mode similar to Reversal of the Curse. Although these problems can currently be temporarily masked by increasing model size and data volume, they have not really gone away and are still present. When we reach the limit on the road of increasing model size and data volume, whether this "currently good enough" model can truly surpass human intelligence, this research believes that it is very difficult
The The research hopes that more large model manufacturers and qualified researchers can deeply explore the inherent flaws of the current mainstream large language models and innovate in the training paradigm. As the study writes at the end of the text, “Training future models strictly by the book may lead us to fall into a “middle-intelligence trap.””
The above is the detailed content of There is a 'reversal curse' in large models such as GPT and Llama. How can this bug be alleviated?. For more information, please follow other related articles on the PHP Chinese website!