
Home >Technology peripherals >AI >NVIDIA reveals new version of TensorRT-LLM: inference capability increased by 5 times, suitable for local operation on graphics cards above 8GB, and supports OpenAI's Chat API
NVIDIA reveals new version of TensorRT-LLM: inference capability increased by 5 times, suitable for local operation on graphics cards above 8GB, and supports OpenAI's Chat API

- 王林forward
- 2023-11-17 15:06:451217browse
According to news on November 16, the Microsoft Ignite 2023 conference kicked off today. Nvidia executives attended the conference and announced an update to TensorRT-LLM, adding support for the OpenAI Chat API.
NVIDIA released the Tensor RT-LLM open source library in October this year, aiming to provide support for data centers and Windows PCs. The biggest feature of this open source library is that when Windows PC is equipped with NVIDIA's GeForce RTX GPU, TensorRT-LLM can increase the running speed of LLM on Windows PC by four times

NVIDIA announced at today's Ignite 2023 conference that it will update TensorRT-LLM, add OpenAI's Chat API support, and enhance DirectML functions to improve the performance of AI models such as Llama 2 and Stable Diffusion.
TensorRT-LLM can be done locally using NVIDIA’s AI Workbench. Developers can leverage this unified and easy-to-use toolkit to quickly create, test, and customize pre-trained generative AI models and LLMs on a PC or workstation. NVIDIA has also launched an early access registration page for this
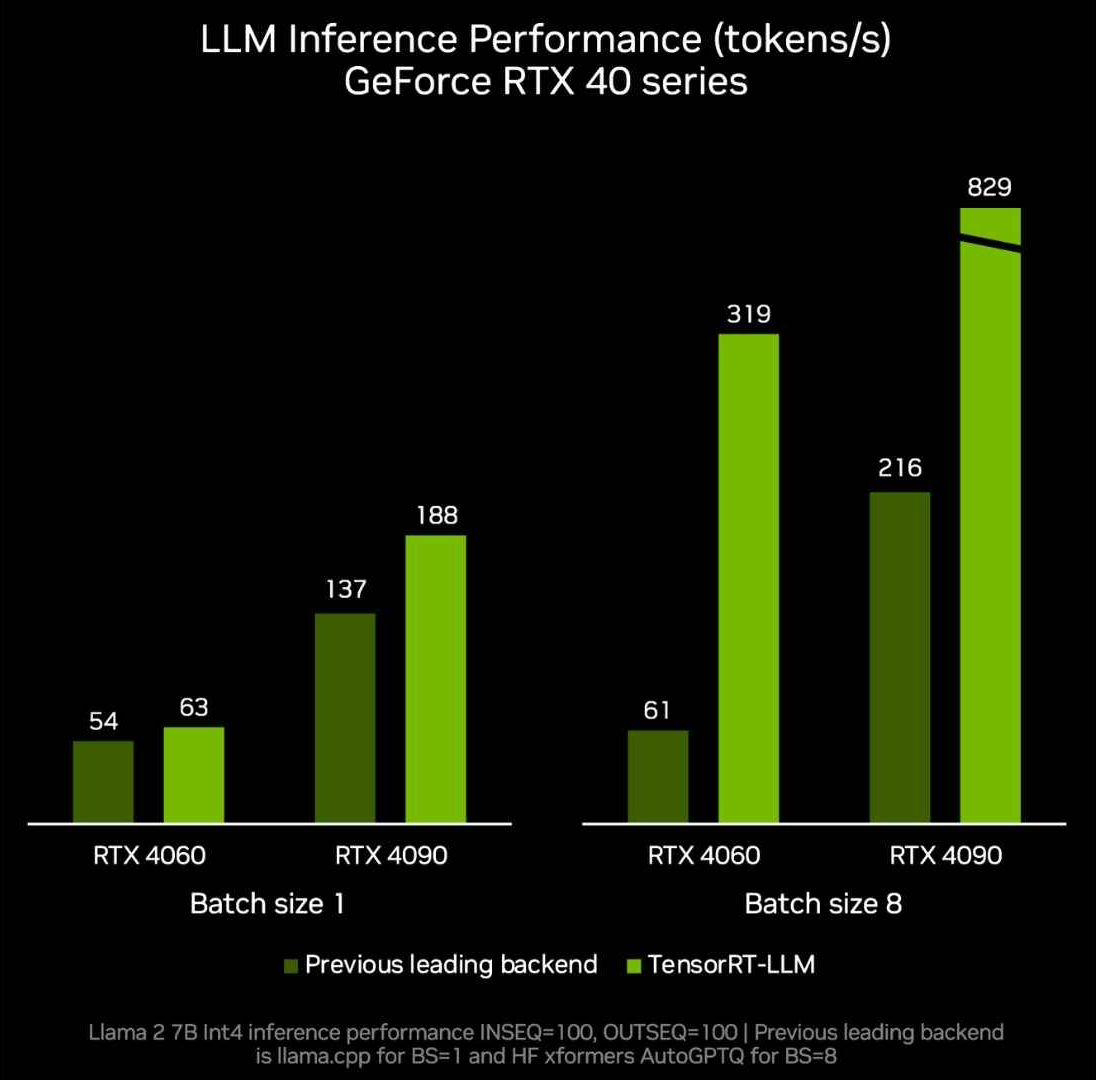
NVIDIA will release the TensorRT-LLM 0.6.0 version update later this month, which will increase the inference performance by 5 times and support Mistral 7B and Nemotron-3 8B and other mainstream LLMs.
Users can run on GeForce RTX 30 Series and 40 Series GPUs with 8GB of video memory and above, and some portable Windows devices can also use fast and accurate native LLM functionality
The above is the detailed content of NVIDIA reveals new version of TensorRT-LLM: inference capability increased by 5 times, suitable for local operation on graphics cards above 8GB, and supports OpenAI's Chat API. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- What does e-mail mean?
- What is the difference between raid 0 1 5 10
- 'Microsoft Teams Premium enhances GPT functionality with OpenAI'
- Beat OpenAI again! Google releases 2 billion parameter universal model to automatically recognize and translate more than 100 languages
- Programmers are in danger! It is said that OpenAI recruits outsourcing troops globally and trains ChatGPT code farmers step by step