
Home >Technology peripherals >AI >Recommendation system for NetEase Cloud Music cold start technology
Recommendation system for NetEase Cloud Music cold start technology

- PHPzforward
- 2023-11-14 08:14:101224browse

1. Problem background: The necessity and importance of cold start modeling
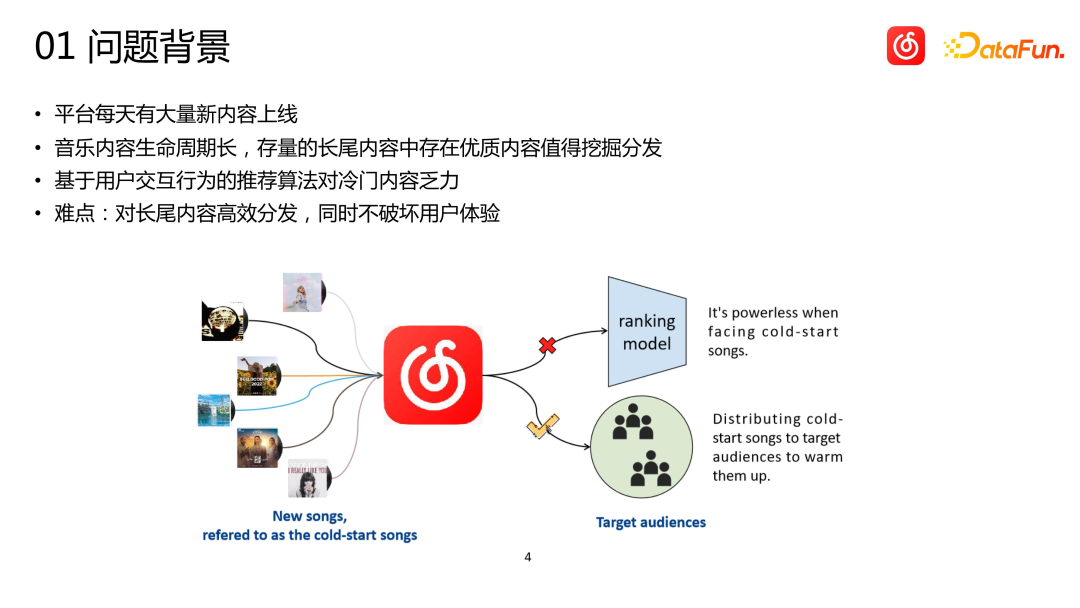
As a content platform, Cloud Music will have a large amount of new content online every day. Although the amount of new content on the cloud music platform is relatively small compared to other platforms such as short videos, the actual amount may far exceed everyone's imagination. At the same time, music content is significantly different from short videos, news, and product recommendations. The life cycle of music spans extremely long periods of time, often measured in years. Some songs may explode after being dormant for months or years, and classic songs may still have strong vitality even after more than ten years. Therefore, for the recommendation system of music platforms, it is more important to discover unpopular and long-tail high-quality content and recommend them to the right users than recommendations in other categories
Unpopular and long-tail items (songs) lack user interaction data. For recommendation systems that mainly rely on behavioral data, it is very difficult to achieve accurate distribution. The ideal situation is to allow a small part of the traffic to be used for exploration and distribution, and to accumulate data during exploration. However, online traffic is very precious, and exploration often easily damages the user experience. As a role that is directly responsible for business indicators, recommendations do not allow us to do too many uncertain explorations for these long-tail items. Therefore, we need to be able to find the potential target users of the item more accurately from the beginning, that is, cold start the item with zero interaction records.
2. Technical solutions: feature selection, model modeling
Next, I will share the technical solutions adopted by Cloud Music.

The core problem is how to find the potential target users of the cold start project. We divide the question into two parts:
What other effective information about the cold start project can be used as features to help us distribute it without the user clicking to play? Here we use the multi-modal features of music
How to use these features to model cold start distribution? To address this, we will share two main modeling solutions:
- I2I modeling: Self-guided contrastive learning enhanced cold start algorithm.
- U2I modeling: Multimodal DSSM user interest boundary modeling.
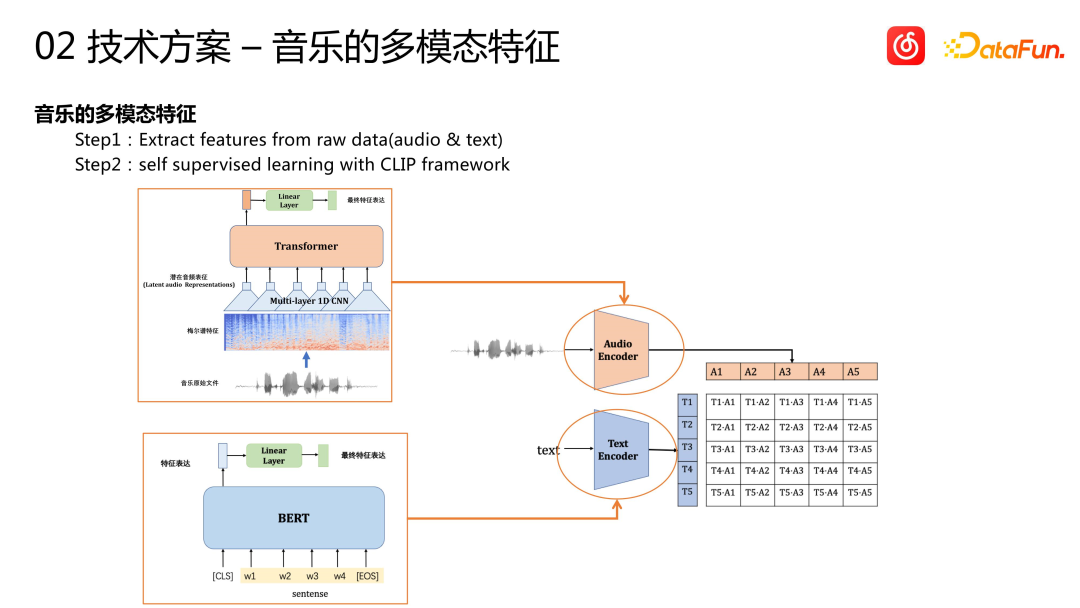
Rewritten into Chinese: The song itself is a kind of multi-modal information. In addition to tag information such as language and genre, the audio and text of the song (including song title and lyrics) contain rich information. Understanding this information and discovering correlations between it and user behavior is key to a successful cold start. Currently, the cloud music platform uses the CLIP framework to achieve multi-modal feature expression. For audio features, some audio signal processing methods are first used to convert them into the form of the video domain, and then sequence models such as Transformer are used for feature extraction and modeling, and finally an audio vector is obtained. For text features, the BERT model is used for feature extraction. Finally, CLIP's self-supervised pre-training framework is used to serialize these features to obtain the multi-modal representation of the song
There are two approaches in the industry for multi-modal modeling. One is to put multi-modal features into the business recommendation model for end-to-end one-stage training, but this method is more expensive. Therefore, we chose a two-stage modeling. First, pre-training modeling is performed, and then these features are input into the recall model or fine ranking model of the downstream business for use.
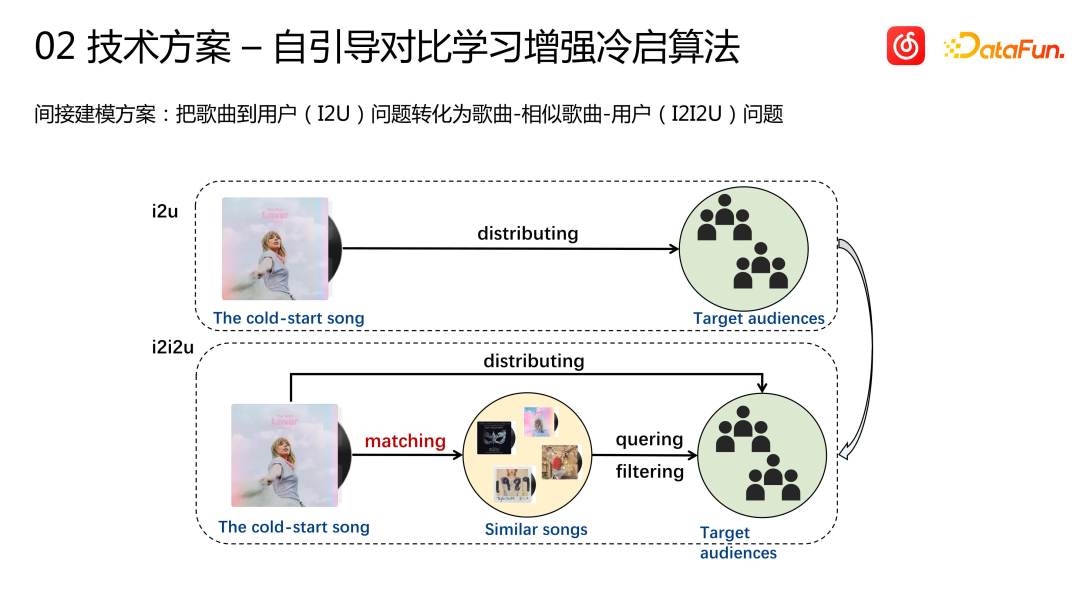
How to distribute a song to users without user interaction? We adopt an indirect modeling solution: transform the song-to-user (I2U) problem into a song-similar song-user (I2I2U) problem, that is, first find songs similar to this cold start song, and then these similar songs are matched with the user There are some historical interaction records, such as collections and other relatively strong signals, and a group of target users can be found. This cold launch song is then distributed to these target users.
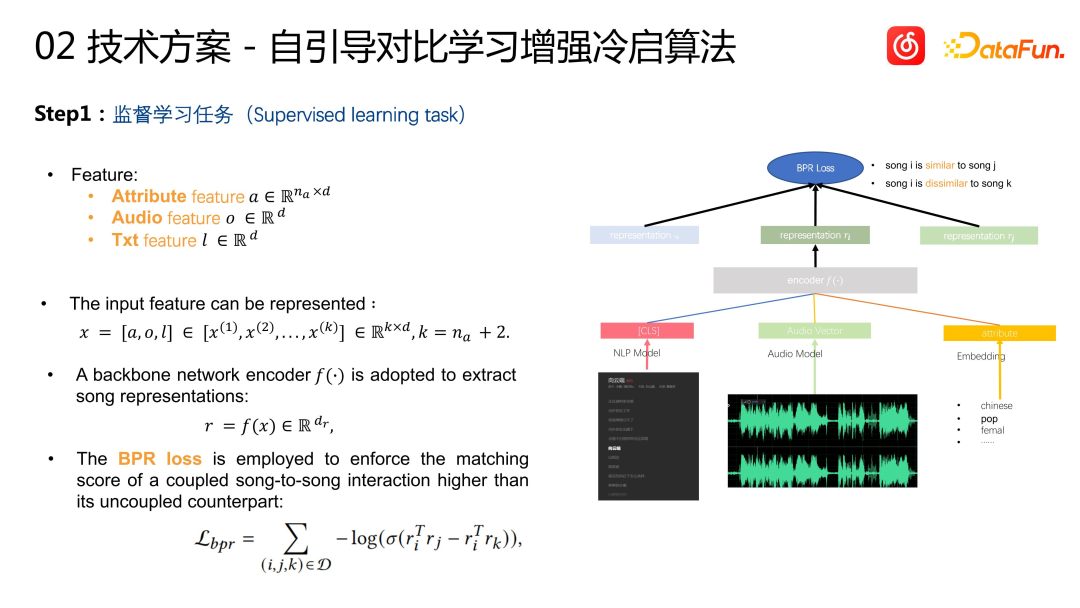
The specific method is as follows. The first step is the task of supervised learning. In terms of song features, in addition to the multi-modal information just mentioned, it also includes song tag information, such as language, genre, etc., to help us carry out personalized modeling. We aggregate all features together, input them into an encoder, and finally output song vectors. The similarity of each song vector can be represented by the vector inner product. The learning goal is the similarity of I2I calculated based on behavior, that is, the similarity of collaborative filtering. We add a layer of post-test verification based on the collaborative filtering data, that is, based on I2I recommendation, the user feedback effect is better. A pair of items is used as a positive sample for learning to ensure the accuracy of the learning target. Negative samples are constructed using global random sampling. The loss function uses BPR loss. This is a very standard CB2CF approach in the recommendation system, which is to learn the similarity of songs in user behavior characteristics based on the content and tag information of the song
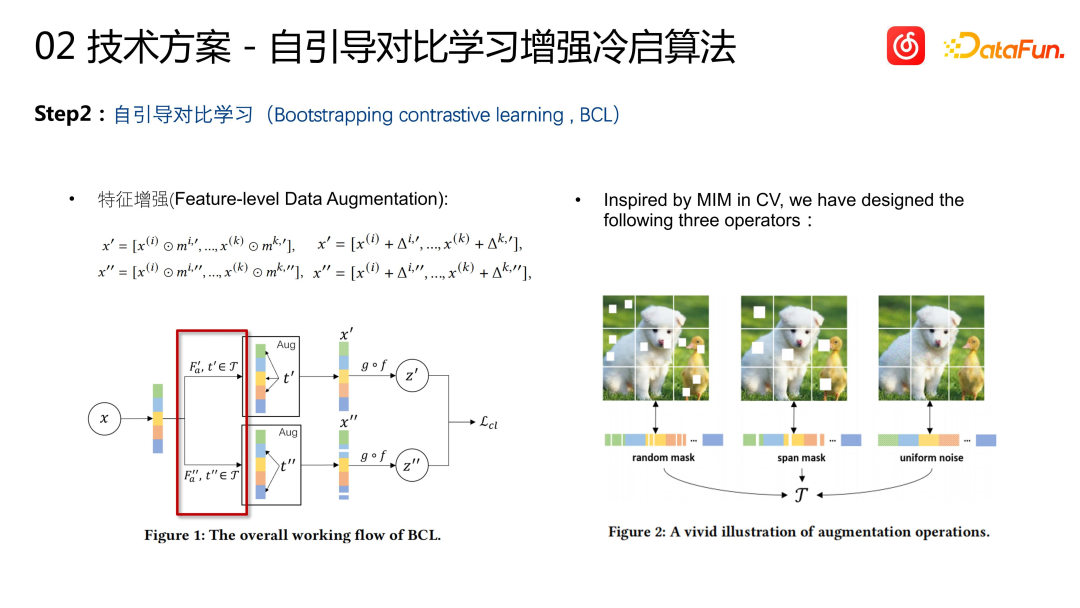
##Based on the above method, we introduced contrastive learning as the second iteration. The reason why we chose to introduce contrastive learning is because in this set of process learning, we still use CF data and need to learn through user interaction behavior. However, such a learning method may lead to a problem, that is, the learned items will have a bias of "more popular items are learned and less popular items are learned". Although our goal is to learn from the multi-modal content of songs to the behavioral similarities of songs, in actual training it is found that there is still a popular and unpopular bias problem
Therefore we introduce A set of comparative learning algorithms is developed to enhance the learning ability of unpopular items. First, we need to have a representation of Item, which is learned through the previous multi-modal encoder. Then, two random transformations are performed on this representation. This is a common practice in CV, which involves randomly masking or adding noise to the features. Two randomly changed representations generated by the same Item are considered similar, and two representations generated by different Items are considered dissimilar. This contrastive learning mechanism is a data enhancement for cold start learning. Through this The method generates contrastive learning knowledge base sample pairs.

On the basis of feature enhancement, we also added an association grouping mechanism
After rewriting The content is as follows: Correlation grouping mechanism: First calculate the correlation between each pair of features, that is, maintain a correlation matrix, and update the matrix during the model training process. The features are then divided into two groups based on the correlation between them. The specific operation is to randomly select a feature, put half of the features most relevant to the feature into one group, and put the remaining ones into another group. Finally, each set of features is randomly transformed to generate sample pairs for contrastive learning. This way, N items within each batch will generate 2N views. A pair of views from the same project is used as a positive sample for contrastive learning, and a pair of views from different projects is used as a negative sample for contrastive learning. The loss of contrastive learning uses information normalized cross entropy (infoNCE) and is combined with the BPR loss of the previous supervised learning part as the final loss function
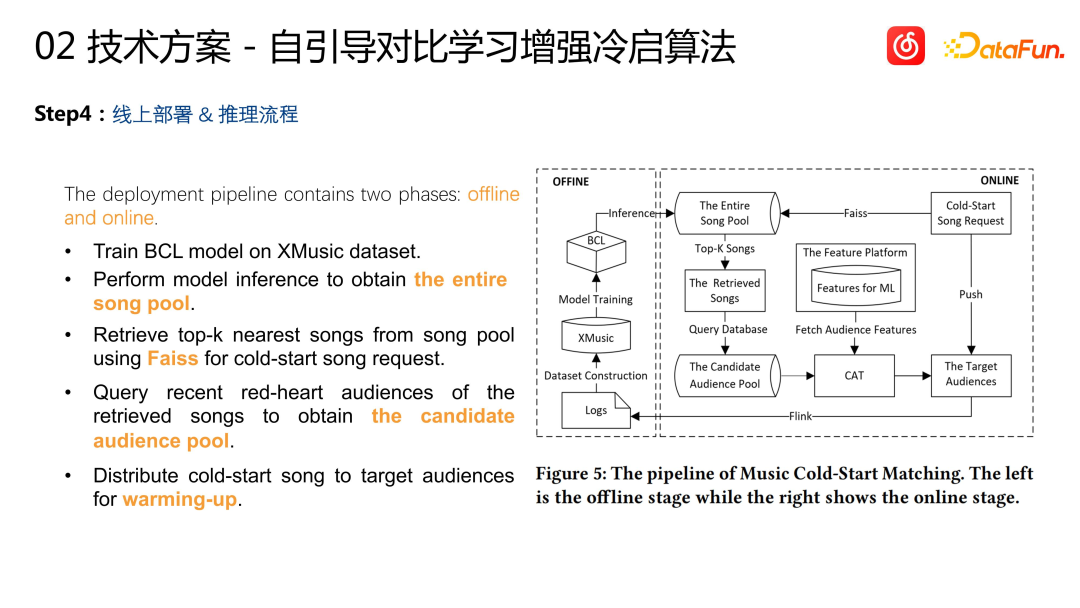
Online deployment and inference process: After offline training is completed, vector indexes are constructed for all existing songs. For a new cold start project, its vector is obtained through model reasoning, and then some of the most similar projects are retrieved from the vector index. These projects are past stock projects, so there is a batch of historical interactions with them. Users (such as playback, collection, etc.) distribute the project that requires cold start to this group of users and complete the cold start of the project
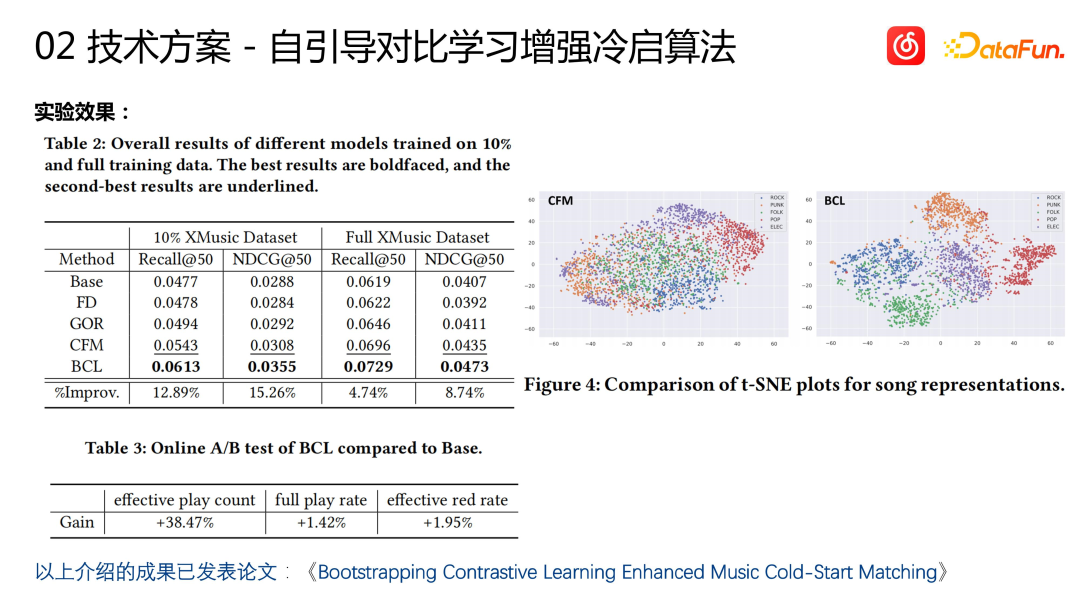
We evaluated the cold start algorithm, including the evaluation of offline and offline indicators, and achieved very good results. As shown in the figure above, the song representation calculated by the cold start model has different effects on different genres. Songs can achieve excellent clustering effects. Some results have been published in public papers (Bootstrapping Contrastive Learning Enhanced Music Cold-Start Matching). Online, while finding more potential target users (38%), the cold start algorithm also achieved improvements in business indicators such as the collection rate (1.95%) and completion rate (1.42%) of cold start items.

Let’s think further:
- In the above I2I2U scheme, No user-side features are used.
- #How to introduce user characteristics to help Item cold start?
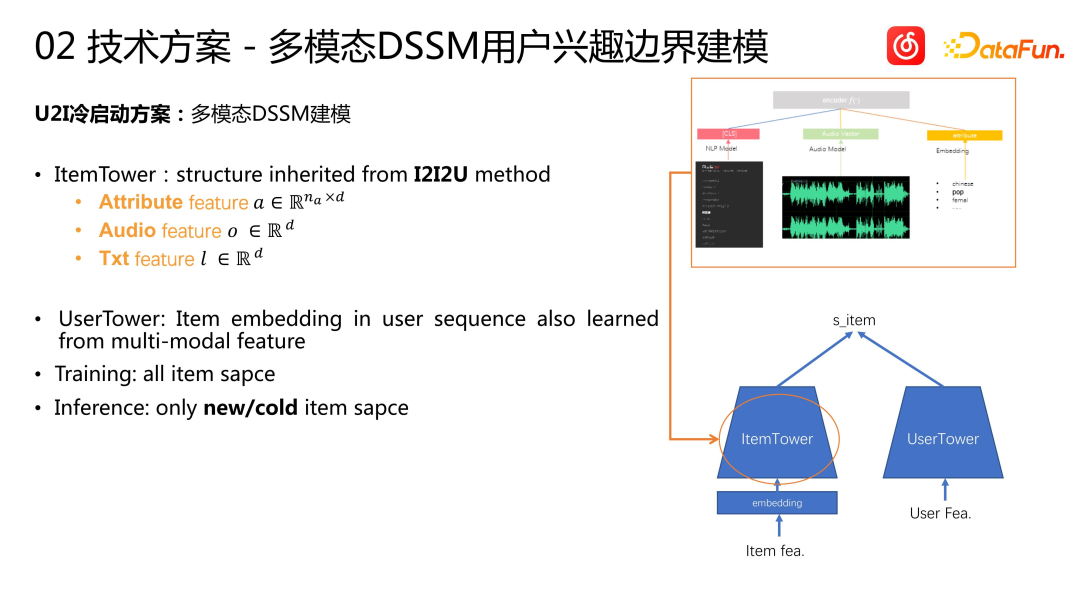
The U2I cold start scheme adopts a multi-modal DSSM modeling approach. The model consists of an ItemTower and a UserTower. We inherited the multimodal features of the previous song into the ItemTower, User Tower, creating a regular User Tower. We conduct multi-modal learning modeling of user sequences. Model training is based on the full item space. Whether it is unpopular or popular songs, they will be used as samples to train the model. When making inferences, only make inferences about the circled new songs or the unpopular song pool. This approach is similar to some previous two-tower solutions: for popular items, build one tower, and for new or unpopular items, build another tower to handle them. However, we handle regular items and cold-started items more independently. We use a regular recall model for regular items, and for unpopular items, we use a specially built DSSM model
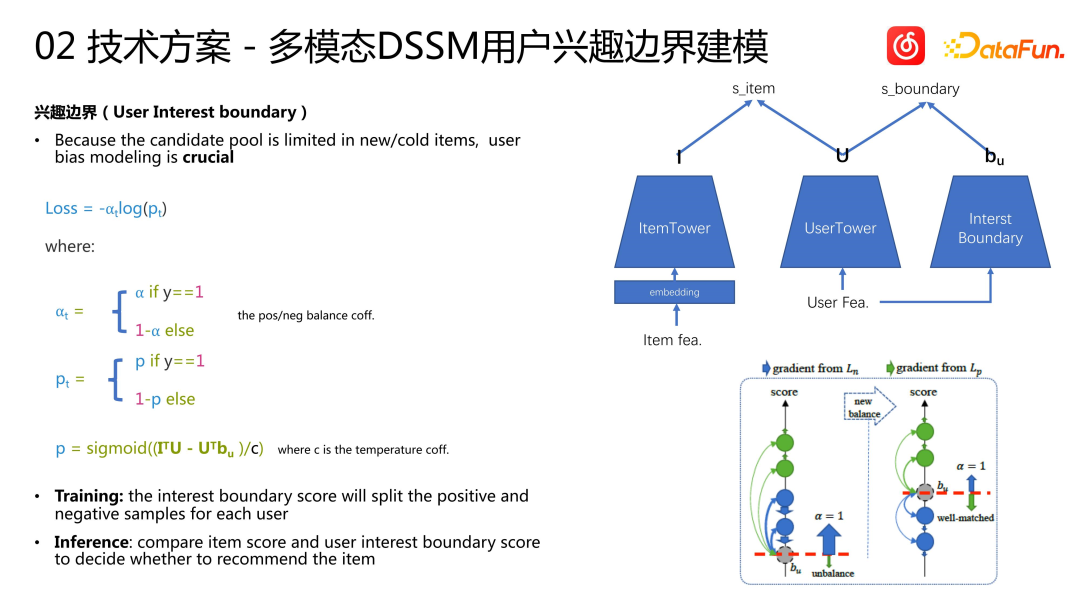
Due to the cold-start DSSM The model is only used to reason about unpopular or new songs. We find it very important to model the user's BIAS because we cannot guarantee that all users like unpopular or new Items. The candidate set itself is a very large pool, and we need to model user Items, because some users may prefer popular Items, and his favorite Items may be missing from the recommendation pool. Therefore, based on traditional methods, we build a tower called "interest boundary" to model users' preferences. The interest boundary is used to separate positive and negative samples. During training, the interest boundary score is used to divide the positive and negative samples of each user; during inference, the item score and the user's interest boundary score are compared to decide whether to recommend the item. During training, we use the interest boundary vector and the user interest vector to perform inner product calculation to obtain the boundary representation vector. Based on the loss in the above figure, traditional two-class cross entropy is used for modeling. Negative samples will raise the user's interest boundary, while positive samples will lower the user's interest boundary. Eventually, an equilibrium state will be reached after training, and the user's interest boundary will separate positive and negative samples. When applied online, we decide whether to recommend unpopular or long-tail items to the user based on the user's interest boundaries.
3. Summary

Finally make a summary. The main work of multi-modal cold start modeling recommended by Cloud Music includes:
- In terms of features, the CLIP pre-training framework is used to model multi-modality .
- Two modeling schemes are used in the modeling scheme, I2I2U indirect modeling and cold start multi-modal DSSM direct modeling.
- In terms of Loss & learning goals, BPR & contrastive learning is introduced on the Item side, and the interest boundary on the User side enhances unpopular Item learning and user learning.
#There are two main directions for future optimization. The first direction is modeling through multi-modal fusion of content and behavioral features. The second direction is to perform full-link optimization on recall and sorting
#
4. Question and Answer Session
Q1: What are the core indicators of music cold start?
A1: We will pay attention to many indicators, the more important of which are collection rate and completion rate. Collection rate = collection PV/played PV, completion rate = complete playback rate PV/Play PV.
Q2: Are multi-modal features end-to-end trained or pre-trained? When generating the comparison view in the second step, what are the specific characteristics of the input x?
A2: Our current solution is to pre-train based on the CLIP framework, and use the multi-modal features obtained from pre-training to support downstream recall and sorting services. Our pre-training process is performed in two stages rather than end-to-end training. Although end-to-end training may be better in theory, it also requires higher machine requirements and costs. Therefore, we choose the pre-training solution, which is also due to cost considerations.
x represents the original features of the song, including the song’s audio, text multi-modal features and language genre and other label features. These features are grouped and subjected to two different random transformations F’a and F’’a to obtain x’ and x’’. f is the encoder, which is also the backbone structure of the model. g is added to a header after the encoder output and is only used for the contrastive learning part
Q3: Two groups of enhancements during contrastive learning training Are the embedding layers and DNN of the tower shared? Why is contrastive learning effective for content cold start? Is it specifically negative sampling for non-cold start content?
A3: The model always has only one encoder, which is one tower, so there is no problem of parameter sharing
About why the unpopular items Helpful, I understand it this way, there is no need to perform additional negative sampling and other work on unpopular items. In fact, simply learning the embedding representation of songs on the basis of supervised learning may lead to bias, because the data learned is collaborative filtering, which will lead to the problem of favoring popular songs, and the final embedding vector will also be biased. By introducing a contrastive learning mechanism and the loss of contrastive learning in the final loss function, the bias of learning collaborative filtering data can be corrected. Therefore, through contrastive learning, the distribution of vectors in space can be improved without requiring additional processing of unpopular items
Q4: Is there multi-objective modeling at the interest boundary? It doesn’t look like much. Can you introduce the two quantities ⍺ and p?
A4: Multi-modal DSSM modeling includes an ItemTower and a UserTower, and then based on the UserTower, we model an additional tower for user characteristics, called interest Boundary tower. Each of these three towers outputs a vector. During training, we perform the inner product of the item vector and the user vector to obtain the item score, and then perform the inner product of the user vector and the user's interest boundary vector to represent the user's interest boundary score. Parameter ⍺ is a conventional sample weighting parameter used to balance the proportion of positive and negative samples contributing to the loss. p is the final score of the item, calculated by subtracting the inner product score of the user vector and the user interest boundary vector from the inner product score of the item vector and the user vector, and calculating the final score through the sigmoid function. During the calculation process, positive samples will increase the inner product score of items and users, and reduce the inner product score of users and user interest boundaries, while negative samples will do the opposite. Ideally, the inner product score of the user and user interest boundaries can differentiate between positive and negative samples. In the online recommendation stage, we use the interest boundary as a reference value to recommend items with higher scores to users, while items with lower scores are not recommended. If a user is only interested in popular items, then ideally, the user's boundary score, that is, the inner product of his user vector and his interest boundary vector, will be very high, even higher than all cold-start item scores. Therefore, some cold-start items will not be recommended to the user
Q5: What is the structural difference between the user tower (userTower) and the interest boundary tower? It seems that the input is the same?
A5: The inputs of the two are indeed the same, and the structures are similar, but the parameters are not shared. The biggest difference is only in the calculation of the loss function. The inner product of the output of the user tower and the output of the item tower is calculated, and the item score is obtained. The inner product of the output of the interest boundary tower and the output of the user tower is calculated, and the result is the boundary score. During training, the two are subtracted and then participate in the calculation of the binary loss function. During inference, the sizes of the two are compared to decide whether to recommend the item to the user
The above is the detailed content of Recommendation system for NetEase Cloud Music cold start technology. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- A brief analysis of methods and techniques for implementing recommendation systems using Golang
- How does Go language implement cloud search and recommendation systems?
- Building a recommendation system using Redis and Python: How to provide personalized recommendations
- The new frontier of personalized recommendations: the application of deep learning in recommendation systems