
 Technology peripheralsAIHigh-precision and low-cost 3D face reconstruction solution for games, interpretation of Tencent AI Lab ICCV 2023 paper
Technology peripheralsAIHigh-precision and low-cost 3D face reconstruction solution for games, interpretation of Tencent AI Lab ICCV 2023 paperHigh-precision and low-cost 3D face reconstruction solution for games, interpretation of Tencent AI Lab ICCV 2023 paper

3D face reconstruction is a key technology widely used in game film and television production, digital people, AR/VR, face recognition and editing and other fields. Its goal is to obtain high-quality images from a single or multiple images. 3D face model. With the help of complex shooting systems in studios, currently mature solutions in the industry can achieve reconstruction effects with pore-level accuracy that are comparable to real people [2]. However, their production costs are high and their cycle times are long, and they are generally only used in S-level film and television or game projects.
In recent years, interactive gameplay based on low-cost face reconstruction technology (such as game character face pinching gameplay, AR/VR virtual image generation, etc.) has been welcomed by the market. Users only need to input pictures that can be obtained daily, such as single or multiple pictures taken by mobile phones, to quickly obtain a 3D model. However, the imaging quality of the existing methods is uncontrollable, the accuracy of the reconstruction results is low, and it is unable to express the details of the face [3-4]. How to obtain high-fidelity 3D faces at low cost is still an unsolved problem.
The first step in face reconstruction is to define the face expression method. However, the existing mainstream face parameterized models have limited expression capabilities. Even with more constraint information, such as multi-view images, the reconstruction accuracy is difficult. promote. Therefore, Tencent AI Lab proposed an improved Adaptive Skinning Model (hereinafter referred to as ASM) as a parametric face model, which uses face priors and uses a Gaussian mixture model to express face masking. Pi weights greatly reduce the number of parameters so that they can be solved automatically.
Tests show that ASM method uses only a small number of parameters without the need for training, which significantly improves the expression ability of faces and the accuracy of multi-view face reconstruction, innovating the SOTA level. The relevant paper has been accepted by ICCV-2023. The following is a detailed explanation of the paper.
Paper title: ASM: Adaptive Skinning Model for High-Quality 3D Face Modeling

Research Challenge: Low-cost, high-precision 3D face reconstruction problem
Getting more informative 3D images from 2D images The model is an underdetermined problem with infinite solutions. In order to make it solvable, researchers introduce face priors into reconstruction, which reduces the difficulty of solving and expresses the 3D shape of the face with fewer parameters, that is, a parametric face model. Most of the current parametric face models are based on the 3D Morphable Model (3DMM) and its improved version. 3DMM is a parametric face model first proposed by Blanz and Vetter in 1999 [5]. The article assumes that a face can be obtained through a linear or non-linear combination of multiple different faces. It builds a face base library by collecting hundreds of high-precision 3D models of real faces, and then combines parameterized faces to express new features. Face model. Subsequent research optimized 3DMM by collecting more diverse real face models [6, 7] and improving dimensionality reduction methods [8, 9]. However, the 3DMM face-like model has high robustness but insufficient expressive ability. Although it can stably generate face models with average accuracy when the input image is blurred or occluded, when multiple high-quality images are used as input, 3DMM has limited expression ability and cannot utilize more input information. Therefore, limits the reconstruction accuracy. This limitation stems from two aspects. First, the limitations of the method itself. Second, the method relies on the collection of face model data. Not only is the cost of data acquisition high, but also it is difficult to apply in practical applications due to the sensitivity of face data. Extensive reuse.ASM method: Redesign the skeleton-skinned model
In order to solve the problem of insufficient expression ability of the existing 3DMM face model, this article introduces the " Skeleton-Skinned Model" as a baseline facial expression. Skeleton-skinned models are a common facial modeling method used to express the face shapes and expressions of game characters in the process of game and animation production. It is connected to the Mesh vertices on the human face through virtual bone points. The skin weight determines the influence weight of the bones on the Mesh vertices. When used, you only need to control the movement of the bones to indirectly control the movement of the Mesh vertices. Normally, the skeleton-skin model requires animators to perform precise bone placement and skin weight drawing, which has the characteristics of high production threshold and long production cycle. However, the shapes of bones and muscles of different people in real human faces are quite different. A set of fixed skeleton-skinning system is difficult to express the various face shapes in reality. For this reason, this article uses the existing skeleton-skinning system On the basis of further design, the adaptive bone-skinning model ASM is proposed, which is based on Gaussian mixture skinning weights (GMM Skinning Weights) and dynamic bone binding system (Dynamic Bone Binding)to further improve the bone-skinning Expressive ability and flexibility, adaptively generate a unique skeleton-skin model for each target face to express richer facial details.
In order to improve the expressive ability of the skeleton-skin model for modeling different faces, ASM has made a new design for the modeling method of the skeleton-skin model.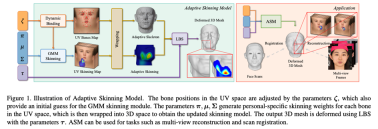
# Skinning (LBS) algorithm controls the deformation of Mesh vertices by controlling the movement (rotation, translation, scaling) of bones. Traditional bone-skinning consists of two parts, namely the skin weight matrix and bone binding. ASM parameters these two parts separately to achieve an adaptive bone-skinning model. Next, we will introduce the parametric modeling methods of skin weight matrix and bone binding respectively.
## Formula 1: LBS formula of traditional skeleton-skinned model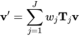
Formula 2: ASM’s LBS formula
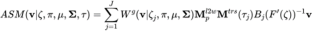
Gaussian Mixed Skinning Weights (GMM Skinning Weights)The skin weight matrix is an mxn-dimensional matrix, where m is the number of bones and n is the number of vertices on the Mesh. This matrix is used to store the influence coefficient of each bone on each Mesh vertex. Generally speaking, the skin weight matrix is highly sparse. For example, in Unity, each Mesh vertex will only be affected by up to 4 bones. Except for these 4 bones, the influence coefficient of the other bones on the vertex is 0. In the traditional bone-skinned model, the skin weights are drawn by the animator, and once the skin weights are obtained, they will no longer change when used. In recent years, some work [1] has tried to combine a large amount of data with neural network learning to automatically generate skinning weights. However, such a solution has two problems. First, training the neural network requires a large amount of data. If it is a 3D face or skinning Weight data is more difficult to obtain; secondly, there is serious parameter redundancy in using neural network to model skin weights.
Is there a skin weight modeling method that can fully express the skin weight of the entire face using a small number of parameters without training?By observing common skinning weights, we can find the following properties: 1. The skinning weight is locally smooth; 2. The farther the Mesh vertex is from the current bone position, the corresponding skinning coefficient is usually smaller. ; And this property is very consistent with the Gaussian Mixture Model (GMM). Therefore, this article proposes Gaussian Mixed Skinning Weights (GMM Skinning Weights) to model the skinning weight matrix as a Gaussian mixture function based on a certain distance function between vertices and bones, so that a set of GMM coefficients can be used to express the skinning weights of specific bones. distributed. In order to further compress the parameters of the skin weight, we transfer the entire face Mesh from the three-dimensional space to the UV space, so that we only need to use the two-dimensional GMM and use the UV distance from the vertex to the bone to calculate the current bone's masking of a specific vertex. Skin weight coefficient.
Dynamic Bone Binding
Parametric modeling of skin weights not only allows us to express the skin weight matrix with a small number of parameters, but also It makes it possible for us to adjust the bone binding position at run-time. Therefore, this article proposes the method of dynamic bone binding (Dynamic Bone Binding). Same as the skin weight, this article models the binding position of the bone as a coordinate point on the UV space, and can move arbitrarily in the UV space. For the vertices of the face Mesh, the vertices can be mapped to a fixed coordinate in the UV space simply through the predefined UV mapping relationship. But the bones are not predefined in UV space, so for this we need to transfer the bound bones from three-dimensional space to UV space. This step in this article is implemented by interpolating the coordinates of the bones and surrounding vertices. We apply the calculated interpolation coefficients to the UV coordinates of the vertices to obtain the UV coordinates of the bones. The same goes for the other way around. When we need to transfer bone coordinates from UV space to three-dimensional space, we also calculate the interpolation coefficient between the UV coordinates of the current bone and the UV coordinates of adjacent vertices, and apply the interpolation coefficient to the same vertex in three-dimensional space. On the three-dimensional coordinates, the three-dimensional space coordinates of the corresponding bones can be interpolated.
Through this modeling method, we unify the binding positions of the bones and the skin weight coefficients into a set of coefficients in the UV space. When using ASM, we convert the deformation of the face Mesh vertices into a combination of the offset coefficient of the bone binding position in the UV space, the Gaussian mixture skinning coefficient in the UV space, and the bone motion coefficient, Greatly improves the expressive ability of the skeleton-skinned model, enabling the generation of richer facial details.

## to The facial expression ability and multi-view reconstruction accuracy reach SOTA level
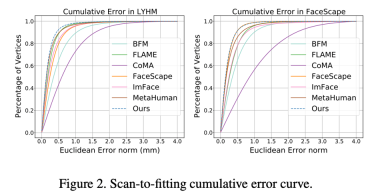
Compare the expressive ability of different parametric face modelsWe use parametric face model registration The method of high-precision face scanning model (Registration) combines ASM with traditional 3DMM based on PCA method (BFM [6], FLAME [7], FaceScape [10]), 3DMM based on neural network dimensionality reduction method (CoMA [ 8], ImFace [9]) and the industry's leading bone-skinned model (MetaHuman) were compared. The results indicate that ASM's expression ability has reached SOTA level on both LYHM and FaceScape data sets.
## Table 2: Registration accuracy of LYHM and FaceScape
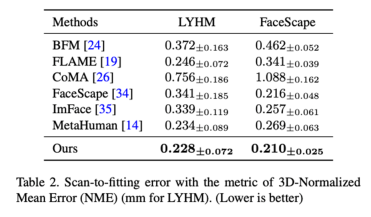
Figure 2: Error distribution of registration accuracy on LYHM and FaceScape
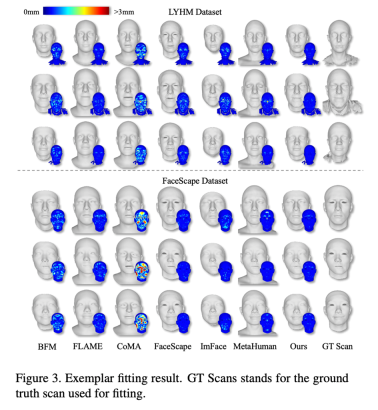
# Figure 3: LYHM Visualization results and error heat map of registration on FaceScape
We used the data of Florence MICC This set tested the performance of ASM on multi-view face reconstruction tasks, and the reconstruction accuracy on the Coop (indoor close-range camera, people with no expressions) test set reached the SOTA level.
# 图 4: 3D face reconstruction results on the Florence Micc data set The impact of the number of pictures on the reconstruction results in the multi-view reconstruction task was tested on the FaceScape data set. The results show that when the number of pictures is around 5, ASM can achieve the highest reconstruction accuracy compared to other facial expression methods.
## to
##This research has taken an important step towards solving the industry problem of obtaining high-fidelity human faces at low cost. The new parametric face model we propose significantly enhances the ability of facial expression and raises the upper limit of accuracy of multi-view face reconstruction to a new level. This method can be used in many fields such as 3D character modeling in game production, automatic face pinching gameplay, and avatar generation in AR/VR.
After the facial expression ability has been significantly improved, how to construct stronger consistency constraints from multi-view images to further improve the accuracy of reconstruction results has become a new bottleneck and new challenge in the current field of face reconstruction. This will also be our future research direction.
References
[1] Noranart Vesdapunt, Mitch Rundle, HsiangTao Wu, and Baoyuan Wang. Jnr: Joint-based neural rig representation for compact 3d face modeling. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16, pages 389–405. Springer, 2020.
[2] Thabo Beeler, Bernd Bickel, Paul Beardsley, Bob Sumner, and Markus Gross. High-quality single-shot capture of facial geometry. In ACM SIGGRAPH 2010 papers, pages 1–9. 2010.
[3] Yu Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia, and Xin Tong. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 0–0, 2019.
[4] Yao Feng, Haiwen Feng, Michael J Black, and Timo Bolkart. Learning an animatable detailed 3d face model from in-the-wild images. ACM Transactions on Graphics (ToG), 40 (4):1–13, 2021.
[5] Volker Blanz and Thomas Vetter. A morphable model for the synthesis of 3d faces. In Proceedings of the 26th annual conference on Computer graphics and interactive techniques, pages 187–194, 1999.
[6] Pascal Paysan, Reinhard Knothe, Brian Amberg, Sami Romdhani, and Thomas Vetter. A 3d face model for pose and illumination invariant face recognition. In 2009 sixth IEEE international conference on advanced video and signal based surveillance, pages 296–301. Ieee, 2009.
[7] Tianye Li, Timo Bolkart, Michael J Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4d scans. ACM Trans. Graph., 36 (6):194–1, 2017.
[8] Anurag Ranjan, Timo Bolkart, Soubhik Sanyal, and Michael J Black. Generating 3d faces using convolutional mesh autoencoders. In Proceedings of the European conference on computer vision (ECCV), pages 704–720, 2018.
[9] Mingwu Zheng, Hongyu Yang, Di Huang, and Liming Chen. Imface: A nonlinear 3d morphable face model with implicit neural representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20343–20352, 2022.
[10] Haotian Yang, Hao Zhu, Yanru Wang, Mingkai Huang, Qiu Shen, Ruigang Yang, and Xun Cao. Facescape: a large-scale high quality 3d face dataset and detailed riggable 3d face prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 601–610, 2020.
The above is the detailed content of High-precision and low-cost 3D face reconstruction solution for games, interpretation of Tencent AI Lab ICCV 2023 paper. For more information, please follow other related articles on the PHP Chinese website!

 The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AM
The AI Skills Gap Is Slowing Down Supply ChainsApr 26, 2025 am 11:13 AMThe term "AI-ready workforce" is frequently used, but what does it truly mean in the supply chain industry? According to Abe Eshkenazi, CEO of the Association for Supply Chain Management (ASCM), it signifies professionals capable of critic
 How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AM
How One Company Is Quietly Working To Transform AI ForeverApr 26, 2025 am 11:12 AMThe decentralized AI revolution is quietly gaining momentum. This Friday in Austin, Texas, the Bittensor Endgame Summit marks a pivotal moment, transitioning decentralized AI (DeAI) from theory to practical application. Unlike the glitzy commercial
 Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AM
Nvidia Releases NeMo Microservices To Streamline AI Agent DevelopmentApr 26, 2025 am 11:11 AMEnterprise AI faces data integration challenges The application of enterprise AI faces a major challenge: building systems that can maintain accuracy and practicality by continuously learning business data. NeMo microservices solve this problem by creating what Nvidia describes as "data flywheel", allowing AI systems to remain relevant through continuous exposure to enterprise information and user interaction. This newly launched toolkit contains five key microservices: NeMo Customizer handles fine-tuning of large language models with higher training throughput. NeMo Evaluator provides simplified evaluation of AI models for custom benchmarks. NeMo Guardrails implements security controls to maintain compliance and appropriateness
 AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AM
AI Paints A New Picture For The Future Of Art And DesignApr 26, 2025 am 11:10 AMAI: The Future of Art and Design Artificial intelligence (AI) is changing the field of art and design in unprecedented ways, and its impact is no longer limited to amateurs, but more profoundly affecting professionals. Artwork and design schemes generated by AI are rapidly replacing traditional material images and designers in many transactional design activities such as advertising, social media image generation and web design. However, professional artists and designers also find the practical value of AI. They use AI as an auxiliary tool to explore new aesthetic possibilities, blend different styles, and create novel visual effects. AI helps artists and designers automate repetitive tasks, propose different design elements and provide creative input. AI supports style transfer, which is to apply a style of image
 How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AM
How Zoom Is Revolutionizing Work With Agentic AI: From Meetings To MilestonesApr 26, 2025 am 11:09 AMZoom, initially known for its video conferencing platform, is leading a workplace revolution with its innovative use of agentic AI. A recent conversation with Zoom's CTO, XD Huang, revealed the company's ambitious vision. Defining Agentic AI Huang d
 The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AM
The Existential Threat To UniversitiesApr 26, 2025 am 11:08 AMWill AI revolutionize education? This question is prompting serious reflection among educators and stakeholders. The integration of AI into education presents both opportunities and challenges. As Matthew Lynch of The Tech Edvocate notes, universit
 The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AM
The Prototype: American Scientists Are Looking For Jobs AbroadApr 26, 2025 am 11:07 AMThe development of scientific research and technology in the United States may face challenges, perhaps due to budget cuts. According to Nature, the number of American scientists applying for overseas jobs increased by 32% from January to March 2025 compared with the same period in 2024. A previous poll showed that 75% of the researchers surveyed were considering searching for jobs in Europe and Canada. Hundreds of NIH and NSF grants have been terminated in the past few months, with NIH’s new grants down by about $2.3 billion this year, a drop of nearly one-third. The leaked budget proposal shows that the Trump administration is considering sharply cutting budgets for scientific institutions, with a possible reduction of up to 50%. The turmoil in the field of basic research has also affected one of the major advantages of the United States: attracting overseas talents. 35
 All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AM
All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI unveils the powerful GPT-4.1 series: a family of three advanced language models designed for real-world applications. This significant leap forward offers faster response times, enhanced comprehension, and drastically reduced costs compared t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

WebStorm Mac version
Useful JavaScript development tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 English version
Recommended: Win version, supports code prompts!

