
 Technology peripheralsAIThink of LLM as an operating system, it has unlimited 'virtual' context, Berkeley's new work has received 1.7k stars
Technology peripheralsAIThink of LLM as an operating system, it has unlimited 'virtual' context, Berkeley's new work has received 1.7k starsThink of LLM as an operating system, it has unlimited 'virtual' context, Berkeley's new work has received 1.7k stars

In recent years, large language models (LLMs) and their underlying transformer architecture have become the cornerstone of conversational AI and have spawned a wide range of consumer and enterprise applications. Despite considerable progress, the fixed-length context window used by LLM greatly limits the applicability to long conversation or long document reasoning. Even for the most widely used open source LLMs, their maximum input length only allows support of a few dozen message replies or short document inference.
At the same time, limited by the self-attention mechanism of the transformer architecture, simply extending the context length of the transformer will also cause the calculation time and memory cost to increase exponentially, which makes a new long context architecture urgent. research topic.
However, even if we can overcome the computational challenges of context scaling, recent research has shown that long-context models struggle to effectively utilize the additional context.
How to solve this? Given the massive resources required to train SOTA LLM and the apparent diminishing returns of context scaling, we urgently need alternative techniques that support long contexts. Researchers at the University of California, Berkeley, have made new progress in this regard.
In this article, researchers explore how to provide the illusion of infinite context while continuing to use a fixed context model. Their approach borrows ideas from virtual memory paging, enabling applications to process data sets that far exceed available memory.
Based on this idea, researchers took advantage of the latest advances in LLM agent function calling capabilities to design an OS-inspired LLM system for virtual context management - MemGPT.

Paper homepage: https://memgpt.ai/
arXiv address: https://arxiv.org/pdf/2310.08560.pdf
The project has been open sourced and has gained 1.7k stars on GitHub.

GitHub address: https://github.com/cpacker/MemGPT
Method Overview
The The research draws inspiration from the hierarchical memory management of traditional operating systems to efficiently "page" information in and out between context windows (similar to "main memory" in operating systems) and external storage. MemGPT is responsible for managing the control flow between memory, LLM processing module and users. This design allows for iterative context modification during a single task, allowing the agent to more efficiently utilize its limited context window.
MemGPT treats the context window as a restricted memory resource and designs a hierarchical structure for LLM similar to hierarchical memory in traditional operating systems (Patterson et al., 1988). In order to provide longer context length, this research allows LLM to manage content placed in its context window through "LLM OS" - MemGPT. MemGPT enables LLM to retrieve relevant historical data that is lost in context, similar to page faults in operating systems. Additionally, agents can iteratively modify the contents of a single task context window, just as a process can repeatedly access virtual memory.
MemGPT enables LLM to handle unbounded contexts when the context window is limited. The components of MemGPT are shown in Figure 1 below.
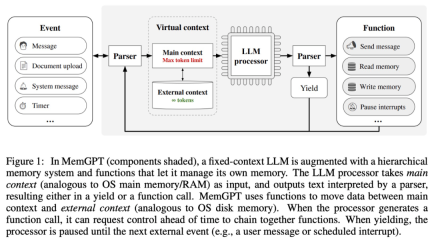
MemGPT coordinates the movement of data between the main context (content in the context window) and external contexts through function calls. MemGPT updates and retrieves autonomously based on the current context.


It is worth noting that the context window needs to use a warning token to identify its restrictions, as shown in Figure 3 below:

Experiments and results
In the experimental part, the researchers evaluated MemGPT in two long context domains, namely conversational agents and document processing. For conversational agents, they extended the existing multi-session chat dataset (Xu et al. (2021)) and introduced two new conversation tasks to evaluate the agent's ability to retain knowledge in long conversations. For document analysis, they benchmark MemGPT on tasks proposed by Liu et al. (2023a), including question answering and key-value retrieval of long documents.
MemGPT for Conversational Agents
When talking to the user, the agent must meet the following two key criteria.
The first is consistency, that is, the agent should maintain the continuity of the conversation, and the new facts, references, and events provided should be consistent with the previous statements of the user and the agent.
The second is participation, that is, the agent should use the user's long-term knowledge to personalize the response. Referring to previous conversations can make the conversation more natural and engaging.
Therefore, the researchers evaluated MemGPT based on these two criteria:
Can MemGPT leverage its memory to improve conversational consistency? Can you remember relevant facts, quotes, events from past interactions to maintain coherence?
MemGPT Is it possible to use memory to generate more engaging conversations? Spontaneously merge remote user information to personalize information?
Regarding the data set used, the researchers evaluated and compared MemGPT and the fixed context baseline model on the multi-session chat (MSC) proposed by Xu et al. (2021).
First come to consistency evaluation. The researchers introduced a deep memory retrieval (DMR) task based on the MSC dataset to test the consistency of the conversational agent. In DMR, a user poses a question to a conversational agent, and the question explicitly references a previous conversation, with the expectation that the answer range will be very narrow. For details, please refer to the example in Figure 5 below.
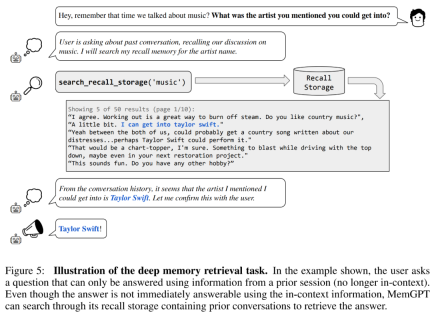
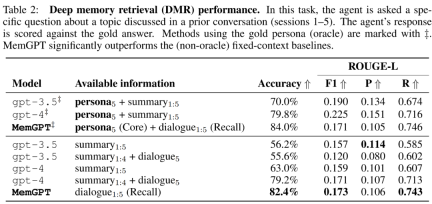
MemGPT utilizes memory to maintain consistency. Table 2 below shows the performance comparison of MemGPT against fixed memory baseline models, including GPT-3.5 and GPT-4.
It can be seen that MemGPT is significantly better than GPT-3.5 and GPT-4 in terms of LLM judgment accuracy and ROUGE-L score. MemGPT can use Recall Memory to query past conversation history to answer DMR questions, rather than relying on recursive summarization to expand context.
Then in the "conversation starter" task, the researchers assessed the agent's ability to extract engaging messages from the accumulated knowledge of previous conversations and deliver them to the user.
The researchers show the CSIM scores of MemGPT’s opening remarks in Table 3 below. The results show that MemGPT is able to produce engaging intros that perform as well as or better than human handwritten intros. It is also observed that MemGPT tends to produce openings that are longer and cover more character information than the human baseline. Figure 6 below is an example.


MemGPT for document analysis
To evaluate MemGPT’s ability to analyze documents, We benchmarked MemGPT and a fixed-context baseline model on the Liu et al. (2023a) retriever-reader document QA task.
The results show that MemGPT is able to efficiently make multiple calls to the retriever by querying the archive storage, allowing it to scale to larger effective context lengths. MemGPT actively retrieves documents from the archive store and can iteratively page through the results so that the total number of documents available to it is no longer limited by the number of documents in the applicable LLM processor context window.
Due to the limitations of embedding-based similarity search, the document QA task poses a great challenge to all methods. Researchers observed that MemGPT stops paginating crawler results before the crawler database is exhausted.
In addition, there is a trade-off in the retrieval document capacity created by more complex operations of MemGPT, as shown in Figure 7 below. Its average accuracy is lower than GPT-4 (higher than GPT-3.5), but it can be easily extended Larger document.
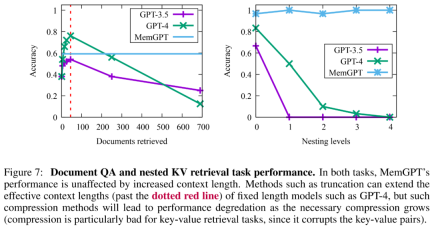
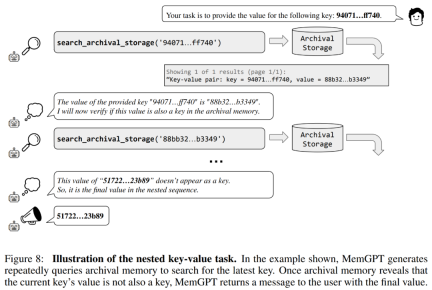
The researchers also introduced a new task based on synthetic key-value retrieval, namely Nested Key-Value Retrieval, to demonstrate how MemGPT Organize information from multiple data sources.
From the results, although GPT-3.5 and GPT-4 showed good performance on the original key-value task, they performed poorly on the nested key-value retrieval task. MemGPT is not affected by the number of nesting levels and can perform nested lookups by repeatedly accessing key-value pairs stored in main memory through function queries.
MemGPT's performance on nested key-value retrieval tasks demonstrates its ability to perform multiple lookups using a combination of multiple queries.
For more technical details and experimental results, please refer to the original paper.
The above is the detailed content of Think of LLM as an operating system, it has unlimited 'virtual' context, Berkeley's new work has received 1.7k stars. For more information, please follow other related articles on the PHP Chinese website!

 How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AM
How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AMRunning large language models at home with ease: LM Studio User Guide In recent years, advances in software and hardware have made it possible to run large language models (LLMs) on personal computers. LM Studio is an excellent tool to make this process easy and convenient. This article will dive into how to run LLM locally using LM Studio, covering key steps, potential challenges, and the benefits of having LLM locally. Whether you are a tech enthusiast or are curious about the latest AI technologies, this guide will provide valuable insights and practical tips. Let's get started! Overview Understand the basic requirements for running LLM locally. Set up LM Studi on your computer
 Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AM
Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AMGuy Peri is McCormick’s Chief Information and Digital Officer. Though only seven months into his role, Peri is rapidly advancing a comprehensive transformation of the company’s digital capabilities. His career-long focus on data and analytics informs
 What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AM
What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AMIntroduction Artificial intelligence (AI) is evolving to understand not just words, but also emotions, responding with a human touch. This sophisticated interaction is crucial in the rapidly advancing field of AI and natural language processing. Th
 12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AM
12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AMIntroduction In today's data-centric world, leveraging advanced AI technologies is crucial for businesses seeking a competitive edge and enhanced efficiency. A range of powerful tools empowers data scientists, analysts, and developers to build, depl
 AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AM
AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AMThis week's AI landscape exploded with groundbreaking releases from industry giants like OpenAI, Mistral AI, NVIDIA, DeepSeek, and Hugging Face. These new models promise increased power, affordability, and accessibility, fueled by advancements in tr
 Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AM
Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AMBut the company’s Android app, which offers not only search capabilities but also acts as an AI assistant, is riddled with a host of security issues that could expose its users to data theft, account takeovers and impersonation attacks from malicious
 Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AM
Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AMYou can look at what’s happening in conferences and at trade shows. You can ask engineers what they’re doing, or consult with a CEO. Everywhere you look, things are changing at breakneck speed. Engineers, and Non-Engineers What’s the difference be
 Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AM
Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AMSimulate Rocket Launches with RocketPy: A Comprehensive Guide This article guides you through simulating high-power rocket launches using RocketPy, a powerful Python library. We'll cover everything from defining rocket components to analyzing simula


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

WebStorm Mac version
Useful JavaScript development tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Zend Studio 13.0.1
Powerful PHP integrated development environment

