
Home >Technology peripherals >AI >The innovative work of Chen Danqi's team: Obtain SOTA at 5% cost, setting off a craze for 'alpaca shearing'
The innovative work of Chen Danqi's team: Obtain SOTA at 5% cost, setting off a craze for 'alpaca shearing'

- 王林forward
- 2023-10-12 14:29:04850browse
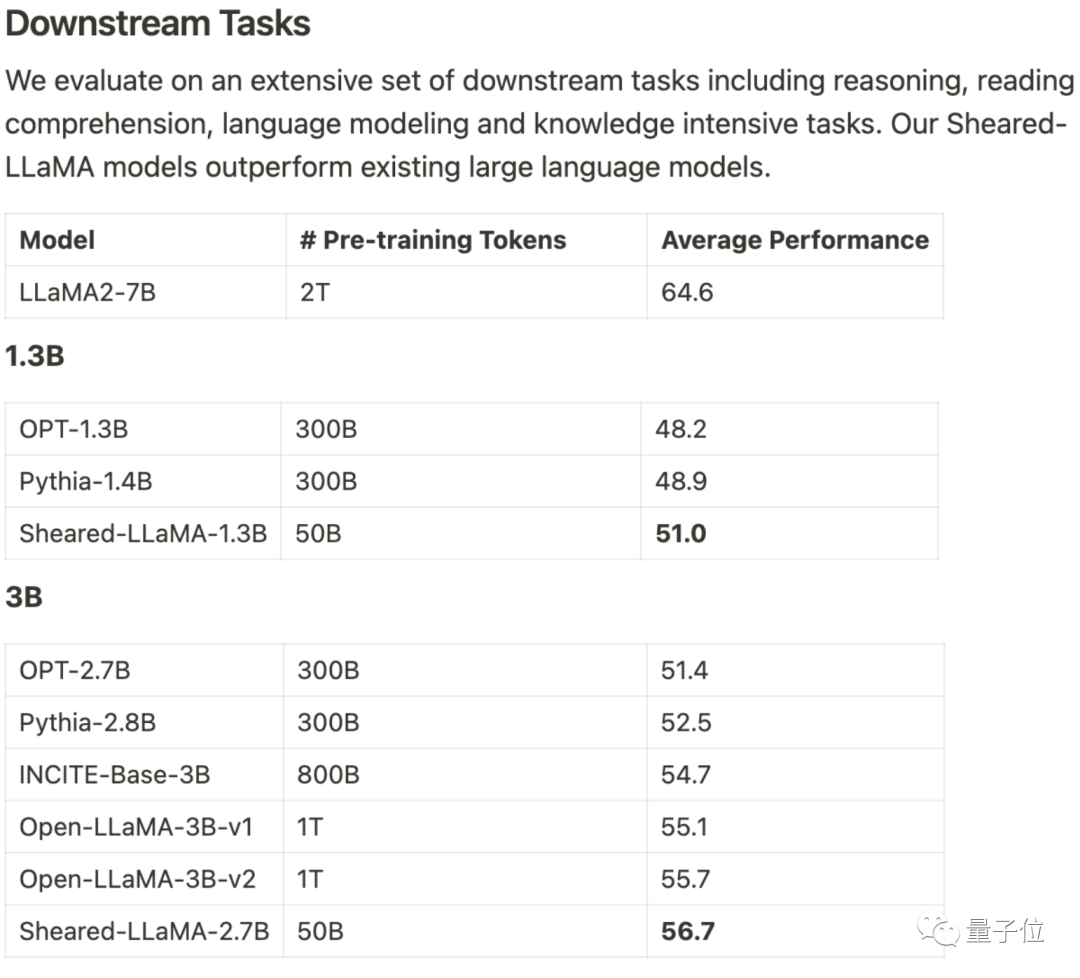
Only 3% of the calculation, 5% of the costobtained SOTA, dominating the 1B-3B scale of open source Large model.
This result comes from the Princeton Chen Danqi team, called LLM-ShearingLarge Model Pruning Method.

Based on the alpaca LLaMA 2 7B, the 1.3B and 3B pruned Sheared-LLama models are obtained through directional structured pruning.

To surpass the previous model of the same scale in terms of downstream task evaluation, it needs to be rewritten
Xia Mengzhou, the first author, said, "Much more cost-effective than pre-training from scratch."

The paper also gives an example of the pruned Sheared-LLaMA output, indicating that despite the scale of only 1.3B and 2.7B, it can already generate coherent and rich content. reply.
For the same task of "acting as a semiconductor industry analyst", the answer structure of version 2.7B is even clearer.

The team stated that although currently only Llama 2 7B version has been used for pruning experiments, the methodcan be extended to other model architectures, can also be expanded to any scale.
An additional benefit after pruning is that you can choose high-quality data sets for continued pre-training

Some developers said that in just 6 Months ago, almost everyone believed that models below 65B had no practical use
If this continues, I bet that 1B-3B models can also generate great value, if not now, then soon.

Treat pruning as constrained optimization
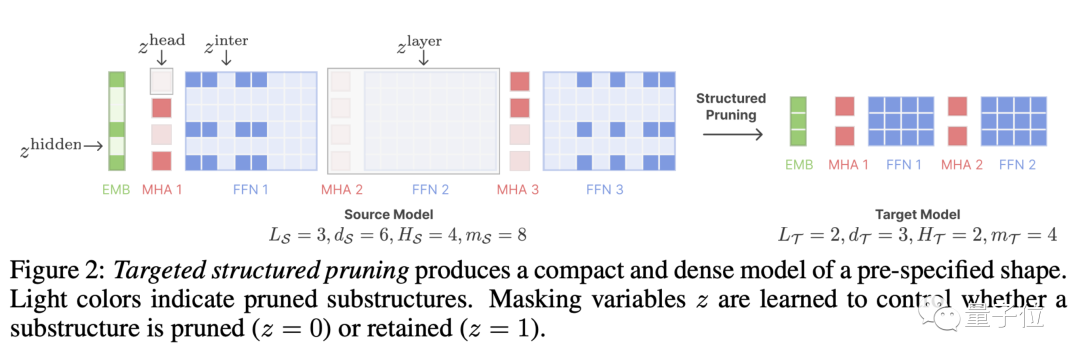
LLM-Shearing, specifically a directional structured pruning Branch, prune a large model to the specified target structure.
Previous pruning methods may cause model performance degradation because some structures will be deleted, affecting its expressive ability
By treating pruning as a constrained optimization problem, we propose a New methods. We search for subnetworks that match the specified structure by learning the pruning mask matrix, with the goal of maximizing performance
Next, continue with the pruned model Pre-training can restore the performance loss caused by pruning to a certain extent.
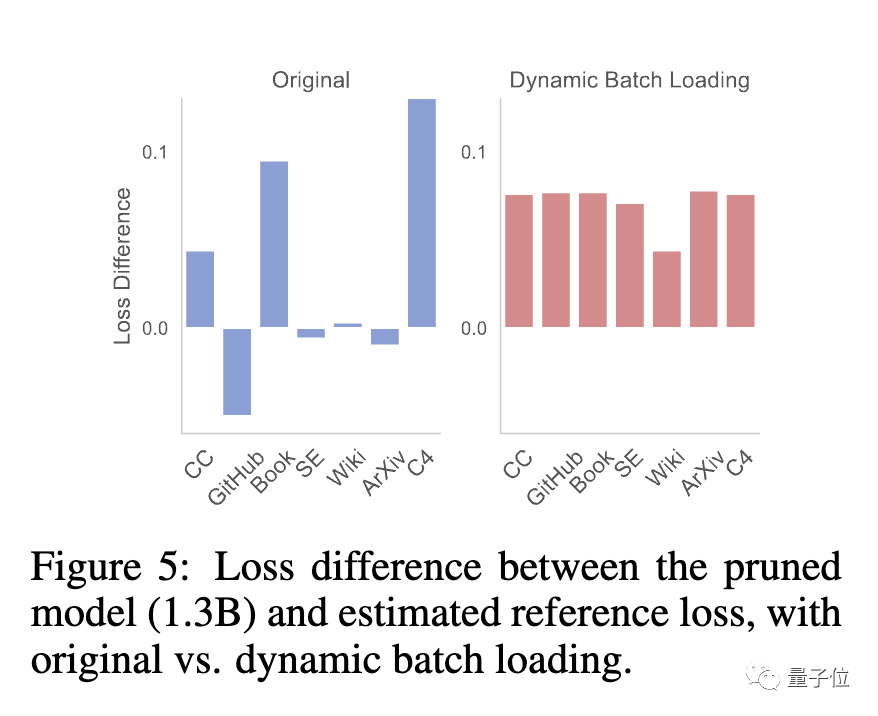
At this stage, the team found that the pruned model and the model trained from scratch had different loss reduction rates for different data sets, resulting in the problem of low data usage efficiency.
For this purpose, the team proposed Dynamic Batch Loading(Dynamic Batch Loading), which dynamically adjusts the data of each domain according to the model's loss reduction rate on different domain data. proportion to improve data usage efficiency.
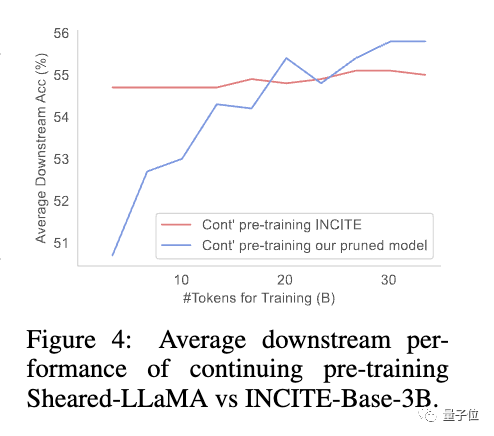
Research has found that although the pruned model has poor initial performance compared to a model of the same size trained from scratch, it can quickly improve through continuous pre-training and eventually surpass
This shows that pruning from a strong base model can provide better initialization conditions for continued pre-training.
will continue to be updated, let’s cut one by one
The authors of the paper are Princeton doctoral students Xia Mengzhou, Gao Tianyu, Tsinghua UniversityZhiyuan Zeng, Princeton Assistant Professor陈 Danqi.
Xia Mengzhou graduated from Fudan University with a bachelor's degree and CMU with a master's degree.
Gao Tianyu is an undergraduate who graduated from Tsinghua University. He won the Tsinghua Special Award in 2019
Both of them are students of Chen Danqi, and Chen Danqi is currently an assistant at Princeton University Professor and co-leader of the Princeton Natural Language Processing Group
Recently, on her personal homepage, Chen Danqi updated her research direction.
"This period is mainly focused on developing large-scale models. Research topics include:"
- How retrieval plays an important role in next-generation models to improve authenticity, adaptability, Interpretability and credibility.
- Low-cost training and deployment of large models, improved training methods, data management, model compression and downstream task adaptation optimization.
- Also interested in work that truly improves understanding of the capabilities and limitations of current large models, both empirically and theoretically.

Sheared-Llama has been made available on Hugging Face
The team said they will continue to update the open source Library
When more large models are released, cut them one by one and continue to release high-performance small models.

One More Thing
I have to say that the large model is too curly now.
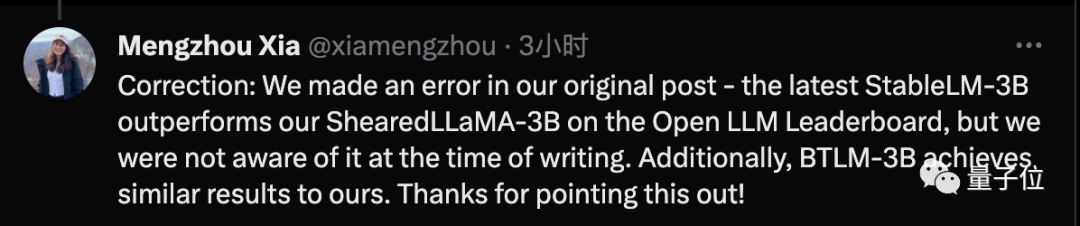
Mengzhou Xia just issued a correction, stating that he used SOTA technology when writing the paper, but after the paper was completed, it was surpassed by the latest Stable-LM-3B technology
Paper address: https://arxiv.org/abs/2310.06694
##Hugging Face: https://huggingface.co/princeton-nlp
Project homepage link: https://xiamengzhou.github.io/sheared-llama/
The above is the detailed content of The innovative work of Chen Danqi's team: Obtain SOTA at 5% cost, setting off a craze for 'alpaca shearing'. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- New method of 3D model segmentation frees your hands! No manual labeling is required, only one training is required, and unlabeled categories can also be recognized | HKU & Byte
- Implement edge training with less than 256KB of memory, and the cost is less than one thousandth of PyTorch
- Meta researchers make a new AI attempt: teaching robots to navigate physically without maps or training
- Using Pytorch to implement contrastive learning SimCLR for self-supervised pre-training
- The new work of Zhu Jun's team at Tsinghua University: Use 4-digit integers to train Transformer, which is 2.2 times faster than FP16, 35.1% faster, accelerating the arrival of AGI!