

 Technology peripheralsAIGNNs technology applied to recommendation systems and its practical applications
Technology peripheralsAIGNNs technology applied to recommendation systems and its practical applicationsGNNs technology applied to recommendation systems and its practical applications


1. The evolution of underlying computing power of GNNs recommendation system
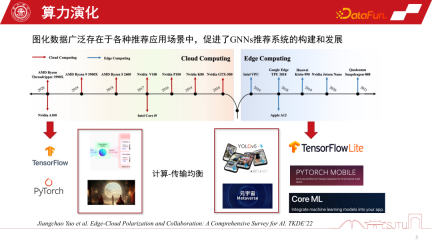
In the past 20 years, computing forms have continued to evolve. Before 2010, cloud computing was particularly popular, while other computing forms were relatively weak. With the rapid development of hardware computing power and the introduction of end-side chips, edge computing has become particularly important. The current two major computing forms have shaped the development of AI in two polarized directions. On the one hand, under the cloud computing architecture, we can use ultra-large-scale cluster capabilities to train large-scale AI models, such as Foundation Model or some generative models. On the other hand, with the development of edge computing, we can also deploy AI models to the terminal side to provide more lightweight services, such as performing various recognition tasks on the terminal side. At the same time, with the development of the metaverse, the calculations of many models will be placed on the end side. Therefore, the core issue that these two computing forms want to reconcile is the balance between computing and transmission, followed by the polarized development of artificial intelligence.
2. Personalization of end-side GNNs recommendation system
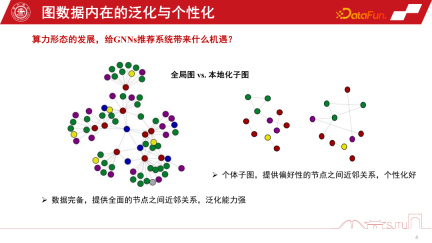
These two calculations What opportunities does form bring to GNNs recommendation systems?
Duanyun’s perspective can be compared to the perspective of a global picture and a localized subgraph. In the recommendation system of GNNs, the global subgraph is a global subgraph that is continuously gathered from many node-level subgraphs. Its advantage is that the data is complete and it can provide a relatively comprehensive relationship between nodes. This kind of inductive bias may be more universal. It summarizes the rules of various nodes and extracts the inductive bias, so it has strong generalization ability. The localized subgraph is not necessarily particularly complete, but its advantage is that it can accurately describe the evolution of an individual's behavior on the subgraph and provide personalized node relationship establishment. Therefore, the relationship between the terminal and the cloud is a bit like a global subgraph and a localized subgraph. Cloud computing can provide powerful centralized computing power to provide services, while the terminal can provide some data personalized services
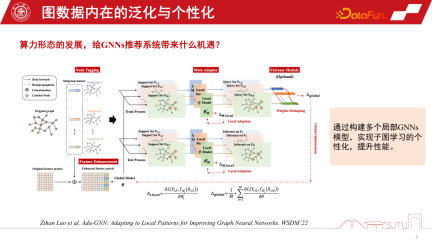
We can combine the advantages of the global graph and localized subgraphs to To better improve the performance of the model, a study published in WSDM2022 this year explored this. It proposes an Ada-GNN (Adapting to Local Patterns for improving Graph Neural Networks) model, which has an entire graph modeling for the global graph, and also builds some local models using subgraphs to do some adaptation. The essence of such adaptation is to allow the model that combines the global model and the local model to perceive the rules of the local graph in a more refined manner and improve personalized learning performance.
Now we use a specific example to explain why we should pay attention to subgraphs. In the e-commerce recommendation system, there is a group of digital enthusiasts who can describe the relationship between digital products, such as mobile phones, Pads, cameras and mobile phone peripheral products. Once he clicked on one of the cameras, an inductive bias was induced. An inductive bias map induced by the group contribution map may encourage us to recommend this kind of mobile phone, but if we return to the individual perspective, if he is a photography enthusiast and pays special attention to photography products, this will sometimes result The paradox shown below. Is the inductive bias induced by the group contribution map too strong for certain groups, especially this tail group? This is what we often call the Matthew effect.

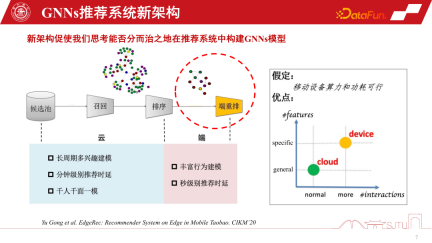
In general, the existing polarized computing forms can reshape our modeling of GNNs recommendation systems. Traditional recommendation systems recall products or items from a candidate pool, perceive the relationship between them through GNNs modeling, and then rank and recommend users. However, due to the support of edge computing, we can deploy personalization models on the end side to perceive more fine-grained personalization by learning on subgraphs. Of course, this new recommendation system architecture for device-cloud collaboration has an assumption, that is, the computing power and power consumption of the device are feasible. But the actual situation is that the computing power overhead of a small model is not large. If you compress it to one or two megabytes and put the computing overhead on an existing smartphone, it will not actually consume more computing power than a game APP. and large electrical energy. Therefore, with the further development of edge computing and the improvement of end device performance, it provides greater possibilities for more GNNs modeling on the end side
If we want to put the GNNs model on the terminal, we must consider the computing power and storage capacity of the terminal. We also mentioned model compression earlier. If you want the GNNs model to be more effective on the device side, if you put a relatively large GNNs model on it, you must perform model compression. The traditional methods of model compression, pruning and quantization, can be used on existing GNNs models, but they will cause performance losses in recommendation systems. In this scenario, we cannot sacrifice performance in order to build a device-side model, so although pruning and quantization are useful, they have limited effect.
Another useful model compression method is distillation. Although it may only be reduced by several times, the cost is similar. A recent study published in KDD is about the distillation of GNNs. In GNNs, distillation of graphical data modeling faces a challenge that distance measures are easily defined in logit space, but in latent feature space, especially layer-by-layer distance measures between teacher GNNs and student GNNs. In this regard, this research on KDD provides a solution to achieve learnable design by learning a metric through adversarial generation
In GNNs recommendation system, in addition to the previous The model compression technique mentioned, split deployment is a specific and very useful technique. It is closely related to the model architecture of GNNs recommendation system, because the bottom layer of GNNs is the Item Embedding of the product, and after several layers of MLP non-linear transformation, the aggregation strategy of GNNs is used
Once a model is trained, it has a natural advantage. The base layer is all shared, and only the GNNs layer can be customized. For personalization here, we can split the model into two parts and put the public part of the model in the cloud. Because the computing power is sufficient, the personalized part can be deployed on the terminal. In this way, we only need to store the GNN of the intermediate kernel in the terminal. In actual recommendation systems, this approach can greatly save the storage overhead of the entire model. We have practiced in Alibaba's scenarios. The model after split deployment may reach the KB level. Then through further simple bit quantization model, the model can be made very small, and there is almost no particularly large overhead when placed on the terminal. Of course, this is a split method based on experience. One of Huawei's recent work published on KDD is automatic model splitting, which can sense the performance of terminal equipment and automatically split this model. Of course, if applied to GNNs, some reshaping may be required
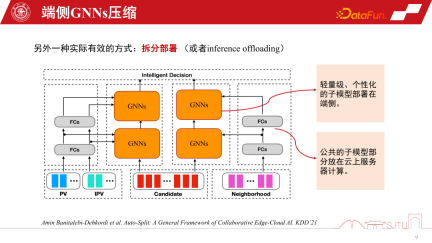
When deploying the model in some serious distribution transfer scenarios, our Pre-trained models are relatively old before they are deployed on the device. This is because the frequency of actual graph data flowing back to the cloud for training is relatively slow, and sometimes it may take a week.
The main bottleneck here isResource constraints, although you may not necessarily encounter this bottleneck in research, in practice you will encounter the problem of outdated end-side models. As the domain changes, the data changes, the model is no longer applicable, and performance will decline. At this time, online personalization of the GNNs model is needed, but personalization on the end will face the challenge of end-side computing power and storage overhead.
Another challenge is data sparseness. Because the end data only has individual nodes, its data sparsity is also a big challenge. Recent research has a relatively efficient approach, which is Parameter-Efficient Transfer. Applying some model patches between layers can be compared to the residual network, but you only need to learn the patches when learning. Through a flag mechanism, it can be turned on when in use and turned off when not in use. When turned off, it can be degraded to the original basic model, which is both safe and efficient.
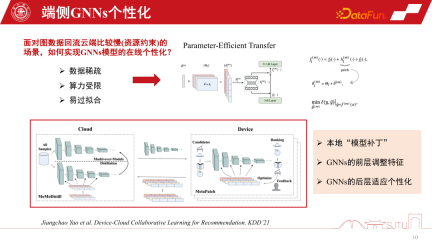
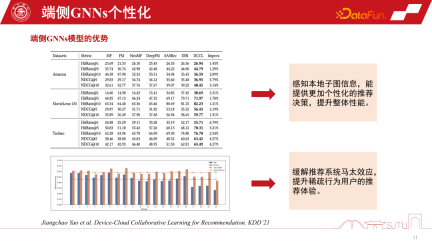
This is a more practical and efficient approach, published on KDD2021, which can achieve online personalization of GNNs models. The most important thing is that we discovered from such a practice that by sensing the subgraph information of this local model, the overall performance can indeed be steadily improved. It also alleviates the Matthew effect.
In the recommendation system, tail users still face the problem of the Matthew effect on graph data. However, if we adopt a divide-and-conquer modeling approach and personalize subgraphs, we can improve the recommendation experience for users with sparse behaviors. Especially for the tail crowd, the performance improvement will be more significant
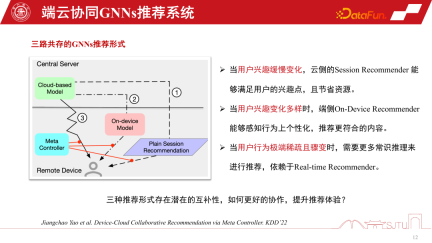
3. Implementation of terminal-cloud collaborative GNNs recommendation system
In the GNNs recommendation system, there is a GNNs model for cloud-side services and a small model of GNNs for the client side. There are three implementation forms of GNNs recommendation system services. The first is session recommendation, which is a common batch session recommendation in recommendation systems to save costs. That is, batch recommendations are made at one time and require users to browse many products before the recommendation will be triggered again. The second is to recommend only one at a time in extreme cases. The third type is the end-to-end personalized model we mentioned. Each of these three recommendation system methods has its own advantages. When user interests change slowly, we only need the cloud side to perceive it accurately, so it is enough for the cloud side model to do session recommendation. When user interests change more and more diversely, personalized recommendation of end-side subgraphs can relatively improve recommendation performance.
In situations where user behavior suddenly becomes very sparse, recommendations rely more on common sense reasoning. In order to coordinate these three recommendation behaviors, a meta coordinator - Meta Controller can be established to coordinate the GNNs recommendation system
Construct a three-way coexistence end-cloud One challenge of collaborative recommendation systems is the construction of data sets, because we don’t know how to manage these models and how to make decisions. So this is just a counterfactual reasoning mechanism. Although we do not have such a data set, we do have a single-channel data set, and we construct some proxy models through evaluation to evaluate their causal effects. If the causal effect is relatively large, then the benefits of making such a decision will be relatively large, and pseudo labels, that is, counterfactual data sets, can be constructed. The specific steps are as follows:
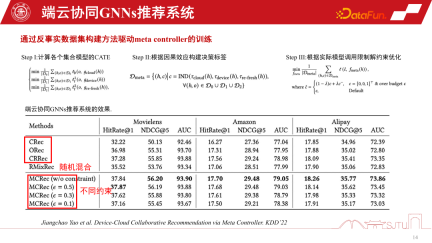
There are three models D0, D1, and D2 in a single channel. By learning the causal model of an agent, their causal effects are estimated. Construct a decision label and construct a counterfactual dataset to train the meta-coordinator. Finally, we can prove that this meta-coordinator has a stable performance improvement compared to each single-channel model. It has significant advantages over random heuristics. We can construct a recommendation system for device-cloud collaboration in this way.
4. Security Issues of the End-Side GNNs Recommendation System
Finally, let’s discuss the security issues of the end-side GNNs recommendation system. Once the device-cloud collaborative GNNs recommendation system is opened for use, it will inevitably face problems in the open environment. Because the model needs to be personalized for learning, there will be some risks of attacks, such as escape attacks, poisoning attacks, backdoor attacks, etc., which may ultimately cause the recommendation system to face huge security risks
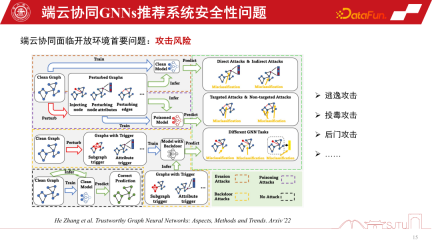
The underlying computing power drives the direction of the current-end cloud collaborative GNNs recommendation system, but it is still in the early stages of development and there are some potential problems, such as security issues. At the same time, in personalized model building There is still a lot of room for improvement in the field of modeling.
5. Question and Answer Session
Q1: When building a graph model on the terminal, will the traffic of subgraphs be distributed too much?
A1: The sub-picture is not distributed, it is actually aggregated. The first point is that sub-pictures are distributed in an accompanying manner. For example, when we want to recommend products, it will naturally carry attribute information of the products. The issuance of companion style here has the same level of overhead as attributes. In fact, the overhead is not very high. Because it does not deliver the entire big picture, but only some neighbor subgraphs. At most, the second-order neighbor subgraphs are still very small. The second point is that some sub-graphs on the end are automatically constructed based on some co-occurrence and clicks based on feedback from user behavior, so it is a form of double-end aggregation and the overall cost is not particularly large.
The above is the detailed content of GNNs technology applied to recommendation systems and its practical applications. For more information, please follow other related articles on the PHP Chinese website!

 The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AM
The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AMThe unchecked internal deployment of advanced AI systems poses significant risks, according to a new report from Apollo Research. This lack of oversight, prevalent among major AI firms, allows for potential catastrophic outcomes, ranging from uncont
 Building The AI PolygraphApr 28, 2025 am 11:11 AM
Building The AI PolygraphApr 28, 2025 am 11:11 AMTraditional lie detectors are outdated. Relying on the pointer connected by the wristband, a lie detector that prints out the subject's vital signs and physical reactions is not accurate in identifying lies. This is why lie detection results are not usually adopted by the court, although it has led to many innocent people being jailed. In contrast, artificial intelligence is a powerful data engine, and its working principle is to observe all aspects. This means that scientists can apply artificial intelligence to applications seeking truth through a variety of ways. One approach is to analyze the vital sign responses of the person being interrogated like a lie detector, but with a more detailed and precise comparative analysis. Another approach is to use linguistic markup to analyze what people actually say and use logic and reasoning. As the saying goes, one lie breeds another lie, and eventually
 Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AM
Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AMThe aerospace industry, a pioneer of innovation, is leveraging AI to tackle its most intricate challenges. Modern aviation's increasing complexity necessitates AI's automation and real-time intelligence capabilities for enhanced safety, reduced oper
 Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AM
Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AMThe rapid development of robotics has brought us a fascinating case study. The N2 robot from Noetix weighs over 40 pounds and is 3 feet tall and is said to be able to backflip. Unitree's G1 robot weighs about twice the size of the N2 and is about 4 feet tall. There are also many smaller humanoid robots participating in the competition, and there is even a robot that is driven forward by a fan. Data interpretation The half marathon attracted more than 12,000 spectators, but only 21 humanoid robots participated. Although the government pointed out that the participating robots conducted "intensive training" before the competition, not all robots completed the entire competition. Champion - Tiangong Ult developed by Beijing Humanoid Robot Innovation Center
 The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AM
The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AMArtificial intelligence, in its current form, isn't truly intelligent; it's adept at mimicking and refining existing data. We're not creating artificial intelligence, but rather artificial inference—machines that process information, while humans su
 New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AM
New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AMA report found that an updated interface was hidden in the code for Google Photos Android version 7.26, and each time you view a photo, a row of newly detected face thumbnails are displayed at the bottom of the screen. The new facial thumbnails are missing name tags, so I suspect you need to click on them individually to see more information about each detected person. For now, this feature provides no information other than those people that Google Photos has found in your images. This feature is not available yet, so we don't know how Google will use it accurately. Google can use thumbnails to speed up finding more photos of selected people, or may be used for other purposes, such as selecting the individual to edit. Let's wait and see. As for now
 Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AM
Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AMReinforcement finetuning has shaken up AI development by teaching models to adjust based on human feedback. It blends supervised learning foundations with reward-based updates to make them safer, more accurate, and genuinely help
 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Notepad++7.3.1
Easy-to-use and free code editor

Zend Studio 13.0.1
Powerful PHP integrated development environment

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Atom editor mac version download
The most popular open source editor

