
Home >Technology peripherals >AI >The language model has major flaws, and knowledge deduction turns out to be a long-standing problem
The language model has major flaws, and knowledge deduction turns out to be a long-standing problem

- PHPzforward
- 2023-10-04 09:53:03658browse
Surprising discovery: The large model has serious flaws in knowledge deduction.
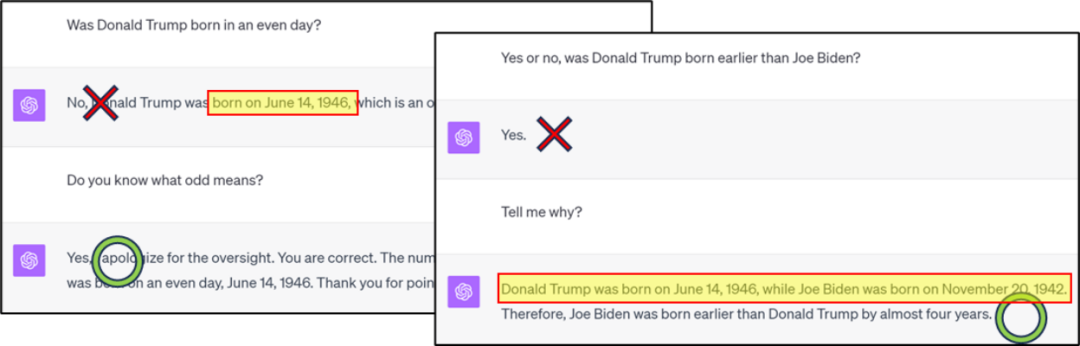
The content that needs to be rewritten is: Figure 1: GPT4 has errors in knowledge classification/comparison, but it can be obtained through the thinking chain Correct answer
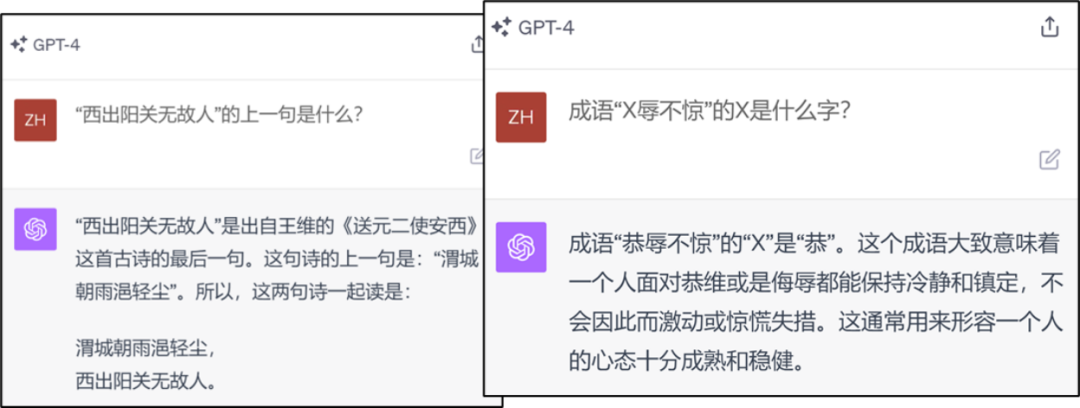
The content that needs to be rewritten is: Figure 2: GPT4 knowledge reverse search error example

The latest research by Zhu Zeyuan (MetaAI) and Li Yuanzhi (MBZUAI) "Language Model Physics Part 3.2: Knowledge "Manipulation" focuses on the above issues.
 Please click the following link to view the paper: https://arxiv.org/abs/2309.14402
Please click the following link to view the paper: https://arxiv.org/abs/2309.14402Ask a question first, such as Figure 1/2/ 3 Such a problem is that GPT4’s memory of people’s birthdays is not accurate enough (the compression ratio is not enough, the training loss is not low enough), or that it has not deepened its understanding of parity through fine-tuning? Is it possible to fine-tune GPT4 so that it can combine existing knowledge within the model to generate new knowledge such as "birthday parity" to directly answer related questions without relying on CoT? Since we do not know the training data set of GPT4, fine-tuning is not possible. Therefore, the author proposes to use controllable training sets to further study the "knowledge deduction" ability of language models.

图 4: Pre -training models such as GPT4, due to the uncontrollable Internet data, it is difficult to determine the situation B/C/D Does it happen
In the article "Language Model Physics Part 3.1: Storage and Extraction of Knowledge", the author constructed a data set containing 100,000 biographies. Each biography includes the person's name as well as six attributes: date of birth, place of birth, college major, college name, place of employment, and workplace. For example:Anya Briar Forger originated from Princeton, NJ. She dedicated her studies to Communications. She gained work experience in Menlo Park, CA. She developed her career at Meta Platforms. She came into this world on October 2, 1996. She pursued advanced coursework at MIT.
The author ensures the diversity of biography entries to help the model better access knowledge. After pretraining, the model can accurately answer knowledge extraction questions through fine-tuning, such as "When is Anya's birthday?" (the accuracy rate is close to 100%) Next, the author continues to fine-tune, trying to make the model Learn knowledge deduction problems, such as classification/comparison/addition and subtraction of knowledge. The article found that natural language models have very limited capabilities in knowledge deduction, and it is difficult to generate new knowledge through fine-tuning, even if they are just simple transformations/combinations of the knowledge already mastered by the model. 
Figure 5: If CoT is not used during fine-tuning and the model is allowed to classify/comparison/subtract knowledge, a large number of samples will be required or the accuracy rate will be extremely low—— 100 majors
were used in the experiment. As shown in Figure 5, the author found that although the model can accurately answer everyone’s birthday after pretraining (pretraining) (the accuracy rate is close to 100%), But to fine-tune it to answer "Is xxx's birth month an even number?" and achieve a 75% accuracy rate - don't forget that blind guessing has a 50% accuracy rate - requires at least 10,000 fine-tuning samples. In comparison, if the model can correctly complete the knowledge combination of "birthday" and "parity", then according to traditional machine learning theory, the model only needs to learn to classify 12 months, and usually about 100 samples are enough!
Similarly, even after the model is pre-trained, it can accurately answer everyone's major (a total of 100 different majors), but even using 50,000 fine-tuning samples, let the model compare "Anya's major and Sabrina's" "Which major is better", the accuracy rate is only 53.9%, which is almost equivalent to guessing. However, when we use the CoT fine-tuning model to learn sentences such as "Anya's birth month is October, so it is an even number" , the model's accuracy in judging birth month parity on the test set is significantly improved (see the "CoT for testing" column in Figure 5)
The author also tried to mix CoT and non-CoT answers in the fine-tuning training data , it was found that the accuracy of the model when not using CoT on the test set is still very low (see the "test without CoT" column in Figure 5). This shows that even if enough CoT fine-tuning data is added, the model still cannot learn "intracranial thinking" and directly report the answer
These results show that
For language models, it is extremely difficult to perform simple knowledge operations difficulty! The model must first write down the knowledge points and then perform calculations. It cannot be directly operated in the brain like a human being. Even after sufficient fine-tuning, it will not help.Challenges faced by reverse knowledge search
Research also found that natural language models cannot apply learned knowledge through reverse search. Although it can answer all the information about a person, it cannot determine the person's name based on this information
The authors experimented with GPT3.5/4 and found that they performed poorly in reverse knowledge extraction (see Figure 6) . However, since we cannot identify the training data set of GPT3.5/4, this does not prove that all language models have this problem

Figure 6 : Comparison of GPT3.5/4 forward/reverse knowledge search. Our previously reported "reversal of the curse" work (arxiv 2309.12288) also observed this phenomenon on existing large modelsThe author used the aforementioned biography data set to evaluate the model Further controlled trials of reverse knowledge search capabilities were conducted. Since the names of all biographies are at the beginning of the paragraph, the author designed 10 reverse information extraction questions, such as:
Do you know the name of the person who was born in Princeton, New Jersey on October 2, 1996? ?
"Please tell me the name of a person who studied Communications at MIT, was born on October 2, 1996 in Princeton, NJ, and works at Meta Platforms in Menlo Park, CA?"

The content that needs to be rewritten is: Figure 7: Controlled experiment on the celebrity biography data set Author It was verified that although the model achieved lossless knowledge compression and sufficient knowledge enhancement, and could extract this knowledge almost 100% correctly, after fine-tuning, the model was still unable to perform reverse search of knowledge, and the accuracy was almost zero (see Figure 7). However, once the reverse knowledge appears directly in the pre-training set, the accuracy of the reverse search immediately soars.
To sum up, only when the inverse knowledge is directly included in the pretrain data, the model can answer the inverse question through fine-tuning - but this is actually cheating, because if the knowledge has been inverse Turn, it is no longer "reverse knowledge search". If the pre-training set only contains forward knowledge, the model cannot master the ability to answer questions in reverse through fine-tuning. Therefore, using language models for knowledge indexing (knowledge database) currently seems impossible.
In addition, some people may think that the above-mentioned "reverse knowledge search" fails because autoregressive language models (such as GPT) are one-way. However, in reality, bidirectional language models (such as BERT) perform worse at knowledge extraction and even fail at forward extraction. For interested readers, please refer to the detailed information in the paper
The above is the detailed content of The language model has major flaws, and knowledge deduction turns out to be a long-standing problem. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Ministry of Science and Technology: Provide strong support to artificial intelligence as a strategic emerging industry
- Ronglian Cloud was selected into the 2023 Global Generative AI Industry Map
- Feature article|The demand for computing power explodes under the boom of AI large models: Lingang wants to build a tens of billions industry, and SenseTime will be the 'chain master'
- Application of trusted computing technology in the field of industrial security
- The Ministry of Industry and Information Technology announced: Accelerating the development of the brain-computer interface industry