
Home >Technology peripherals >AI >The more words in the document, the more excited the model will be! KOSMOS-2.5: Multi-modal large language model for reading 'text-dense images'
The more words in the document, the more excited the model will be! KOSMOS-2.5: Multi-modal large language model for reading 'text-dense images'

- WBOYforward
- 2023-09-29 20:13:10697browse
A clear trend currently is towards building larger and more complex models with tens/hundreds of billions of parameters capable of generating impressive language output
However, existing large-scale language models mainly focus on text information and cannot understand visual information.
So progress in the field of multimodal large language models (MLLMs) aims to address this limitation, MLLMs fuse visual and text information into a single Transformer-based model, making the The model is able to learn and generate content based on both modalities.
MLLMs have shown potential in various practical applications, including natural image understanding and textual image understanding. These models leverage language modeling as a common interface for handling multimodal problems, enabling them to process and generate responses based on textual and visual input. However, the current focus is mainly on lower resolution MLLMs for natural images, there are relatively few studies on text-dense images. Therefore, making full use of large-scale multi-modal pre-training to process text images has become an important direction of MLLM research
by incorporating text images into the training process and developing models based on text and visual information , we can open up new possibilities for multi-modal applications involving high-resolution text-dense images.
Picture
 Paper address: https://arxiv.org/abs/2309.11419
Paper address: https://arxiv.org/abs/2309.11419
KOSMOS-2.5 is a multi-modal large-scale language model based on text-dense images. It is developed on the basis of KOSMOS-2 and highlights the multi-modal reading and understanding capabilities of text-dense images ( Multimodal Literate Model).
The proposed model highlights its excellent performance in understanding text-intensive images, bridging the gap between vision and text
At the same time, this also marks the evolution of the task paradigm, from the previous encoder-decoder architecture to a pure decoder architecture
KOSMOS-2.5 targets text-rich images Enables seamless visual and textual data processing to understand image content and generate structured text descriptions.
Figure 1: Overview of KOSMOS-2.5
 KOSMOS-2.5 is a multi-modal model , as shown in Figure 1, it aims to use a unified framework to handle two closely related tasks
KOSMOS-2.5 is a multi-modal model , as shown in Figure 1, it aims to use a unified framework to handle two closely related tasks
The first task involves generating spatially aware text blocks, i.e. simultaneously Generate the content and coordinate frame of the text block. The content that needs to be rewritten is: The first task involves generating a spatially aware text block, that is, generating the content of the text block and the coordinate box at the same time
#The second task involves using Markdown format Generate structured text output and capture various styles and structures
Figure 2: KOSMOS-2.5 architecture diagram
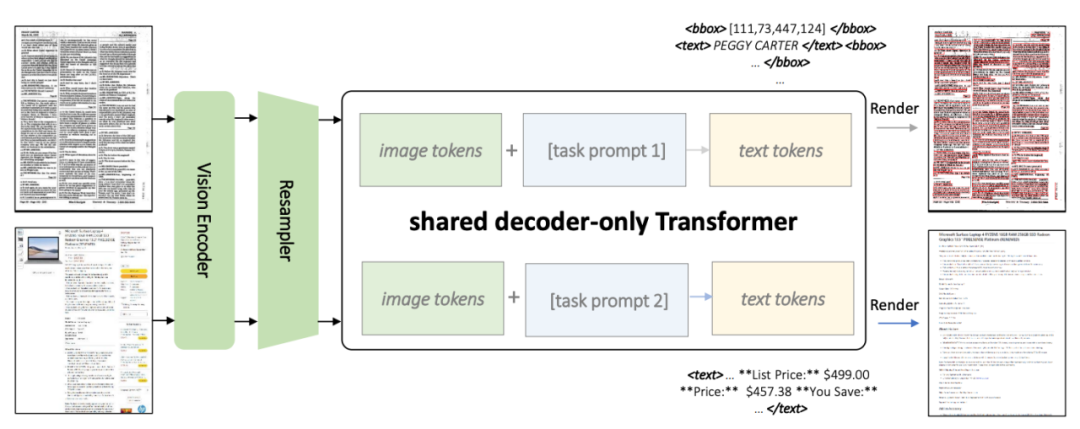 As shown in Figure 2, both tasks use a shared Transformer architecture and task-specific prompts
As shown in Figure 2, both tasks use a shared Transformer architecture and task-specific prompts
KOSMOS-2.5 will be based on ViT (Vision Transformer) vision The encoder is combined with a decoder based on the Transformer architecture, connected through a resampling module.
Figure 3: Pre-training data set
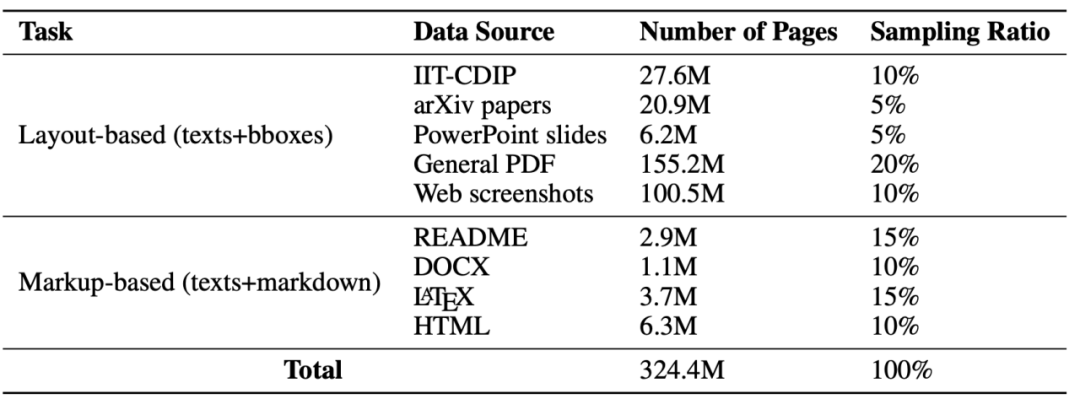 In order to train this model, the author prepared a huge The data set has a size of 324.4M, as shown in Figure 3
In order to train this model, the author prepared a huge The data set has a size of 324.4M, as shown in Figure 3
Figure 4: Example of training sample of text line with bounding box

Figure 5: Example of training sample in Markdown format
 This data set contains various types A text-dense image, which includes lines of text with bounding boxes and plain text in Markdown format, Figures 4 and 5 are training sample example visualizations.
This data set contains various types A text-dense image, which includes lines of text with bounding boxes and plain text in Markdown format, Figures 4 and 5 are training sample example visualizations.
This multi-task training method improves the overall multi-modal capabilities of KOSMOS-2.5
 [Figure 6] End-to-end document-level text recognition experiment
[Figure 6] End-to-end document-level text recognition experiment
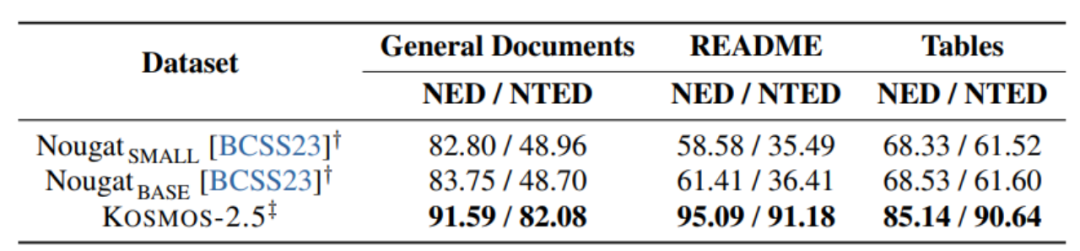 Figure 7: Experiment on generating Markdown format text from images
Figure 7: Experiment on generating Markdown format text from images
As shown in Figures 6 and 7, KOSMOS-2.5 is evaluated on two tasks: end-to-end document-level text recognition and generation of Markdown formatted text from images.
KOSMOS-2.5 performs well in processing text-intensive image tasks, as experimental results demonstrate
 Figure 8: Input and output sample display of KOSMOS-2.5
Figure 8: Input and output sample display of KOSMOS-2.5
KOSMOS-2.5 shows promising capabilities in few-shot learning and zero-shot learning scenarios, making It becomes a versatile tool for practical applications in processing text-rich images. It can be considered as a versatile tool capable of effectively processing text-rich images and exhibiting promising capabilities in both few-shot and zero-shot learning situations
author pointed out that instruction fine-tuning is a promising method to achieve a wider application capability of the model.
In the broader research field, an important direction lies in further developing the ability to expand model parameters.
As tasks continue to expand in scope and complexity, scaling models to handle larger amounts of data is critical for the development of text-intensive multimodal models.
The ultimate goal is to develop a model that can effectively interpret visual and text data and successfully generalize across more text-intensive multi-modal tasks.
When rewriting the content, it needs to be rewritten into Chinese, and the original sentence does not need to appear
https://arxiv.org/abs/2309.11419
The above is the detailed content of The more words in the document, the more excited the model will be! KOSMOS-2.5: Multi-modal large language model for reading 'text-dense images'. For more information, please follow other related articles on the PHP Chinese website!