
Home >Technology peripherals >AI >SupFusion: Exploring how to effectively supervise Lidar-Camera fused 3D detection networks?
SupFusion: Exploring how to effectively supervise Lidar-Camera fused 3D detection networks?

- 王林forward
- 2023-09-28 21:41:071419browse
3D detection based on lidar camera fusion is a key task for autonomous driving. In recent years, many lidar camera fusion methods have emerged and achieved good performance, but these methods always lack a well-designed and effectively supervised fusion process
This article introduces a new training strategy called SupFusion , which provides auxiliary feature-level supervision for lidar camera fusion and significantly improves detection performance. The method includes the Polar Sampling data augmentation method for encrypting sparse targets and training auxiliary models to generate high-quality features for supervision. These features are used to train the lidar camera fusion model and optimize the fused features to simulate the generation of high-quality features. Furthermore, a simple yet effective deep fusion module is proposed, which continuously achieves superior performance compared to previous fusion methods using the SupFusion strategy. The method in this paper has the following advantages: First, SupFusion introduces auxiliary feature-level supervision, which can improve the detection performance of lidar cameras without increasing additional inference costs. Secondly, the proposed deep fusion can continuously improve the capabilities of the detector. The proposed SupFusion and deep fusion modules are plug-and-play, and this paper demonstrates their effectiveness through extensive experiments. In the KITTI benchmark for 3D detection based on multiple lidar cameras, approximately 2% 3D mAP improvement was achieved!
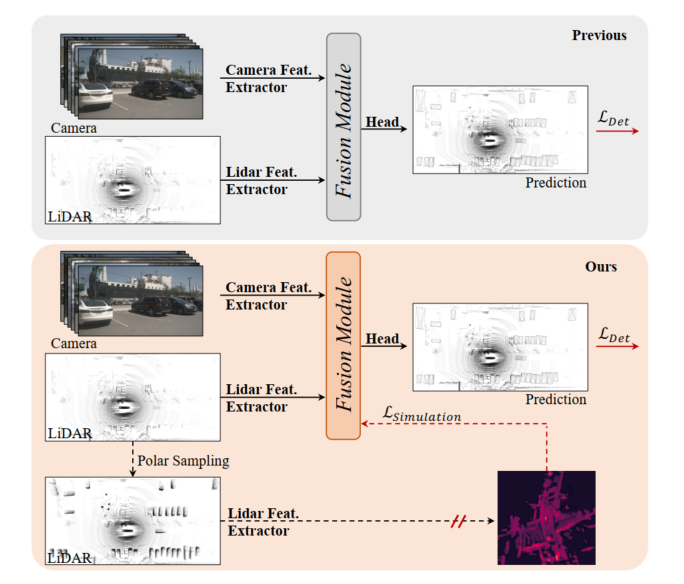
Figure 1: Top, previous lidar camera 3D detection model, the fusion module is optimized by detection loss. Bottom: SupFusion proposed in this article introduces auxiliary supervision through high-quality features provided by auxiliary models.
3D detection based on lidar camera fusion is a critical and challenging task in autonomous driving and robotics. Previous methods always project the camera input to the lidar BEV or Voxel space to align lidar and camera features. Then, a simple concatenation or summation is employed to obtain the fused features for final detection. Furthermore, some deep learning based fusion methods have achieved promising performance. However, previous fusion methods always directly optimize the 3D/2D feature extraction and fusion modules through detection loss, which lacks careful design and effective supervision at the feature level, limiting their performance.
In recent years, distillation methods have shown great improvements in feature-level supervision for 3D detection. Some methods provide lidar features to guide the 2D backbone to estimate depth information based on camera input. Additionally, some methods provide lidar camera fusion capabilities to supervise the lidar backbone to learn global and contextual representations from lidar inputs. By introducing feature-level auxiliary supervision by simulating more robust and high-quality features, the detector can promote marginal improvements. Inspired by this, a natural solution to handle lidar camera feature fusion is to provide stronger, high-quality features and introduce auxiliary supervision for lidar camera 3D detection!
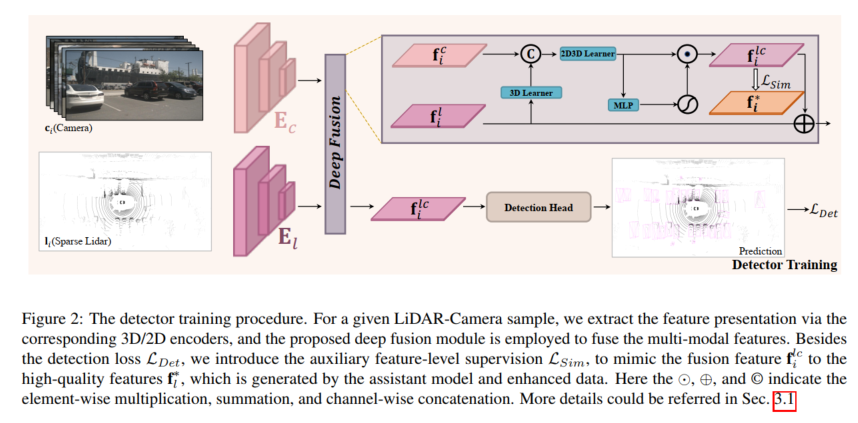
In order to improve the performance of fused 3D detection based on lidar cameras, this article proposes a supervised lidar camera fusion method called SupFusion. This method achieves this by generating high-quality features and providing effective supervision for the fusion and feature extraction processes. First, we train an auxiliary model to provide high-quality features. Unlike previous methods that exploit larger models or additional data, we propose a new data augmentation method called Polar Sampling. Polar Sampling dynamically enhances the density of targets from sparse lidar data, making them easier to detect and improving feature quality, such as accurate detection results. We then simply train a detector based on lidar camera fusion and introduce auxiliary feature-level supervision. In this step, we feed the raw lidar and camera inputs into the 3D/2D backbone and fusion module to obtain fused features. The fused features are fed into the detection head for final prediction, while auxiliary supervision models the fused features into high-quality features. These features are obtained through pre-trained auxiliary models and enhanced lidar data. In this way, the proposed feature-level supervision can enable the fusion module to generate more robust features and further improve detection performance. To better fuse the features of lidar and camera, we propose a simple and effective deep fusion module, which consists of stacked MLP blocks and dynamic fusion blocks. SupFusion can fully tap the capabilities of the deep fusion module and continuously improve detection accuracy!
Main contributions of this article:
- Proposed a new supervised fusion training strategy SupFusion, which mainly consists of high-quality feature generation process, and proposed for the first time auxiliary feature-level supervision for robust fusion feature extraction and accurate 3D detection loss.
- In order to obtain high-quality features in SupFusion, a data augmentation method called "Polar Sampling" is proposed to encrypt sparse targets. Furthermore, an effective deep fusion module is proposed to continuously improve detection accuracy.
- Extensive experiments were conducted based on multiple detectors with different fusion strategies and obtained about 2% mAP improvement on the KITTI benchmark.
Proposed method
The high-quality feature generation process is shown in the figure below. For any given LiDAR sample, the sparse encryption is performed by polar pasting. Target, polar pasting computes direction and rotation to query dense targets from the database, and adds extra points for sparse targets via pasting. This paper first trains the auxiliary model with enhanced data and feeds the enhanced lidar data into the auxiliary model to generate high-quality features f* after its convergence.
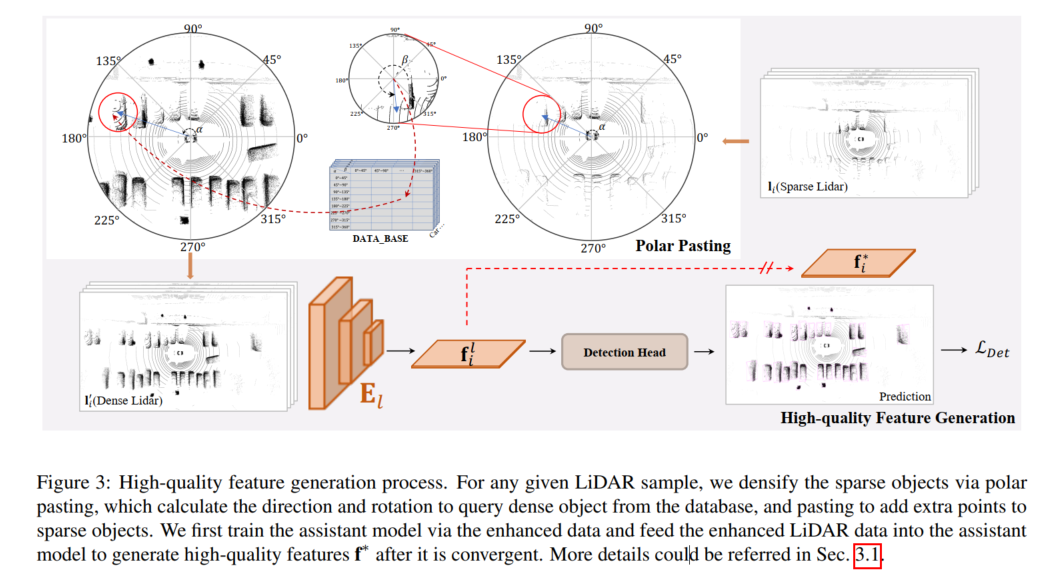
High-quality feature generation
To provide feature-level supervision in SupFusion, an auxiliary model is adopted to generate the High-quality features are captured in the data, as shown in Figure 3. First, an auxiliary model is trained to provide high-quality features. For any sample in D, the sparse lidar data is augmented to obtain enhanced data by polar pasting, which encrypts the alternate target by adding the set of points generated in the polar grouping. Then, after the auxiliary model converges, the enhanced samples are input into the optimized auxiliary model to capture high-quality features for training the lidar camera 3D detection model. In order to better apply to a given lidar camera detector and make it easier to implement, here we simply adopt the lidar branch detector as an auxiliary model!
Detector training
For any given lidar camera detector, the model is trained using the proposed auxiliary supervision at the feature level. Given samples , , the lidar and camera are first input into the 3D and 2D encoders and to capture the corresponding features and these features are input into the fusion model to generate the fused features, and flows into the detection head for final prediction. Furthermore, the proposed auxiliary supervision is employed to simulate fused features with high-quality features generated from the pre-trained auxiliary model and enhanced lidar data. The above process can be formulated as:
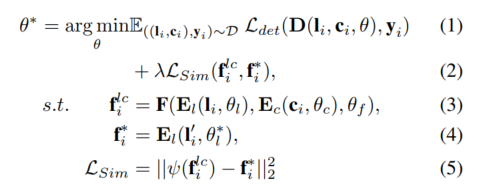
Polar Sampling
In order to provide high-quality features, this paper introduces in the proposed SupFusion A new data augmentation method called Polar Sampling to address the sparsity problem that often causes detection failures. To this end, we perform dense processing of sparse targets in lidar data, similar to how dense targets are processed. Polar coordinate sampling consists of two parts, polar coordinate grouping and polar coordinate pasting. In polar coordinate grouping, we mainly build a database to store dense targets, which is used for polar coordinate pasting, so that sparse targets become denser
Considering the characteristics of the lidar sensor, the collected Point cloud data naturally has a specific density distribution. For example, an object has more points on the surface facing the lidar sensor and fewer points on the opposite sides. The density distribution is mainly affected by orientation and rotation, while the density of points mainly depends on distance. Objects closer to the lidar sensor have a denser density of points. Inspired by this, the goal of this paper is to densify long-distance sparse targets and short-distance dense targets according to the direction and rotation of the sparse targets to maintain the density distribution. We establish a polar coordinate system for the entire scene and the target based on the scene center and the specific target, and define the positive direction of the lidar sensor as 0 degrees to measure the corresponding direction and rotation. We then collect targets with similar density distributions (e.g., have similar orientations and rotations) and generate a dense target for each group in polar groupings and use this in polar paste to dense sparse targets
Polar Grouping
As shown in Figure 4, a database B is constructed here to store the generated dense object point set l according to the direction and rotation in the polar grouping. In Figure Denoted as α and β in 4!
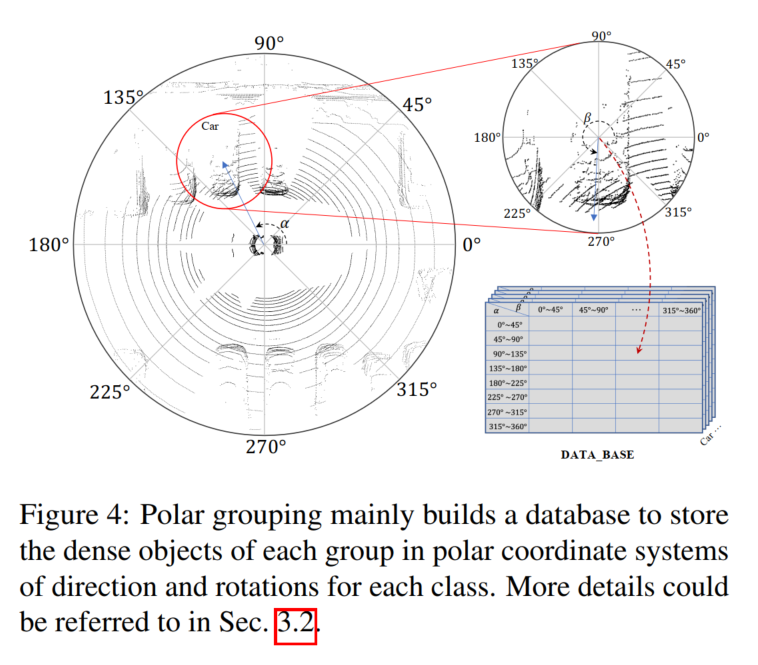
First, the entire dataset is searched, polar angles are calculated for all targets by position and rotation is provided in the datum. Second, divide the targets into groups based on their polar angles. Manually divide the orientation and rotation into N groups, and for any target point set l, you can put it into the corresponding group according to the index:
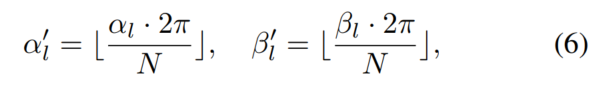
Polar Pasting
As shown in Figure 2, Polar Pasting is used to enhance sparse lidar data to train auxiliary models and generate high-definition quality characteristics. Given LiDAR sample ,,,, contains targets, for any target, the same orientation and rotation as in the grouping process can be calculated and the dense targets from B can be queried based on the label and index, which can be obtained from E.q.6 Obtain all targets in the enhanced sample and obtain enhanced data.
Deep Fusion
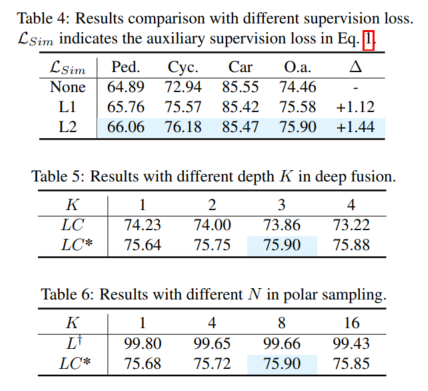
To simulate the high-quality features generated by enhanced LiDAR data, the fusion model is designed to generate from camera inputs Extracting missing information of sparse objects from rich color and contextual features. To this end, this paper proposes a deep fusion module to utilize image features and complete lidar demonstrations. The proposed deep fusion mainly consists of 3D learner and 2D-3D learner. The 3D learner is a simple convolutional layer used to transfer 3D renderings into 2D space. Then, to connect 2D features and 3D renderings (e.g., in 2D space), a 2D-3D learner is used to fuse LiDAR camera features. Finally, the fused features are weighted by MLP and activation functions, which are added back to the original lidar features as the output of the deep fusion module. The 2D-3D learner consists of stacked MLP blocks of depth K and learns to leverage camera features to complete lidar representations of sparse targets to simulate high-quality features of dense lidar targets.
Experimental comparative analysis
Experimental results (mAP@R40%). Listed here are three categories of easy, medium (mod.) and hard cases, as well as overall performance. Here L, LC, LC* represent the corresponding lidar detector, lidar camera fusion detector and the results of this paper’s proposal. Δ represents improvement. The best results are shown in bold, where L is expected to be the auxiliary model and tested on the augmented validation set. MVXNet is re-implemented based on mmdetection3d. PV-RCNN-LC and Voxel RCNN LC are re-implemented based on the open source code of VFF.
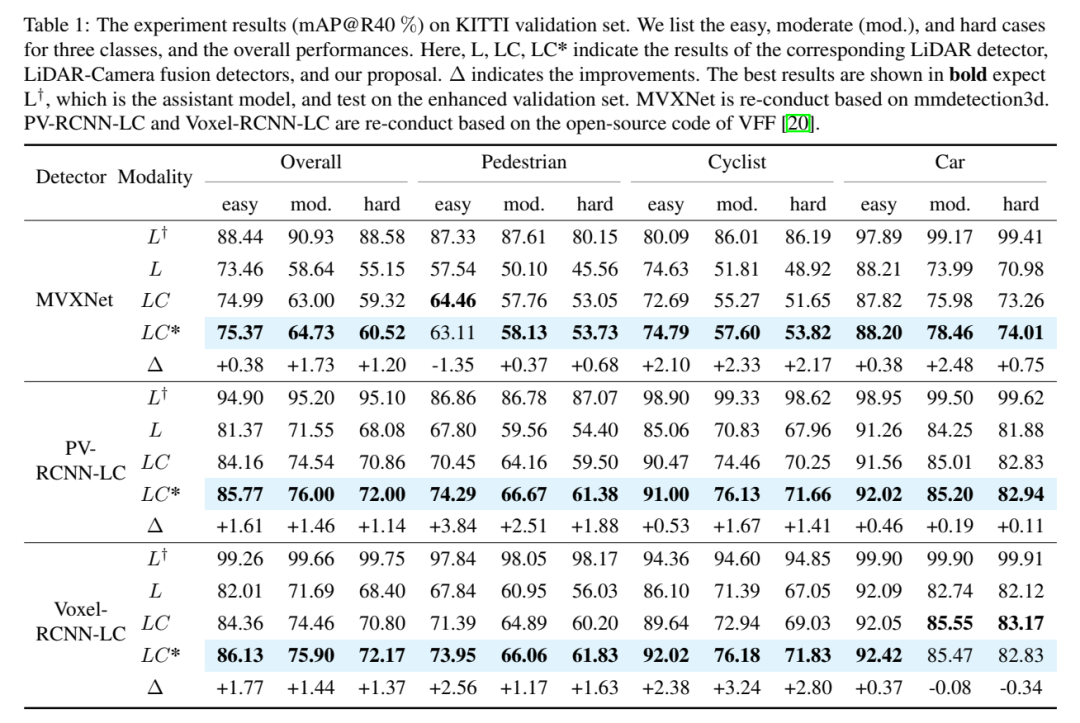
Rewritten content: Overall performance. According to the comparison results in Table 1, the comparison of 3DmAP@R40 based on three detectors shows the overall performance of each category and each difficulty division. It can be clearly observed that by introducing an additional camera input, the lidar camera method (LC) outperforms the lidar-based detector (L) in performance. By introducing polar sampling, the auxiliary model (L†) shows admirable performance on the augmented validation set (e.g., over 90% mAP). With auxiliary supervision with high-quality features and the proposed deep fusion module, our proposal continuously improves detection accuracy. For example, compared to the baseline (LC) model, our proposal achieves 1.54% and 1.24% 3D mAP improvements on medium and hard targets, respectively. In addition, we also conducted experiments on the nuScenes benchmark based on SECOND-LC, as shown in Table 2, NDS and mAP improved by 2.01% and 1.38% respectively
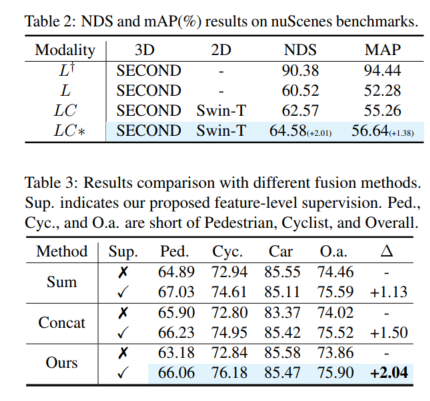
class perception Improve analytics. Compared to the baseline model, SupFusion and deep fusion not only improve the overall performance but also improve the detection performance of each category including Pedestrian. Comparing the average improvement across three categories (e.g. medium case), the following observations can be made: Cyclists saw the largest improvement (2.41%), while pedestrians and cars saw improvements of 1.35% and 0.86% respectively. The reasons are obvious: (1) Cars are easier to spot and get the best results from than pedestrians and cyclists, and therefore harder to improve. (2) Cyclists gain more improvements compared to pedestrians because pedestrians are non-grid and generate less dense targets than cyclists and therefore gain lower performance improvements!

Please click the following link to view the original content: https://mp.weixin.qq.com/s/vWew2p9TrnzK256y-A4UFw
The above is the detailed content of SupFusion: Exploring how to effectively supervise Lidar-Camera fused 3D detection networks?. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Just train once to generate new 3D scenes! The evolution history of Google's 'Light Field Neural Rendering”
- How long will it take for autonomous driving to be realized?
- Autonomous driving is difficult to attack by dimensionality reduction
- How to develop autonomous driving and Internet of Vehicles in PHP?
- Autonomous driving and intelligent network technology in Java