
 Technology peripheralsAIICCV 2023 | ReMoDiffuse, a new paradigm that reshapes human action generation and integrates diffusion models and retrieval strategies, is here
Technology peripheralsAIICCV 2023 | ReMoDiffuse, a new paradigm that reshapes human action generation and integrates diffusion models and retrieval strategies, is hereICCV 2023 | ReMoDiffuse, a new paradigm that reshapes human action generation and integrates diffusion models and retrieval strategies, is here

The human action generation task aims to generate realistic human action sequences to meet the needs of entertainment, virtual reality, robotics and other fields. Traditional generation methods include steps such as 3D character creation, keyframe animation and motion capture, which have many limitations, such as being time-consuming, requiring professional technical knowledge, involving expensive systems and software, and possible compatibility between different software and hardware systems. Sexual issues etc. With the development of deep learning, people began to try to use generative models to achieve automatic generation of human action sequences, for example, by inputting text descriptions and requiring the model to generate action sequences that match the text requirements. As diffusion models are introduced into the field, the consistency of generated actions with given text continues to improve.
However, although the naturalness of the generated actions has been improved, there is still a big gap between it and the user needs. In order to further improve the capabilities of the human motion generation algorithm, this paper proposes the ReMoDiffuse algorithm (Figure 1) based on MotionDiffuse [1]. By utilizing retrieval strategies, we find highly relevant reference samples and provide fine-grained reference features to generate higher quality action sequences

- ## Paper link: https://arxiv.org/pdf/2304.01116.pdf
- GitHub link: https://github.com/mingyuan-zhang/ReMoDiffuse
- Project homepage: https://mingyuan-zhang.github.io/projects/ReMoDiffuse.html
 Figure 1. Overview of ReMoDiffuse
Figure 1. Overview of ReMoDiffuse
Method introduction
The main process of ReMoDiffuse is divided into two stages: retrieval and diffusion. In the retrieval stage, ReMoDiffuse uses hybrid retrieval technology to retrieve information-rich samples from external multi-modal databases based on user input text and expected action sequence length, providing powerful guidance for action generation. In the diffusion stage, ReMoDiffuse uses the information obtained in the retrieval stage to generate a motion sequence that is semantically consistent with the user input through an efficient model structure. In order to ensure efficient retrieval, ReMoDiffuse carefully designed the following data flow for the retrieval stage (Figure 2): There are three types of data involved in the retrieval process, namely user input text, expected action sequence length, and an external multi-modal database containing multiple pairs. When retrieving the most relevant samples, ReMoDiffuse uses the formula to calculate the similarity between the samples in each database and the user input. The first item here is to calculate the cosine similarity between the user input text and the text of the database entity using the text encoder of the pre-trained CLIP [2] model, and the second item calculates the difference between the expected action sequence length and the action sequence length of the database entity. The relative difference is taken as the kinematic similarity. After calculating the similarity score, ReMoDiffuse selects the top k samples with similar similarity as the retrieved samples, and extracts the text feature  and action feature
and action feature  . These two, together with the features extracted from the text input by the user, are used as input signals to the diffusion stage to guide action generation.
. These two, together with the features extracted from the text input by the user, are used as input signals to the diffusion stage to guide action generation. 

The diffusion process (Figure 3.c) consists of two parts: the forward process and the reverse process. In the forward process, ReMoDiffuse gradually adds Gaussian noise to the original motion data and finally converts it into random noise. The inverse process focuses on removing noise and generating realistic motion samples. Starting from a random Gaussian noise, ReMoDiffuse uses a Semantic Modulation Module (SMT) (Figure 3.a) at each step of the inverse process to estimate the true distribution and gradually remove the noise based on the conditional signal. The SMA module in SMT here will integrate all condition information into the generated sequence features, which is the core module proposed in this article #For the SMA layer (Figure 3.b), we use the efficient attention mechanism (Efficient Attention) [3] to Accelerates the calculation of the attention module and creates a global feature map that emphasizes global information more. This feature map provides more comprehensive semantic clues for action sequences, thereby improving the performance of the model. The core goal of the SMA layer is to optimize the generation of action sequences 1. The Q vector specifically represents the expected action sequence 2.K vector as an indexing mechanism comprehensively considers multiple factors, including current action sequence features 3.V vectors provide the actual features needed to generate actions. Similar to the K vector, the V vector takes into account the retrieval sample, user input, and the current action sequence. Since there is no direct correlation between the text description feature of the retrieved sample and the generated action, we choose not to use this feature when calculating the V vector to avoid unnecessary information interference Combined with the global attention template mechanism of Efficient Attention, the SMA layer uses the auxiliary information from the retrieval sample, the semantic information of the user text, and the feature information of the sequence to be denoised to establish a series of comprehensive global templates, making all conditions The information can be fully absorbed by the sequence to be generated. In order to rewrite the content, the original text needs to be converted into Chinese. Here’s what it looks like after rewriting:
Research Design and Experimental Results We evaluated ReMoDiffuse on two datasets, HumanML3D [4] and KIT-ML [5]. The experimental results (Tables 1 and 2) demonstrate the powerful performance and advantages of our proposed ReMoDiffuse framework from the perspectives of text consistency and action quality Citation Mingyuan Zhang, Cai Zhonggang, Pan Liang, Hong Fangzhou, Guo Xinying, Yang Lei, and Liu Ziwei. Motiondiffuse: Text-driven human motion generation based on diffusion models. arXiv preprint arXiv:2208.15001, 2022 [2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021. [4 ] Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5152 –5161, 2022. What needs to be rewritten is: [5] Matthias Plappert, Christian Mandery and Tamim Asfour. "Motor Language Dataset". Big Data, 4(4):236-252, 2016 [6] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano . Human motion diffusion model. In The Eleventh International Conference on Learning Representations, 2022. Figure 2: Retrieval phase of ReMoDiffuse
Figure 2: Retrieval phase of ReMoDiffuse Fig. 3: Diffusion stage of ReMoDiffuse
Fig. 3: Diffusion stage of ReMoDiffuse by aggregating conditional information. Under this framework:
by aggregating conditional information. Under this framework:  that we expect to generate based on conditional information. , semantic features input by the user
that we expect to generate based on conditional information. , semantic features input by the user , and features obtained from retrieval samples
, and features obtained from retrieval samples and
and . Among them, represents the action sequence features obtained from the retrieval sample, and represents the text description feature obtained from the retrieval sample. This comprehensive construction method ensures the effectiveness of K vectors in the indexing process.
. Among them, represents the action sequence features obtained from the retrieval sample, and represents the text description feature obtained from the retrieval sample. This comprehensive construction method ensures the effectiveness of K vectors in the indexing process.  Table 1. Performance of different methods on the HumanML3D test set
Table 1. Performance of different methods on the HumanML3D test set ##Table 2. Different Method performance on the KIT-ML test set
##Table 2. Different Method performance on the KIT-ML test set Figure 4. Action sequence generated by ReMoDiffuse Comparison with action sequences generated by other methods
Figure 4. Action sequence generated by ReMoDiffuse Comparison with action sequences generated by other methods Figure 5: Distribution of user survey results
Figure 5: Distribution of user survey results
The above is the detailed content of ICCV 2023 | ReMoDiffuse, a new paradigm that reshapes human action generation and integrates diffusion models and retrieval strategies, is here. For more information, please follow other related articles on the PHP Chinese website!

 An easy-to-understand explanation of how to create a VBA macro in ChatGPT!May 14, 2025 am 02:40 AM
An easy-to-understand explanation of how to create a VBA macro in ChatGPT!May 14, 2025 am 02:40 AMFor beginners and those interested in business automation, writing VBA scripts, an extension to Microsoft Office, may find it difficult. However, ChatGPT makes it easy to streamline and automate business processes. This article explains in an easy-to-understand manner how to develop VBA scripts using ChatGPT. We will introduce in detail specific examples, from the basics of VBA to script implementation using ChatGPT integration, testing and debugging, and benefits and points to note. With the aim of improving programming skills and improving business efficiency,
 I can't use the ChatGPT plugin function! Explaining what to do in case of an errorMay 14, 2025 am 01:56 AM
I can't use the ChatGPT plugin function! Explaining what to do in case of an errorMay 14, 2025 am 01:56 AMChatGPT plugin cannot be used? This guide will help you solve your problem! Have you ever encountered a situation where the ChatGPT plugin is unavailable or suddenly fails? The ChatGPT plugin is a powerful tool to enhance the user experience, but sometimes it can fail. This article will analyze in detail the reasons why the ChatGPT plug-in cannot work properly and provide corresponding solutions. From user setup checks to server troubleshooting, we cover a variety of troubleshooting solutions to help you efficiently use plug-ins to complete daily tasks. OpenAI Deep Research, the latest AI agent released by OpenAI. For details, please click ⬇️ [ChatGPT] OpenAI Deep Research Detailed explanation:
 Does ChatGPT not follow the character count specification? A thorough explanation of how to deal with this!May 14, 2025 am 01:54 AM
Does ChatGPT not follow the character count specification? A thorough explanation of how to deal with this!May 14, 2025 am 01:54 AMWhen writing a sentence using ChatGPT, there are times when you want to specify the number of characters. However, it is difficult to accurately predict the length of sentences generated by AI, and it is not easy to match the specified number of characters. In this article, we will explain how to create a sentence with the number of characters in ChatGPT. We will introduce effective prompt writing, techniques for getting answers that suit your purpose, and teach you tips for dealing with character limits. In addition, we will explain why ChatGPT is not good at specifying the number of characters and how it works, as well as points to be careful about and countermeasures. This article
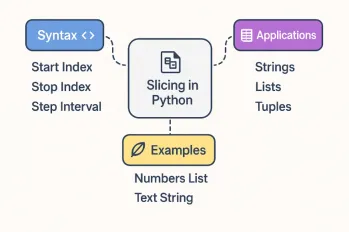 All About Slicing Operations in PythonMay 14, 2025 am 01:48 AM
All About Slicing Operations in PythonMay 14, 2025 am 01:48 AMFor every Python programmer, whether in the domain of data science and machine learning or software development, Python slicing operations are one of the most efficient, versatile, and powerful operations. Python slicing syntax a
 An easy-to-understand explanation of how to use ChatGPT to create quotes!May 14, 2025 am 01:44 AM
An easy-to-understand explanation of how to use ChatGPT to create quotes!May 14, 2025 am 01:44 AMThe evolution of AI technology has accelerated business efficiency. What's particularly attracting attention is the creation of estimates using AI. OpenAI's AI assistant, ChatGPT, contributes to improving the estimate creation process and improving accuracy. This article explains how to create a quote using ChatGPT. We will introduce efficiency improvements through collaboration with Excel VBA, specific examples of application to system development projects, benefits of AI implementation, and future prospects. Learn how to improve operational efficiency and productivity with ChatGPT. Op
 What is ChatGPT Pro (o1 Pro)? Explaining what you can do, the prices, and the differences between them from other plans!May 14, 2025 am 01:40 AM
What is ChatGPT Pro (o1 Pro)? Explaining what you can do, the prices, and the differences between them from other plans!May 14, 2025 am 01:40 AMOpenAI's latest subscription plan, ChatGPT Pro, provides advanced AI problem resolution! In December 2024, OpenAI announced its top-of-the-line plan, the ChatGPT Pro, which costs $200 a month. In this article, we will explain its features, particularly the performance of the "o1 pro mode" and new initiatives from OpenAI. This is a must-read for researchers, engineers, and professionals aiming to utilize advanced AI. ChatGPT Pro: Unleash advanced AI power ChatGPT Pro is the latest and most advanced product from OpenAI.
 We explain how to create and correct your motivation for applying using ChatGPT! Also introduce the promptMay 14, 2025 am 01:29 AM
We explain how to create and correct your motivation for applying using ChatGPT! Also introduce the promptMay 14, 2025 am 01:29 AMIt is well known that the importance of motivation for applying when looking for a job is well known, but I'm sure there are many job seekers who struggle to create it. In this article, we will introduce effective ways to create a motivation statement using the latest AI technology, ChatGPT. We will carefully explain the specific steps to complete your motivation, including the importance of self-analysis and corporate research, points to note when using AI, and how to match your experience and skills with company needs. Through this article, learn the skills to create compelling motivation and aim for successful job hunting! OpenAI's latest AI agent, "Open
 What's so amazing about ChatGPT? A thorough explanation of its features and strengths!May 14, 2025 am 01:26 AM
What's so amazing about ChatGPT? A thorough explanation of its features and strengths!May 14, 2025 am 01:26 AMChatGPT: Amazing Natural Language Processing AI and how to use it ChatGPT is an innovative natural language processing AI model developed by OpenAI. It is attracting attention around the world as an advanced tool that enables natural dialogue with humans and can be used in a variety of fields. Its excellent language comprehension, vast knowledge, learning ability and flexible operability have the potential to transform our lives and businesses. In this article, we will explain the main features of ChatGPT and specific examples of use, and explore the possibilities for the future that AI will unlock. Unraveling the possibilities and appeal of ChatGPT, and enjoying life and business


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SublimeText3 Chinese version
Chinese version, very easy to use

WebStorm Mac version
Useful JavaScript development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver Mac version
Visual web development tools

